论集群,就服鹅厂
当单体系统扛不住压力时
往往就需要用「集群」来搞定
若要论业内“玩集群”的高手
非鹅厂莫属
↓ 文章插图
文章插图
↓ 文章插图
文章插图
这腾讯玩集群的本事
已经到了出神入化的地步
我们今天就讲讲其中的一个秘密武器
超大规模分布式存储引擎
YottaStore
↓ 文章插图
文章插图
为什么是秘密武器?因为
YottaStore虽“神功盖世” , 却深藏功与名
江湖上少有它的声音
它作为底层存储引擎
默默支撑着大量腾讯自身的业务
更成为腾讯云很多招牌产品的底座
大名鼎鼎的腾讯云COS对象存储
底层就是YottaStore在“发功”
↓ 文章插图
文章插图
YottaStore这个秘密武器
都有哪些强大之处呢?
1、强大在于·真正实现对“超大规模”集群的控制 其实 , 分布式存储不是啥新概念
大家如今都这么玩
但是 , 一旦玩大了
比如集群规模超过百万节点
就玩不动了
↓ 文章插图
文章插图
“玩不动”的核心原因
是它的架构卡了脖子
传统分布式存储 , 通常采用三层架构
↓
传统分布式存储三层架构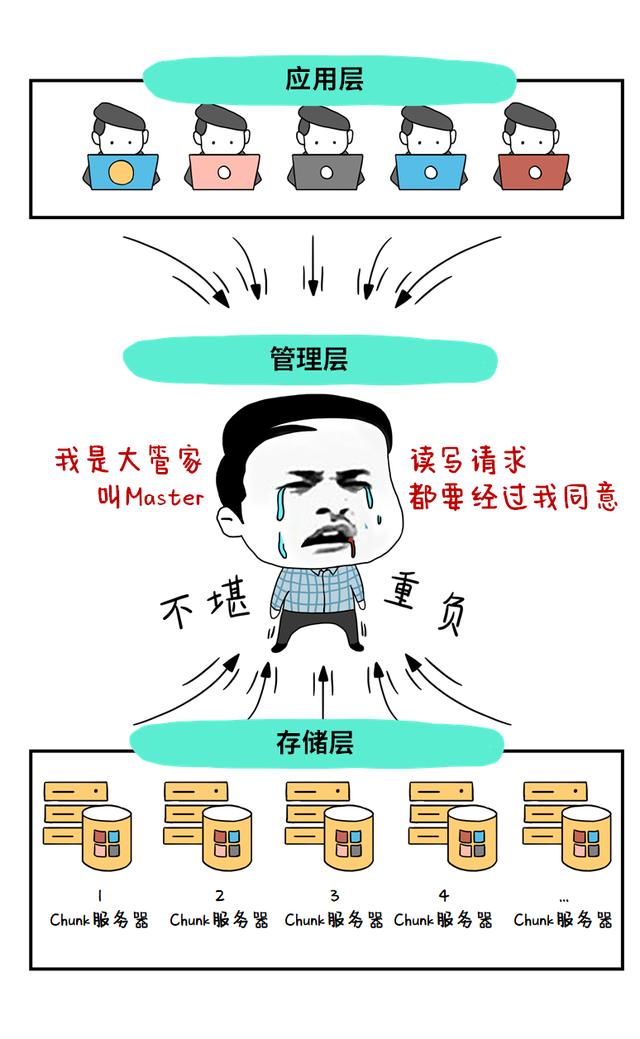 文章插图
文章插图
第一层 , 应用层 , 各种应用、各种数据来源
第二层 , 管理层 , 是Master管理节点
第三层 , 存储层 , 就是一台台存储服务器 , 里面存着数据
这种三层架构
“卡脖子”环节显而易见
就是Master管理节点
作为大管家 , 他管理的存储服务器越多
就越累、越力不从心
Master这么累 , 有三个原因
?
Master单机容量受限
Master里面存着“元数据”
元数据就像是一种电子目录
记录着数据的关键描述信息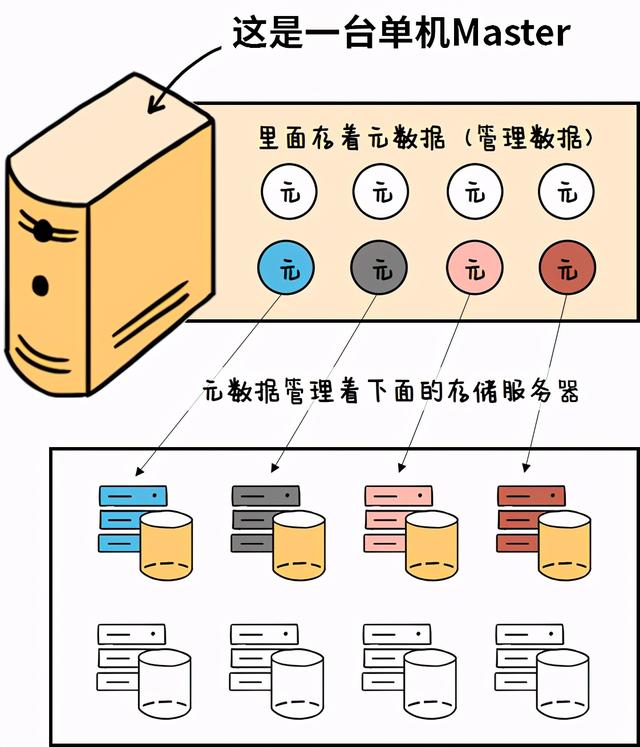 文章插图
文章插图
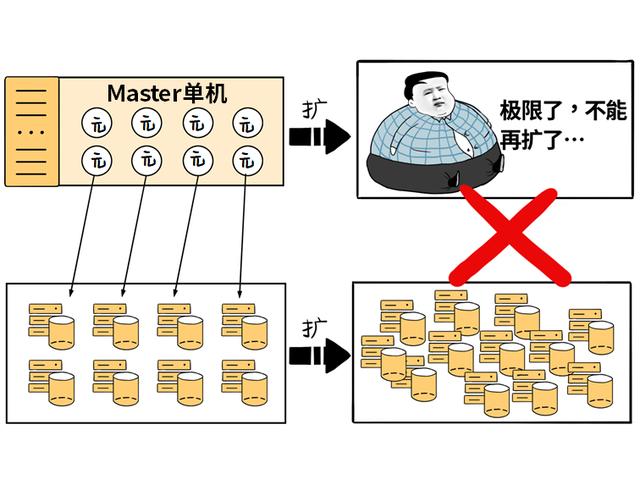
如果下面的服务器集群要迅速扩容
Master里的“元数据”也会跟着极速增加
此时 , 单个Master存储容量受限
扩不了
↓ 文章插图
文章插图
?
Master“读写请求量”过载
数据读写的时候
虽然主要的IO负载由数据节点承担
Master节点也需要被高频访问
如果集群过大 , 读写请求量就过大
就会瞬间打爆单点Master
?
Master日理万机 , 分身乏术
Master的管理任务过于集中而繁重
比如:数据修复、数据均衡、数据巡检...
↓ 文章插图
文章插图
所以 , 传统分布式存储架构
要实现“超大规模”的集群
是件很吃力的事情
那么
YottaStore是如何把集群“搞大”的?
↓ 文章插图
文章插图
YottaStore突破了单点Master的瓶颈
做到单集群可达百万节点的控制
采用分层、分块拆解思路
整个架构变得强大而灵活
↓
YottaStore分了四层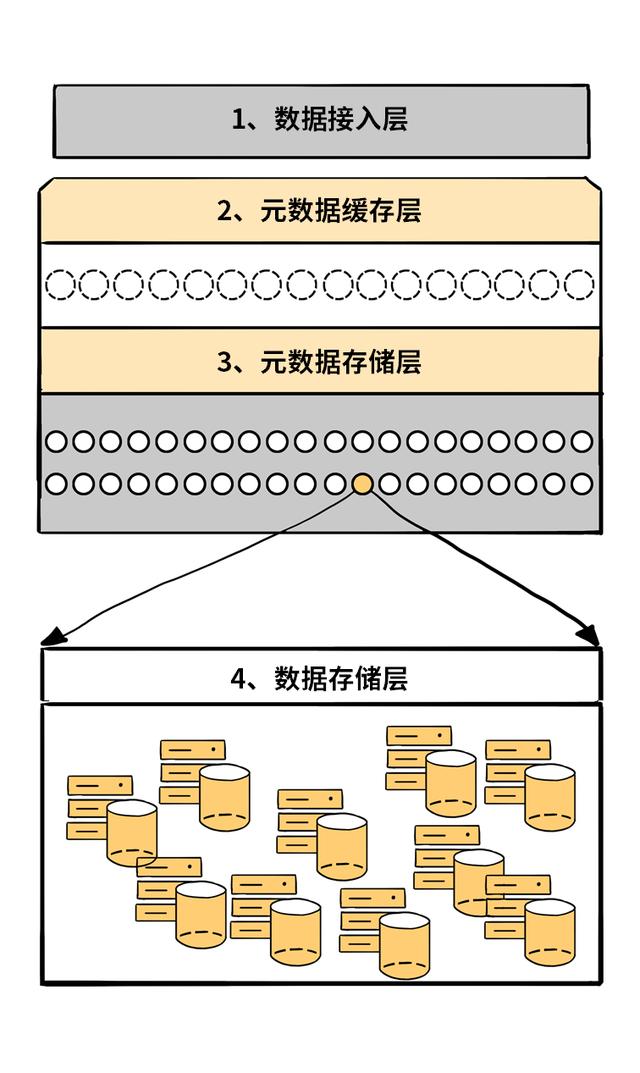 文章插图
文章插图
1. 接入层:负责所有用户请求的接入、路由等工作 。
2. 元数据缓存层:缓存元数据 , 避免元数据存储节点被高QPS打死 。
3. 元数据存储层:存储了系统物理结构以及逻辑映射数据 。
4. 数据存储层:数据存储层保存了用户的真实数据以及它们的冗余 。
分层彻底解放了Master
读写请求都不直接经过元数据节点
解决了“读写请求量过载”的问题
同时
元数据能存得更小 , 管理得更多
1Byte元数据可以管理2GB的物理空间
这就意味着
一台Master , 仅存600G元数据
就能支撑上千万台的机器工作
解决了Master“单机存储容量受限”的问题
这种神操作 , 在业内独树一帜
除了分层外 , 还要分块
↓
YottaStore分了五块
将Master功能 , 拆成一个个的子系统
解决了“Master管事太多、太累”问题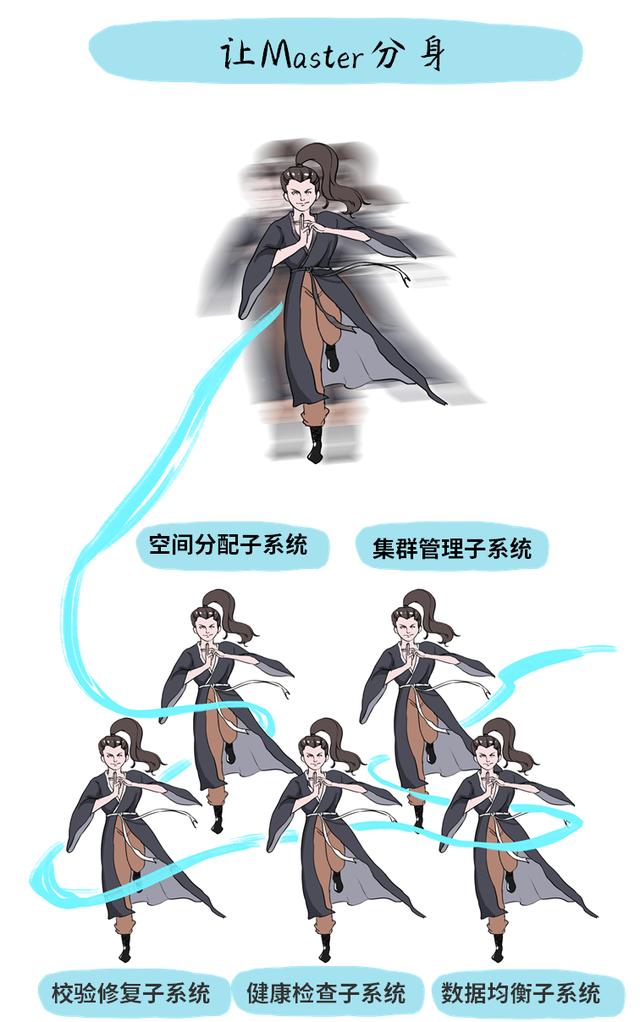 文章插图
文章插图
1. 空间分配子系统:负责数据写入时的空间分配 。
- 技术|做“视频”绿厂是专业的,这项技术获人民日报评论点赞
- 同轴心配合|用SolidWorks画一个直角传动,画四个零件就行
- 敢动|女生最害怕被“偷看”的3软件,QQ不算啥,第二敢动就“翻脸”
- 拍照|iPhone12还没捂热13就曝光了,屏幕、信号、拍照均有升级!
- 短视频平台|大数据佐证,抖音带动三千万就业,视频手机将成生产力工具?
- 权属|从数据悖论到权属确认,数据共享进路所在
- 中国视频|人日评论点赞!OPPO成视频手机先行者,新技术或下月发布
- 基建|深信服何朝曦:离开安全的“新基建”,就是在沙子上盖高楼
- sd|sd卡修复工具有哪些?两个办法就可以搞定了
- 旗舰|手机带“Pro”就一定专业?这两款自拍旗舰来了一场对比