Python爬虫:B站排行榜视频播放量,视频评论量等数据采集
前言本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理 。
以下文章来源于CSND , 作者嗨学编程 文章插图
文章插图
项目背景小Q发现小P每天在B站的时间特别长,他想和小P深入地交流一下B站,可小Q前段时间学业压力很大的,一直没看B站,他想知道现在B站流行什么,那你能帮帮他吗?
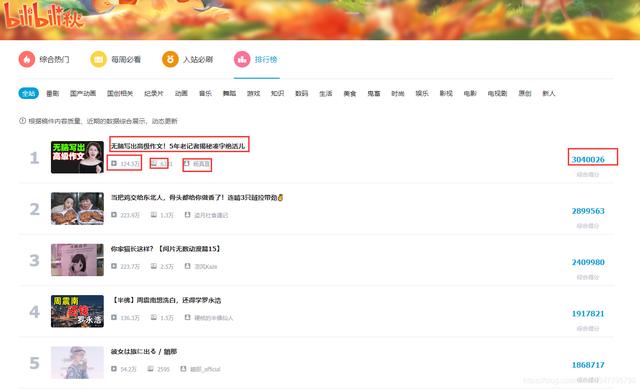
项目目标实现爬取当前B站排行榜的内容(爬取任一榜单即可),要求包括视频排名视频BV号,视频封面 , 视频播放量,视频评论量, up主姓名 文章插图
文章插图
目标网页分析获取数据内容
- 标题
- 播放量
- 弹幕量
- 作者
- 综合得分
- 详情页地址
 文章插图
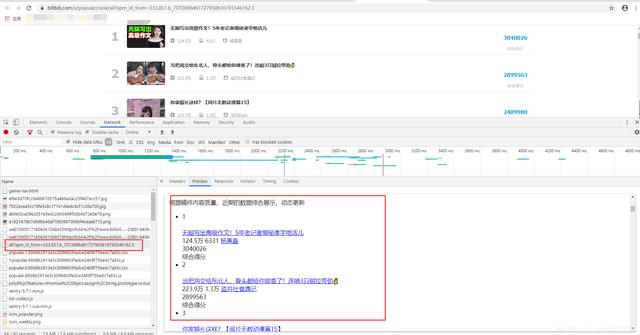
文章插图【Python爬虫:B站排行榜视频播放量,视频评论量等数据采集】开发者工具一看 , 好家伙 , 就这?
 文章插图
文章插图当看到这样的情况 , 是真的不用分析什么了 , 直接就可以从头到尾开始写代码了
直接就是爬虫三部曲走起了 。
1、模拟浏览器请求网站获得网页数据;2、解析网页数据 , 提取想要的内容;3、保存数据
完整代码
import requestsimport parselimport csvf = open('B站排行榜数据.csv', mode='a', encoding='utf-8-sig', newline='')csv_writer = csv.DictWriter(f, fieldnames=['标题', '播放量', '弹幕量', '作者', '综合得分', '视频地址'])csv_writer.writeheader()url = ''headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'}response = requests.get(url=url, headers=headers)selector = parsel.Selector(response.text)lis = selector.css('.rank-list li')dit = {}for li in lis:title = li.css('.info a::text').get()# 标题bf_info = li.css('div.content > div.info > div.detail > span:nth-child(1)::text').get().strip()# 播放量dm_info = li.css('div.content > div.info > div.detail > span:nth-child(2)::text').get().strip()# 弹幕量bq_info = li.css('div.content > div.info > div.detail > a > span::text').get().strip()# 作者score = li.css('.pts div::text').get()# 综合得分page_url = li.css('.img a::attr(href)').get()# 视频地址dit = {'标题': title,'播放量': bf_info,'弹幕量': dm_info,'作者': bq_info,'综合得分': score,'视频地址': page_url,}csv_writer.writerow(dit)print(dit)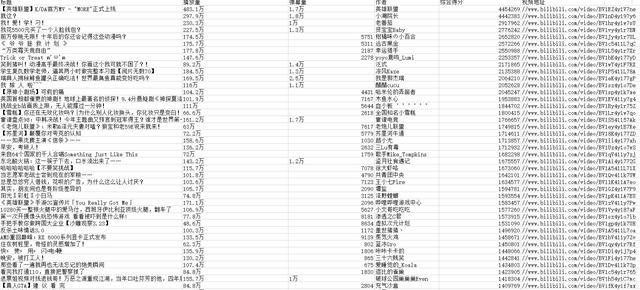 文章插图
文章插图- 桌面|日常使用的软件及网站分享 篇一:几个动态壁纸软件和静态壁纸网站:助你美化你的桌面
- 中国|意大利制造求助中国网站,意外交部长出马见证
- 告人温博特等人|侵犯他人著作权,D站经营者获刑
- 出炉|B站2020年度弹幕出炉!第一名竟然是它?
- 市场|聚焦私域流量电商供应链赋能 纷来电商或站上万亿市场风口
- 爱奇艺|连续亏损十年,爱奇艺收入不及快手,视频网站的出口在哪里?
- 不良|打开“无痕模式”就以为无人知?殊不知,“不良网站”正在利用你
- 真相|看似免费的“不良网站”,背后靠什么赚钱?知道真相你还会看吗?
- 示该站点|虾秘功能大揭秘之订单监测&广告概况
- 反垄断|好日子到头?谷歌等美企将面临美国4起诉讼,30国已站在对立面