与程序员相关的CPU缓存知识( 三 )
 文章插图
文章插图
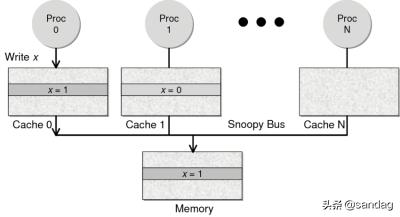
因为Directory协议是一个中心式的 , 会有性能瓶颈 , 而且会增加整体设计的复杂度 。 而Snoopy协议更像是微服务+消息通讯 , 所以 , 现在基本都是使用Snoopy的总线的设计 。
这里 , 我想多写一些细节 , 因为这种微观的东西 , 不自然就就会更分布式系统相关联 , 在分布式系统中我们一般用Paxos/Raft这样的分布式一致性的算法 。 而在CPU的微观世界里 , 则不必使用这样的算法 , 原因是因为CPU的多个核的硬件不必考虑网络会断会延迟的问题 。 所以 , CPU的多核心缓存间的同步的核心就是要管理好数据的状态就好了 。
这里介绍几个状态协议 , 先从最简单的开始 , MESI协议 , 这个协议跟那个著名的足球运动员梅西没什么关系 , 其主要表示缓存数据有四个状态:Modified(已修改), Exclusive(独占的),Shared(共享的) , Invalid(无效的) 。
这些状态的状态机如下所示: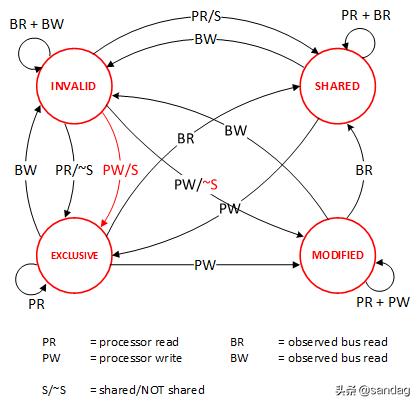 文章插图
文章插图
下面是个示例(如果你想看一下动画演示的话 , 这里有一个网页( MESI Interactive Animations ) , 你可以进行交互操作 , 这个动画演示中使用的Write Through算法):
当前操作CPU0CPU1Memory说明1) CPU0 read(x)x=1 (E)x=1只有一个CPU有 x 变量 , 所以 , 状态是 Exclusive2) CPU1 read(x)x=1 (S)x=1(S)x=1有两个CPU都读取 x 变量 , 所以状态变成 Shared3) CPU0 write(x,9)x= 9 (M)x=1(I)x=1变量改变 , 在CPU0中状态变成 Modified , 在CPU1中状态变成 Invalid4) 变量 x 写回内存x=9 (M)X=1(I)x=9目前的状态不变5) CPU1 read(x)x=9 (S)x=9(S)x=9变量同步到所有的Cache中 , 状态回到Shared
MESI 这种协议在数据更新后 , 会标记其它共享的CPU缓存的数据拷贝为Invalid状态 , 然后当其它CPU再次read的时候 , 就会出现 cache misses 的问题 , 此时再从内存中更新数据 。 可见 , 从内存中更新数据意味着20倍速度的降低 。 我们能不直接从我隔壁的CPU缓存中更新?是的 , 这就可以增加很多速度了 , 但是状态控制也就变麻烦了 。 还需要多来一个状态:Owner(宿主) , 用于标记 , 我是更新数据的源 。 于是 , 现了 MOESI 协议
MOESI协议的状态机和演示我就不贴了 , 我们只需要理解MOESI协议允许 CPU Cache 间同步数据 , 于是也降低了对内存的操作 , 性能是非常大的提升 , 但是控制逻辑也非常复杂 。
顺便说一下 , 与 MOESI 协议类似的一个协议是 MESIF, 其中的 F 是 Forward , 同样是把更新过的数据转发给别的 CPU Cache 但是 , MOESI 中的 Owner 状态 和MESIF 中的 Forward 状态有一个非常大的不一样—— Owner状态下的数据是dirty的 , 还没有写回内存 , Forward状态下的数据是clean的 , 可以丢弃而不用另行通知 。
需要说明的是 , AMD用MOESI , Intel用MESIF 。 所以 , F 状态主要是针对 CPU L3 Cache 设计的(前面我们说过 , L3是所有CPU核心共享的) 。 (相关的比较可以参看 StackOverlow上这个问题的答案 )
程序性能了解了我们上面的这些东西后 , 我们来看一下对于程序的影响 。
示例一首先 , 假设我们有一个64M长的数组 , 设想一下下面的两个循环:
const int LEN = 64*1024*1024;int *arr = new int[LEN];for (int i = 0; i < LEN; i += 2) arr[i] *= i;for (int i = 0; i < LEN; i += 8) arr[i] *= i;按我们的想法来看 , 第二个循环要比第一个循环少4倍的计算量 , 其应该也是要快4倍的 。 但实际跑下来并不是 ,在我的机器上 , 第一个循环需要127毫秒 , 第二个循环则需要121毫秒 , 相差无几。 这里最主要的原因就是 Cache Line , 因为CPU会以一个Cache Line 64Bytes最小时单位加载 , 也就是16个32bits的整型 , 所以 , 无论你步长是2还是8 , 都差不多 。 而后面的乘法其实是不耗CPU时间的 。
示例二我们再来看一个与缓存命中率有关的代码 , 我们以一定的步长 increment 来访问一个连续的数组 。
for (int i = 0; i < 10000000; i++) {for (int j = 0; j < size; j += increment) {memory[j] += j;}}我们测试一下 , 在下表中 ,表头是步长 , 也就是每次跳多少个整数 , 而纵向是这个数组可以跳几次(你可以理解为要几条Cache Line) , 于是表中的任何一项代表了这个数组有多少 , 而且步长是多少 。 比如:横轴是 512 , 纵轴是4 , 意思是 , 这个数组有 4*512 = 2048 个长度 , 访问时按512步长访问 , 也就是访问其中的这几项: [0, 512, 1024, 1536] 这四项 。
表中同的项是 , 是循环1000万次的时间 , 单位是“微秒”(除以1000后是毫秒)
- 创意|wacom one万与创意数位屏测评
- 黑莓(BB.US)盘前涨逾32%,将与亚马逊开发智能汽车数据平台|美股异动 | US
- 巅峰|realme巅峰之作:120Hz+陶瓷机身+5000mAh 做到了颜值与性能并存
- 现状|程序员现状揭秘:平均年薪20.36万,Java人才需求量最大
- 抖音小店|抖音进军电商,短视频的商业模式与变现,创业者该如何抓住机遇?
- YFI正式宣布与Sushiswap合作|金色DeFi日报 | 合作
- 小店|抖音小店无货源是什么?与传统模式有什么区别?
- 星期一|亚马逊:黑五与网络星期一期间 第三方卖家销售额达到48亿美元
- 迁徙|网红迁徙记:哪里才是奶与蜜之地?
- 与用户|掌握好这4个步骤,实现了规模性的盈利