使用Keras构建具有自定义结构和层次的图卷积神经网络(GCNN)
 文章插图
文章插图
如何构建具有自定义结构和层次的神经网络:Keras中的图卷积神经网络(GCNN) 。
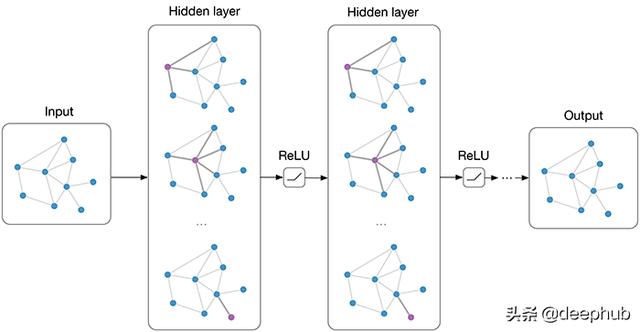
在生活中的某个时刻我们会发现 , 在Tensorflow Keras中预先定义的层已经不够了!我们想要更多的层!我们想要建立一个具有创造性结构的自定义神经网络!幸运的是 , 通过定义自定义层和模型 , 我们可以在Keras中轻松地执行此任务 。 在这个循序渐进的教程中 , 我们将构建一个包含并行层的神经网络 , 其中包括一个图卷积层 。 那么什么是图上的卷积呢?
图卷积神经网络在传统的神经网络层中 , 我们在层输入矩阵X和可训练权值矩阵w之间进行矩阵乘法 , 然后应用激活函数f 。 因此 , 下一层的输入(当前层的输出)可以表示为f(XW) 。 在图卷积神经网络中 , 我们假设把相似的实例在图中连接起来(如引文网络、基于距离的网络等) , 并且我们还假设来自相邻节点的特征在监督任务中可能有用 。 假设A是图的邻接矩阵 , 那么我们要在卷积层中执行的操作就是f(AXW) 。 对于图中的每个节点 , 我们将从其他相连节点聚合特征 , 然后将这个聚合特征乘以权重矩阵 , 然后将其激活 。 图卷积的这个公式是最简单的 。 对于我们的教程来说 , 这很好 , 但是graphCNN更棒!
好的!现在 , 我们准备开始了!
步骤1.准备工作首先 , 我们需要导入一些包 。
#Import packagesfrom tensorflow import __version__ as tf_version, float32 as tf_float32, Variablefrom tensorflow.keras import Sequential, Modelfrom tensorflow.keras.backend import variable, dot as k_dot, sigmoid, relufrom tensorflow.keras.layers import Dense, Input, Concatenate, Layerfrom tensorflow.keras.losses import SparseCategoricalCrossentropyfrom tensorflow.keras.utils import plot_modelfrom tensorflow.random import set_seed as tf_set_seedfrom numpy import __version__ as np_version, unique, array, mean, argmaxfrom numpy.random import seed as np_seed, choicefrom pandas import __version__ as pd_version, read_csv, DataFrame, concatfrom sklearn import __version__ as sk_versionfrom sklearn.preprocessing import normalizeprint("tensorflow version:", tf_version)print("numpy version:", np_version)print("pandas version:", pd_version)print("scikit-learn version:", sk_version)你应该把接收到的导入包版本作为输出 。 在我的例子中 , 输出是:
tensorflow version: 2.2.0 numpy version: 1.18.5 pandas version: 1.0.4 scikit-learn version: 0.22.2.post1在本教程中 , 我们将使用CORA数据集:
Cora数据集由2708份科学出版物组成 , 这些出版物被分为七个类别 。 引文网络由5429个链接组成 。 数据集中的每个发布都由值为0/1的词向量描述 , 该词向量表示字典中对应词的出现或消失 。 这部词典由1433个独特的单词组成 。
让我们加载数据 , 创建邻接矩阵 , 把特征矩阵准备好 。
# Load cora datadtf_data = http://kandian.youth.cn/index/read_csv("").sort_values(["paper_id"], ascending=True)dtf_graph = read_csv("")# Adjacency matrixarray_papers_id = unique(dtf_data["paper_id"])dtf_graph["connection"] = 1dtf_graph_tmp = DataFrame({"cited_paper_id": array_papers_id, "citing_paper_id": array_papers_id, "connection": 0})dtf_graph = concat((dtf_graph, dtf_graph_tmp)).sort_values(["cited_paper_id", "citing_paper_id"], ascending=True)dtf_graph = dtf_graph.pivot_table(index="cited_paper_id", columns="citing_paper_id", values="connection", fill_value=http://kandian.youth.cn/index/0).reset_index(drop=True)A = array(dtf_graph)A = normalize(A, norm='l1', axis=1)A = variable(A, dtype=tf_float32)# Feature matrixdata = http://kandian.youth.cn/index/array(dtf_data.iloc[:, 1:1434])# Labelslabels = array(dtf_data["label"].map({'Case_Based': 0,'Genetic_Algorithms': 1,'Neural_Networks': 2,'Probabilistic_Methods': 3,'Reinforcement_Learning': 4,'Rule_Learning': 5,'Theory': 6}))# Check dimensionsprint("Features matrix dimension:", data.shape, "| Label array dimension:", labels.shape, "| Adjacency matrix dimension:", A.shape)最后 , 我们定义一些对神经网络的训练有用的参数 。
# Training parametersinput_shape = (data.shape[1], )output_classes = len(unique(labels))iterations = 50epochs = 100batch_size = data.shape[0]labeled_portion = 0.10正如你可以从上面的代码中推断出的那样 , 对于每个模型 , 我们将执行50次迭代 , 在每次迭代中 , 我们将随机选择一个标记为10%的集合(训练集) , 并对模型进行100个epoch的训练 。
需要指出的是 , 本教程的范围不是训练CORA数据集上最精确的模型 。 相反 , 我们只是想提供一个使用keras自定义层实现自定义模型的示例!
模型1:序列层的神经网络作为基准 , 我们使用具有序列层的标准神经网络(熟悉的keras序列模型) 。
- 会员|美容院使用会员管理软件给顾客更好的消费体验!
- 桌面|日常使用的软件及网站分享 篇一:几个动态壁纸软件和静态壁纸网站:助你美化你的桌面
- QuestMobile|QuestMobile:百度智能小程序月人均使用个数达9.6个
- 轻松|使用 GIMP 轻松地设置图片透明度
- 电池容量|Windows 自带功能查看笔记本电脑电池使用情况,你的容量还好吗?
- 展开|天地在线联合腾讯广告在京展开“附近推” 构建黄金5公里营销体系
- 重庆市工业互联网技术创新战略联盟:构建万物互联智能工厂 助力先进制造发展
- 撕破脸|使用华为设备就罚款87万,英政府果真要和中国“撕破脸”?
- 框架|三种数据分析思维框架的构建方法
- 冲突|智能互联汽车:通过数据托管模式解决数据使用方面的冲突