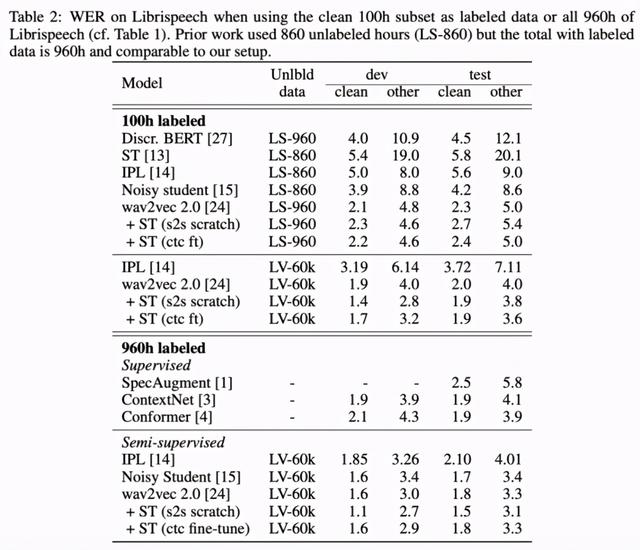
10分钟标注数据胜过一年前960h,FAIR语音识别大进展( 二 )
 文章插图
文章插图
推断时没有语言模型的评估结果
下表 3 展示了 , 在没有语言模型的情况下 , 自训练和预训练的结合仍能取得不错的性能 。 这是因为伪标注过程中使用的语言模型已被部分融入伪标注数据中 。 在没有语言模型的 10 min labeled 设置下这一效应尤其显著:在 test-other 数据集上 , wav2vec 2.0 + ST (s2s scratch) 将基线方法 (wav2vec 2.0 - LM) 的词错率降低了 83% 。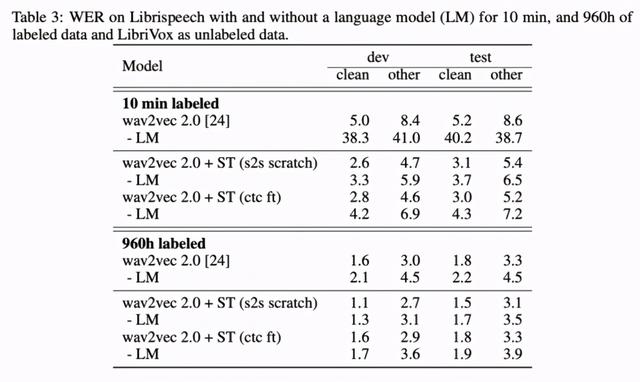 文章插图
文章插图
- 查询|数据太多容易搞混?掌握这几个Excel小技巧,办公思路更清晰
- 黑莓(BB.US)盘前涨逾32%,将与亚马逊开发智能汽车数据平台|美股异动 | US
- 健身房|乐刻韩伟:产业互联网中只做单环节很难让数据发挥大作用
- V2X|V2X:确保未来道路交通数据交换的安全性
- 短视频平台|大数据佐证,抖音带动三千万就业,视频手机将成生产力工具?
- 权属|从数据悖论到权属确认,数据共享进路所在
- 统计|多久才能换一次手机?统计机构数据有点意外
- 发展|大数据解读世界互联网大会·互联网发展论坛!
- 网购|黑色星期五及网购星期一大数据出炉 全球第三方卖家销售额超48亿美元
- Veeam|Veeam让企业数据拥有“第二次生命”