Spring的反应式编程简介
为什么要进行反应式编程?
反应式编程已经存在了一段时间 , 但在最近几年中引起了部分人极大的兴趣 。 大多原因都是:传统的命令式编程在满足当今的需求时存在一些局限性 , 在当今的应用程序中 , 应用程序需要具有高可用性 , 并且在高负载期间也需要低响应时间 。
每个请求模型的线程
为了了解什么是反应式编程及其带来的好处 , 让我们首先考虑使用Spring开发Web应用程序的传统方法-使用Spring MVC并将其部署在Servlet容器(例如Tomcat)上 。
Servlet容器有一个专用的线程池来处理HTTP请求 , 每个传入请求将分配一个线程 , 并且该线程将处理HTTP请求的整个生命周期(“每个请求模型的线程”) 。 这意味着应用程序将只能处理与线程池大小相等的并发请求数 。 可以配置线程池的大小 , 但是由于每个线程都保留一些内存(通常为1MB) , 因此我们配置的线程池大小越大 , 内存消耗就越大 。
如果应用程序是根据基于微服务的体系结构设计的 , 则我们有更好的根据负载进行扩展的可能性 , 但是高内存利用率仍然要付出代价 。 因此 , 对于具有大量并发请求的应用程序 , 每个请求模型的线程可能会变得非常奢侈 。
基于微服务的体系结构的一个重要特征是应用程序是作为大量独立进程运行的 , 通常跨多个服务器运行 。 将传统的命令式编程与服务请求之间的同步请求/响应调用一起使用 , 意味着线程经常被阻塞 , 以等待其他服务的响应 。 这导致资源的巨大浪费 。
等待I / O操作在等待其他类型的I / O操作(例如数据库调用或文件读取)完成时 , 也会发生相同类型的浪费 。 在所有这些情况下 , 发出I / O请求的线程将被阻塞并等待空闲 , 直到I / O操作完成为止 , 这称为阻塞I / O 。 在这种情况下 , 正在执行的线程被阻塞 , 仅在等待响应时 , 这意味着浪费线程 , 因此也浪费了内存 。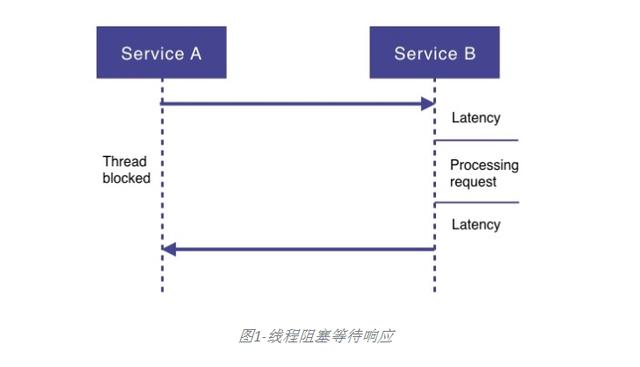 文章插图
文章插图
图1-线程阻塞等待响应
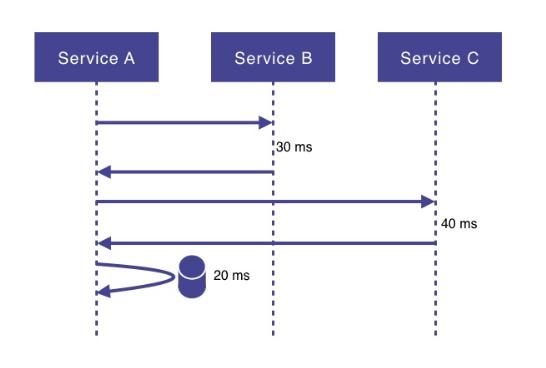
响应时间传统命令式编程的另一个问题是服务需要执行多个I / O请求时的响应时间 。 例如 , 服务A可能需要调用服务B和C , 并进行数据库查找 , 然后返回一些聚合数据 。 这意味着服务A的响应时间除自身的处理时间外 , 还应为:
- 服务B的响应时间(网络延迟+处理) 。
- 服务C的响应时间(网络延迟+处理) 。
- 数据库请求的响应时间(网络延迟+处理) 。
 文章插图
文章插图图2-按顺序执行的调用
如果没有实际逻辑上的理由依次执行这些调用 , 那么如果并行执行这些调用 , 肯定会对服务A的响应时间产生非常积极的影响 。 即使支持使用CompletableFutures在Java中进行异步调用并注册回调 , 也可以在应用程序中广泛使用这种方法 , 这会使代码更加复杂 , 并且难以阅读和维护 。
在微服务领域中可能发生的另一种类型的问题是 , 当服务A向服务B请求某些信息时 , 例如上个月的所有订单 。 如果订单量很大 , 服务A一次检索所有这些信息可能会成为问题 。 服务A可能会被大量数据淹没 , 并可能导致内存不足错误等等原因 。
总结上面描述的不同问题是反应式编程要解决的问题 。
简而言之 , 响应式编程的优点是:
- 每个请求模型都远离线程 , 并且可以以较少的线程数处理更多请求
- 防止线程在等待I / O操作完成时阻塞
- 轻松进行并行调用
- 使客户端可以通知服务器它可以处理多少负载
Spring文档中使用的反应式编程的简短定义如下:
“简单地说 , 反应式编程是关于非阻塞应用程序 , 它们是异步的和事件驱动的 , 并且需要少量的线程来扩展 。 该定义的关键方面是背压的概念 , 它是一种确保生产者不会产生压力的机制 。 压倒了消费者 。 ”
说明
那么如何实现所有这些呢?
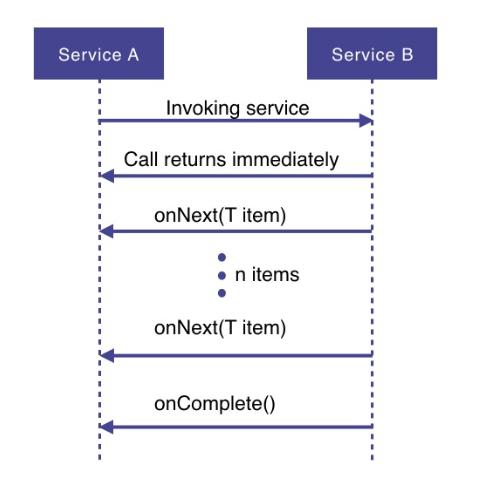
简而言之:通过使用异步数据流进行编程 。 假设服务A要从服务B中检索一些数据 。 使用反应式编程方式 , 服务A将向服务B发出请求 , 服务B立即返回(非阻塞且异步) 。
然后 , 请求的数据将作为数据流提供给服务A , 其中服务B将为每个数据项一个接一个地发布onNext事件 。 发布所有数据后 , 将通过onComplete事件发出信号 。 如果发生错误 , 将发布onError事件 , 并且不再发射任何项目 。
 文章插图
文章插图
- 智能手机市场|华为再拿第一!27%的份额领跑全行业,苹果8%排在第四名!
- 会员|美容院使用会员管理软件给顾客更好的消费体验!
- 行业|现在行业内客服托管费用是怎么算的
- 人民币|天猫国际新增“服务大类”,知舟集团提醒入驻这些类目的要注意
- 国外|坐拥77件专利,打破国外的垄断,造出中国最先进的家电芯片
- 技术|做“视频”绿厂是专业的,这项技术获人民日报评论点赞
- 面临|“熟悉的陌生人”不该被边缘化
- 中国|浅谈5G移动通信技术的前世和今生
- 页面|如何简单、快速制作流程图?上班族的画图技巧get
- 桌面|日常使用的软件及网站分享 篇一:几个动态壁纸软件和静态壁纸网站:助你美化你的桌面