这种思路讲解数据仓库建模,你见过吗?数据人与架构师必看
文|傅一平
今天跟着我来学学数据仓库的基础知识 , 希望你结合案例可以把它吃透 。
一、数据仓库建模的意义如果把数据看作图书馆里的书 , 我们希望看到它们在书架上分门别类地放置;如果把数据看作城市的建筑 , 我们希望城市规划布局合理;如果把数据看作电脑文件和文件夹 , 我们希望按照自己的习惯有很好的文件夹组织方式 , 而不是糟糕混乱的桌面 , 经常为找一个文件而不知所措 。
数据模型就是数据组织和存储方法 , 它强调从业务、数据存取和使用角度合理存储数据 。 Linux的创始人Torvalds有一段关于“什么才是优秀程序员”的话:“烂程序员关心的是代码 , 好程序员关心的是数据结构和它们之间的关系” , 最能够说明数据模型的重要性 。
只有数据模型将数据有序的组织和存储起来之后 , 大数据才能得到高性能、低成本、高效率、高质量的使用 。
性能:帮助我们快速查询所需要的数据 , 减少数据的I/O吞吐 , 提高使用数据的效率 , 如宽表 。
成本:极大地减少不必要的数据冗余 , 也能实现计算结果复用 , 极大地降低存储和计算成本 。
效率:在业务或系统发生变化时 , 可以保持稳定或很容易扩展 , 提高数据稳定性和连续性 。
质量:良好的数据模型能改善数据统计口径的不一致性 , 减少数据计算错误的可能性 。
数据模型能够促进业务与技术进行有效沟通 , 形成对主要业务定义和术语的统一认识 , 具有跨部门、中性的特征 , 可以表达和涵盖所有的业务 。
大数据系统需要数据模型方法来帮助更好地组织和存储数据 , 以便在性能、成本、效率和质量之间取得最佳平衡!
下图是个示例 , 通过统一数据模型 , 屏蔽数据源变化对业务的影响 , 保证业务的稳定 , 表述了数据仓库模型的一种价值: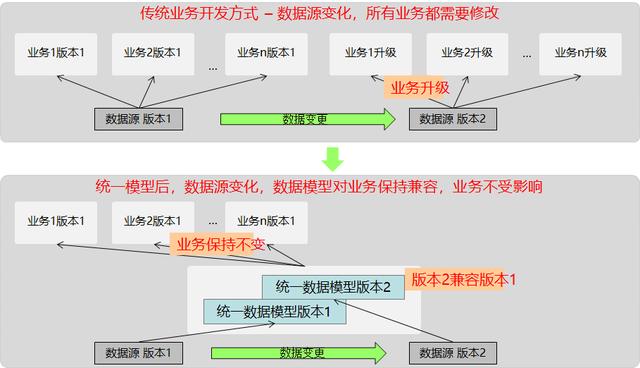 文章插图
文章插图
二、数据仓库分层的设计为了实现以上的目的 , 数据仓库一般要进行分层的设计 , 其能带来五大好处:
清晰数据结构:每一个数据分层都有它的作用域 , 这样我们在使用表的时候能更方便地定位和理解 。
数据血缘追踪:能够快速准确地定位到问题 , 并清楚它的危害范围 。
减少重复开发:规范数据分层 , 开发一些通用的中间层数据 , 能够减少极大的重复计算 。
把复杂问题简单化:将复杂的任务分解成多个步骤来完成 , 每一层只处理单一的步骤 , 比较简单和容易理解 。 当数据出现问题之后 , 不用修复所有的数据 , 只需要从有问题的步骤开始修复 。
屏蔽原始数据的异常:不必改一次业务就需要重新接入数据 。
以下是我们的一种分层设计方法 , 数据缓冲区(ODS)的数据结构与源系统完全一致 。 基础数据模型(DWD)和融合数据模型(DWI与DWA)是大数据平台重点建设的数据模型 。 应用层模型由各应用按需自行建设 , 其中基础数据模型一般采用ER模型 , 融合数据模型采用维度建模思路 。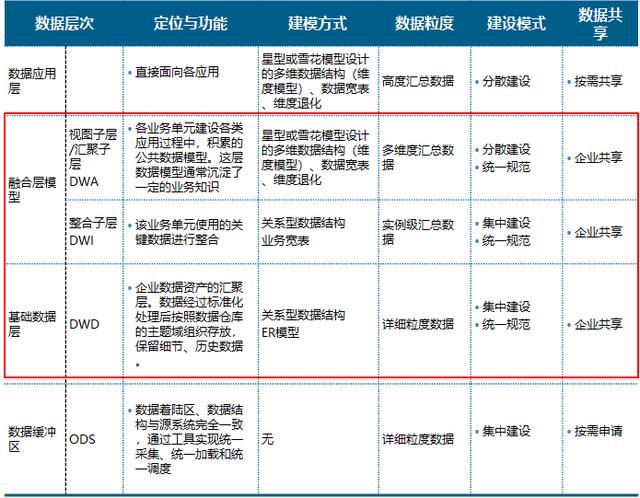 文章插图
文章插图
三、两种经典的数据仓库建模方法前面的分层设计中你会发现有两种设计方法 , 关系建模和维度建模 , 下面分别简单介绍其特点和适用场景 。
1、维度建模
(1)定义
维度模型是数据仓库领域另一位大师Ralph Kimball 所倡导的 。 维度建模以分析决策的需求出发构建模型 , 构建的数据模型为分析需求服务 , 因此它重点解决用户如何更快速完成分析需求 , 同时还有较好的大规模复杂查询的响应性能 , 更直接面向业务 。 典型的代表是我们比较熟知的星形模型 。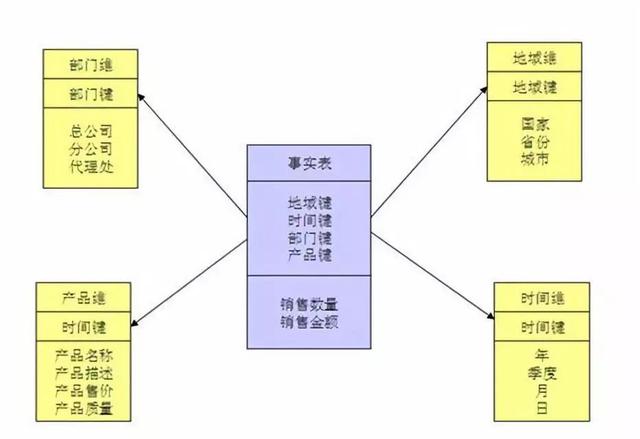 文章插图
文章插图 文章插图
文章插图
维度退化
星型模型由一个事实表和一组维表组成 。 每个维表都有一个维作为主键 , 所有这些维的主键组合成事实表的主键 。 强调的是对维度进行预处理 , 将多个维度集合到一个事实表 , 形成一个宽表 。
这也是我们在使用hive时 , 经常会看到一些大宽表的原因 , 大宽表一般都是事实表 , 包含了维度关联的主键和一些度量信息 , 而维度表则是事实表里面维度的具体信息 , 使用时候一般通过join来组合数据 , 相对来说对OLAP的分析比较方便 。
(2)建模方法
通常需要选择某个业务过程 , 然后围绕该过程建立模型 , 其一般采用自底向上的方法 , 从明确关键业务过程开始 , 再到明确粒度 , 再到明确维度 , 最后明确事实 , 非常简单易懂 。
- 查询|数据太多容易搞混?掌握这几个Excel小技巧,办公思路更清晰
- IT|信服云为IT基础架构演进提供新思路
- 机制|反马赛克机制问世,这种软件应该被禁止吗
- 信服云为IT基础架构演进提供新思路
- 资讯|蔚来、埃安们都能用上特斯拉超充桩?官方:不排除这种可能
- Linux信号透彻分析理解与各种实例讲解
- Python数据分析:Jupyter Notebook 讲解
- 马云手段有多高?支付宝表面上不属于阿里,其实却以这种方式掌权
- 什么是物联网?常见 IoT 物联网协议最全讲解
- 程序员面试题:Leetcode真题讲解,求两数之和