神经网络与随机数的安全性分析(下)( 二 )
x1 = [[0,0,0,1],[0,0,1,0],[0,0,1,1],[0,1,0,0]] #[1,2,3,4]y1 = [0,1,0,1] #5x2 = [[0,0,1,0],[0,0,1,1],[0,1,0,0],[0,1,0,1]] #[2,3,4,5]y2 = [0,1,1,0] #6
在机器学习术语中 , 我们想把这个长度为N的序列分成几个张量:32×4输入张量和32×1输出张量 。 现在 , 我们需要编写一些高性能的numpy代码 , 在多维张量上执行数据重塑操作 。
接下来 , 我们可以使用一个LSTM来捕获基于状态的依赖关系 , 几个密集的网络足以覆盖所有的数据变换操作 , 然后用32位的最终数据层完成我们的任务:
model.add(LSTM(units=1024,activation='relu',input_shape=(4,32,),return_sequences=False,))for depth in range(5):model.add(Dense(512,activation='relu'))model.add(Dense(32))
下面的结果足以证明我们的想法:
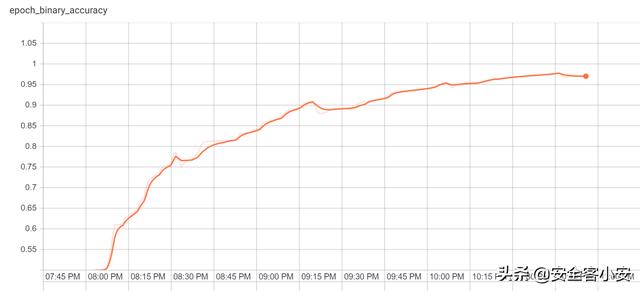 文章插图
文章插图这个模型实际上需要几次才能成功 , 之前的运行达到了75%到95%之间的峰值 。
为此 , 我还专门给大家提供了一个针对Xorshift128算法的预测工具 , 感兴趣的同学可以下载下来使用一下 。 除此之外 , 这实际上是我第一次建立任何类型的新模型 , 所以我希望社区的广大同学们能够帮助我继续完善这款工具的源代码 , 以更好地提升其性能和预测准确率 。
RngPredictor在安装好tensorflow之后 , 然后把该项目的源代码克隆至本地 , 你就可以直接运行predictor.py脚本了 。 该工具的GitHub代码库地址如下:
GitHub传送门:
欢迎登录安全客 -有思想的安全新媒体www.anquanke.com/加入交流群1015601496 获取更多最新资讯
【神经网络与随机数的安全性分析(下)】原文链接:
- 创意|wacom one万与创意数位屏测评
- 黑莓(BB.US)盘前涨逾32%,将与亚马逊开发智能汽车数据平台|美股异动 | US
- 巅峰|realme巅峰之作:120Hz+陶瓷机身+5000mAh 做到了颜值与性能并存
- 抖音小店|抖音进军电商,短视频的商业模式与变现,创业者该如何抓住机遇?
- YFI正式宣布与Sushiswap合作|金色DeFi日报 | 合作
- 小店|抖音小店无货源是什么?与传统模式有什么区别?
- 星期一|亚马逊:黑五与网络星期一期间 第三方卖家销售额达到48亿美元
- 迁徙|网红迁徙记:哪里才是奶与蜜之地?
- 与用户|掌握好这4个步骤,实现了规模性的盈利
- 按键|苹果与宜家合作智能家居快捷按键,定价9.99美元