DMP商业大数据管理平台架构与实现( 二 )
特征存储:支持随机和批量的高并发读写 , 提供TB级别的特征存储能力 , 同时提供实时特征和历史特征的融合 , 支持多版本的特征迭代 。
特征服务:对外提供统一的访问接口 , 权限控制 , 元数据管理和实验分流 。
5. 元数据管理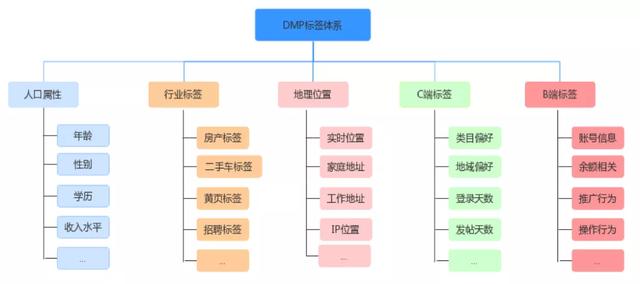 文章插图
文章插图
商业DMP标签体系主要分为C端标签和B端标签两类 。 C端主要是流量相关的标签 , 可以给予人口属性、行业标签、地理位置等做进一步细分 。 B端主要是广告主相关的标签 。
6. 特征挖掘流程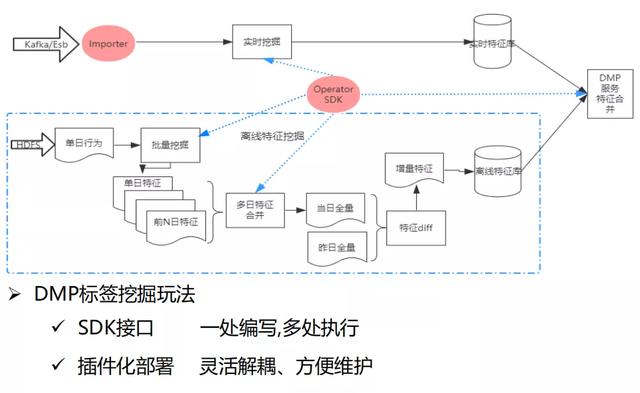 文章插图
文章插图
特征挖掘主要分实时特征挖掘和离线特征挖掘两大块 。 我们提供了Importer(对数据源的解析)和Operator SDK(融合数据挖掘的接口) , 可以对用户提供SDK开放接口 , 达到一处编写 , 多处执行的能力 , 并且支持插件化部署 , 利于服务解耦和维护 。
- 离线特征挖掘的场景是一般基于单日行为的批量挖掘 , 再向前回溯n日的特征 , 然后进行多日特征合并 。 首次进行全量导入特征库 , 后续每日做增量特征导入 , 是通过当日全量与昨日全量做特征diff , 然后得到增量特征在导入特征库 。
- 实时特征挖掘是通过Importer和解析用户挖掘的SDK在写入实时特征库 , 最后在DMP服务会对实时特征库和离线特征库进行合并 , 再对外提供服务 。
 文章插图
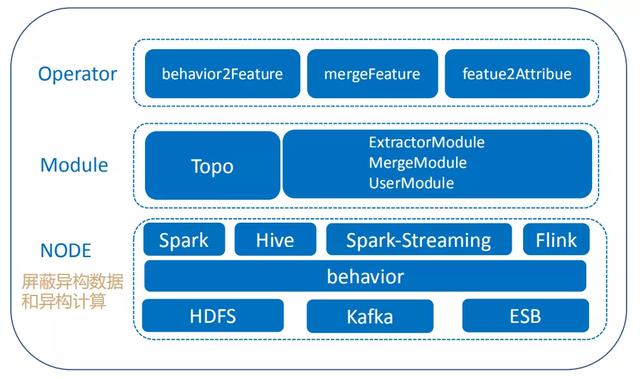
文章插图计算框架大致分NODE、Module和Operator三部分:
- NODE:对用户屏蔽了异构数据和异构计算 。 提供Spark、Hive、SparkStreaming和Flink计算引擎 , 底层数据源支持HDFS、Kafka和ESB , 通过behavior数据结构 , 对58商业流量数据抽象定义 , 从而兼容多种异构数据源 , 提供统一的数据结构 。
- Module:Topo主要是对Operator解析和调用 。
- Operator:对用户暴露了behavior2Feature、mergeFeature和 featue2Attribue三个接口 。 behavior2Feature是对schema数据转换成用户需要的标准化的特征;mergeFeature提供用户自定义的特征融合功能;featue2Attribue是对外提供特征查询的接口服务 。
① 遇到的问题
- 稳定性问题:由于流量洪峰导致的任务处理数据量变大、内存溢出、数据积压等问题;由于任务频繁提交到故障机器导致任务失败问题;由于部分任务执行耗时导致整个任务执行时间过长 , 从而产生数据积压的问题;由于网络shuffle耗时导致任务性能变差;由于Spark和Flink自身的监控不能满足业务需要 , 导致不能及时发现异常问题等 。
- Flink框架问题:分布式缓存不生效、Taskmanager超时失败、Flink框架空指针异常等 。
- 数据流传输问题:flume采集数据传输延迟 , 导致用户行为实时转化不及时 。
- 监控问题:由于监控时间粒度太小导致监控覆盖不全 。
- 稳定性:利用Spark和Flink自带的反压机制解决流量洪峰问题;对于机器故障问题采用黑名单机制和推测执行机制来解决;通过定制化任务监控来及时发问题 。
- 容错性:主要采用Spark和Flink自带的checkpoint机制 。
- 高性能:算子优化、shuffle优化、参数调优等 。
- Flink问题:向Flink社区反馈问题,借助HDFS我们实现了分布式缓存功能 。
- 数据传输:借助公司力量 , 推动Flume传输架构优化升级 。
- 监控:开发自定义监控系统 , 并结合Flink , Spark自带监控 。
 文章插图
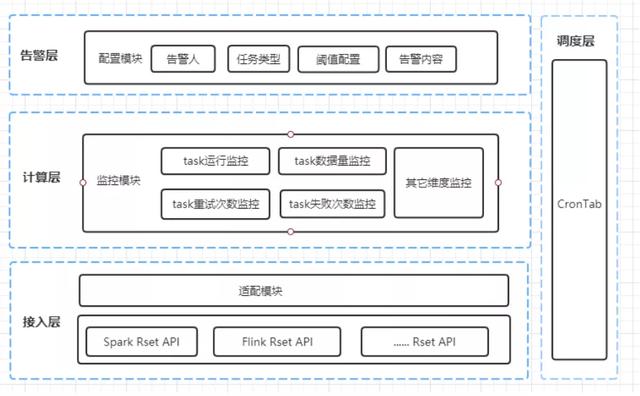
文章插图我们的监控平台主要结合Flink , Spark自带监控进行一个补充 , 主要针对task运行 , 重试次数和失败次数的监控和一些其他维度的监控 , 通过告警层 , 配置告警相关规则 , 将监控的异常信息及时通知告警人并处理 。
9. 存储系统选型
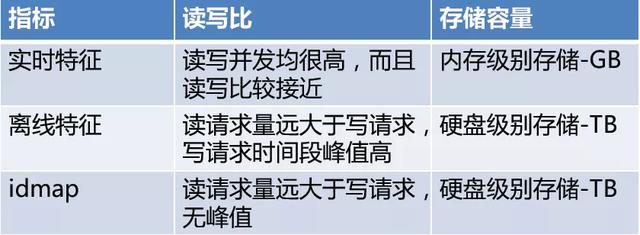 文章插图
文章插图针对上述对比结合58内部以及业界常见KV存储查询 , 我们选择Redis和wtable这两种KV存储系统 。 针对要求高性能高并发读写的场景我们选用redis , 针对并发读性能要求高 , 并发写性能相对较低的场景则选用wtable 。
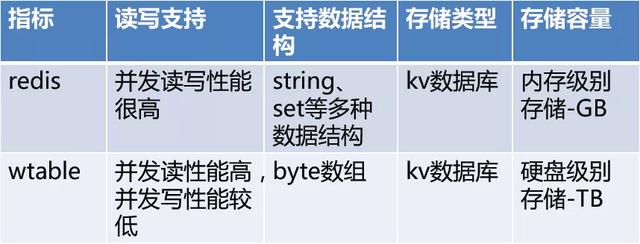 文章插图
文章插图10. 存储优化
① 读写合并优化
由于实时离线特征数据量太大 , 数据库的读写次数几乎等于流量日志的数量 。 我们做了如下优化:
- 培训班|单县残联举办残疾人电子商务培训班
- 产业|前瞻生鲜电商产业全球周报第67期:发力社区团购!京东内部筹划“京东优选”
- 零部件|马瑞利发力电动产品,全球第七大零部件供应商在转型
- 手机基带|为了5G降低4G网速?中国移动回应来了:罪魁祸首不是运营商
- 互联网|苏宁跳出“零售商”重组互联网平台业务 融资60亿只是第一步
- 商品|问道自有品牌,山姆多方博弈
- 培育|跨境电商人才如何培育,长沙有“谱”了
- 出海|出海日报丨短视频生产服务商小影科技完成近4亿元 C 轮融资;华为成为俄罗斯在线出售智能手机的第一品牌
- 抖音小店|抖音进军电商,短视频的商业模式与变现,创业者该如何抓住机遇?
- 用户|5G信号有猫腻,又在考验用户的智商?