绝对干货!初学者也能看懂的DPDK解析( 二 )
UIO原理: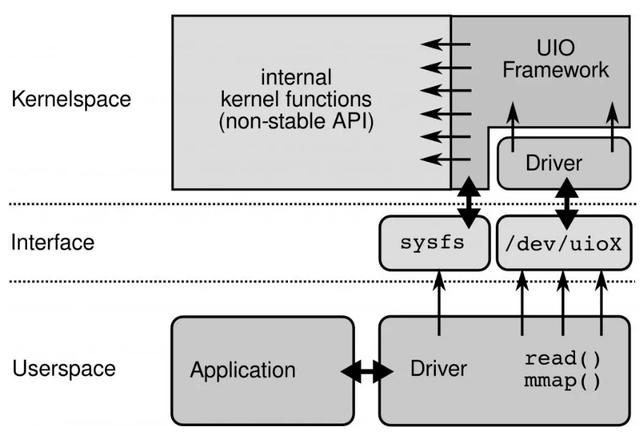 文章插图
文章插图
要开发用户态驱动有几个步骤:
1.开发运行在内核的UIO模块 , 因为硬中断只能在内核处理
2.通过/dev/uioX读取中断
3.通过mmap和外设共享内存
五、DPDK核心优化:PMD
DPDK的UIO驱动屏蔽了硬件发出中断 , 然后在用户态采用主动轮询的方式 , 这种模式被称为PMD(Poll Mode Driver) 。
UIO旁路了内核 , 主动轮询去掉硬中断 , DPDK从而可以在用户态做收发包处理 。 带来Zero Copy、无系统调用的好处 , 同步处理减少上下文切换带来的Cache Miss 。
运行在PMD的Core会处于用户态CPU100%的状态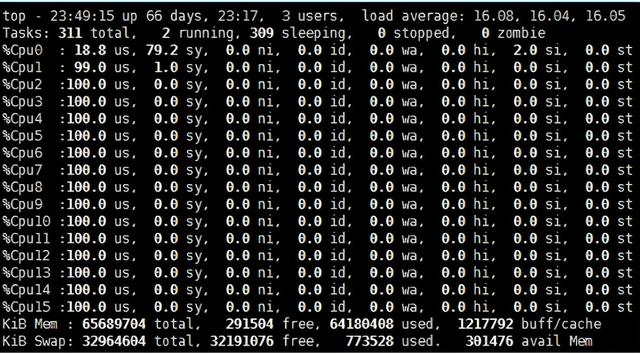 文章插图
文章插图
网络空闲时CPU长期空转 , 会带来能耗问题 。 所以 , DPDK推出Interrupt DPDK模式 。
Interrupt DPDK: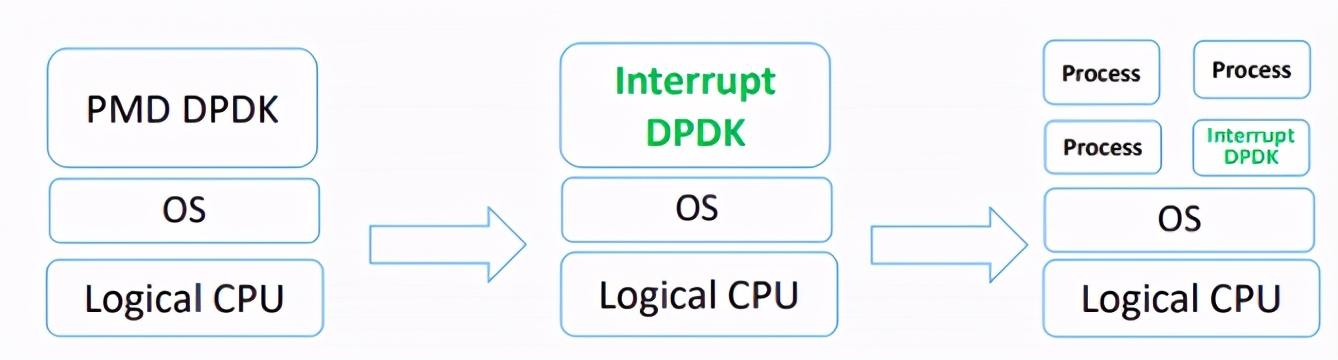 文章插图
文章插图
它的原理和NAPI很像 , 就是没包可处理时进入睡眠 , 改为中断通知 。 并且可以和其他进程共享同个CPU Core , 但是DPDK进程会有更高调度优先级 。
六、DPDK的高性能代码实现
1. 采用HugePage减少TLB Miss
默认下Linux采用4KB为一页 , 页越小内存越大 , 页表的开销越大 , 页表的内存占用也越大 。 CPU有TLB(Translation Lookaside Buffer)成本高所以一般就只能存放几百到上千个页表项 。 如果进程要使用64G内存 , 则64G/4KB=16000000(一千六百万)页 , 每页在页表项中占用16000000 * 4B=62MB 。 如果用HugePage采用2MB作为一页 , 只需64G/2MB=2000 , 数量不在同个级别 。
而DPDK采用HugePage , 在x86-64下支持2MB、1GB的页大小 , 几何级的降低了页表项的大小 , 从而减少TLB-Miss 。 并提供了内存池(Mempool)、MBuf、无锁环(Ring)、Bitmap等基础库 。 根据我们的实践 , 在数据平面(Data Plane)频繁的内存分配释放 , 必须使用内存池 , 不能直接使用rte_malloc , DPDK的内存分配实现非常简陋 , 不如ptmalloc 。
2. SNA(Shared-nothing Architecture)
软件架构去中心化 , 尽量避免全局共享 , 带来全局竞争 , 失去横向扩展的能力 。 NUMA体系下不跨Node远程使用内存 。
3. SIMD(Single Instruction Multiple Data)
从最早的mmx/sse到最新的avx2 , SIMD的能力一直在增强 。 DPDK采用批量同时处理多个包 , 再用向量编程 , 一个周期内对所有包进行处理 。 比如 , memcpy就使用SIMD来提高速度 。
SIMD在游戏后台比较常见 , 但是其他业务如果有类似批量处理的场景 , 要提高性能 , 也可看看能否满足 。
4. 不使用慢速API
这里需要重新定义一下慢速API , 比如说gettimeofday , 虽然在64位下通过vDSO已经不需要陷入内核态 , 只是一个纯内存访问 , 每秒也能达到几千万的级别 。 但是 , 不要忘记了我们在10GE下 , 每秒的处理能力就要达到几千万 。 所以即使是gettimeofday也属于慢速API 。 DPDK提供Cycles接口 , 例如rte_get_tsc_cycles接口 , 基于HPET或TSC实现 。
【绝对干货!初学者也能看懂的DPDK解析】在x86-64下使用RDTSC指令 , 直接从寄存器读取 , 需要输入2个参数 , 比较常见的实现:
static inline uint64_trte_rdtsc(void){uint32_t lo, hi;__asm__ __volatile__ ("rdtsc" : "=a"(lo), "=d"(hi));return ((unsigned long long)lo) | (((unsigned long long)hi) << 32);}这么写逻辑没错 , 但是还不够极致 , 还涉及到2次位运算才能得到结果 , 我们看看DPDK是怎么实现:
static inline uint64_trte_rdtsc(void){ union {uint64_t tsc_64;struct {uint32_t lo_32;uint32_t hi_32;}; } tsc; asm volatile("rdtsc" :"=a" (tsc.lo_32),"=d" (tsc.hi_32)); return tsc.tsc_64;}巧妙的利用C的union共享内存 , 直接赋值 , 减少了不必要的运算 。 但是使用tsc有些问题需要面对和解决
- CPU亲和性 , 解决多核跳动不精确的问题
- 内存屏障 , 解决乱序执行不精确的问题
- 禁止降频和禁止Intel Turbo Boost , 固定CPU频率 , 解决频率变化带来的失准问题
分支预测
现代CPU通过pipeline、superscalar提高并行处理能力 , 为了进一步发挥并行能力会做分支预测 , 提升CPU的并行能力 。 遇到分支时判断可能进入哪个分支 , 提前处理该分支的代码 , 预先做指令读取编码读取寄存器等 , 预测失败则预处理全部丢弃 。 我们开发业务有时候会非常清楚这个分支是true还是false , 那就可以通过人工干预生成更紧凑的代码提示CPU分支预测成功率 。
- AI芯片“点燃”北京!GTIC 2020 AI芯片创新峰会大咖演讲全干货
- 二叉树:搜索树的最小绝对差
- 小店|抖音小店无货源模式,干货来了,抖音小店店群怎么做?
- GPU|干货|基于 CPU 的深度学习推理部署优化实践
- 干货:阿里巴巴提升组织能力的5大经典管理工具
- 搞定2020年路由器选购,家庭组网干货攻略
- 换机|年底换机热潮如何选?这六款旗舰手机绝对有一款是你的菜
- 30款万年笔的推荐人气排名男性/女性/初学者/ 2020
- 互联网创业思维:什么是真正的干货?你是怎么给“干货”下定义的
- 更新|微信再次迎来创新,这4点新功能很实用,绝对值得你的关注