ImageNet训练再创纪录,EfficientNet异军突起,ResNet:感受到了威胁
 文章插图
文章插图
作者 | 青暮
近年来 , 随着深度学习走向应用落地 , 快速训练ImageNet成为许多机构竞相追逐的目标 。
2017年6月 , FaceBook使用256块GPU以1小时在ImageNet上成功训练了ResNet-50 。 在这之后 , ResNet-50基本成为了快速训练ImageNet的标配架构 。
2018年7月 , 腾讯实现用2048块Tesla P40以6.6分钟在ImageNet上训练ResNet-50 。 同年8月 , Fast.ai实现了18分钟的快速训练 , 他们使用的硬件是128块Tesla V100 。 到11月 , 索尼更是将训练时间压缩为224秒 , 不过其当时使用了2176块Tesla V100 。 Fast.ai和索尼使用的网络架构也都是ResNet 。
那么如今 , 在快速训练ImageNet的竞逐上 , 形成了什么局面呢?
1 ResNet霸榜 , 偶有对手
在DAWNBench的ImageNet训练排行榜上 , 我们可以看到 , 前五名都是使用了ResNet-50 , 并且最快训练时间达到了2分38秒 , 同时还能实现93.04%的top-5准确率 , 以及14.42美元的低训练成本 。
DAWNBench 是斯坦福发布的一套基准测试 , 主要关注端到端的深度学习训练和推断过程 , 用于量化不同优化策略、模型架构、软件框架、云和硬件的训练时间、训练成本、推理延迟和推理成本 。
排行榜地址: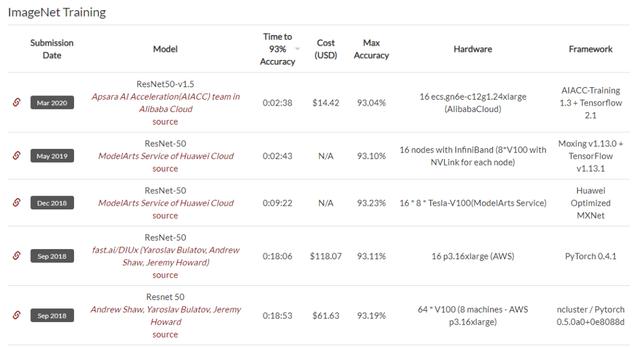 文章插图
文章插图
但除了ResNet-50 , 就没有其它适合快速训练ImageNet的架构了吗?
在这个排行榜的第10位 , 我们看到了一个孤独的名字——AmoebaNet-D N6F256 , 根据排行榜的数据 , 它用1/4个TPUv2 Pod和1小时的时间在ImageNet上达到了93.03%的top-5准确率 。
实际上 , 该架构在2018年4月就由谷歌提出 , 在相同的硬件条件下 , AmoebaNet-D N6F256的训练时间比ResNet-50要短很多 。 文章插图
文章插图
并且 , AmoebaNet-D N6F256的训练成本也只有ResNet-50的一半 。 AmoebaNet-D是基于进化策略进行架构搜索的NAS架构 , 谷歌通过提供复杂的构建模块和较好的初始条件来参与进化过程 , 实现了手动设计和进化的有机组合 。
论文:Regularized Evolution for Image Classifier Architecture Search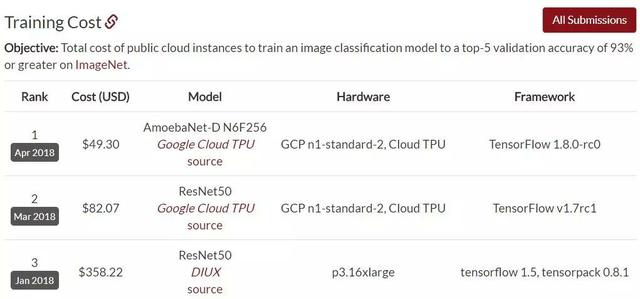 文章插图
文章插图
除此之外 , 在DAWNBench的排行榜上 , 就看不到其它类型的架构了 。 但是在Papers With Code的ImageNet排行榜上 , 就没有出现ResNet和AmoebaNet-D霸榜的现象 。
在top-5准确率前五名中 , 可以注意到 , 除了ResNet以外 , 剩下的架构都和EfficientNet有关 。 其中排名第一的架构 , 其top-5准确率已经达到了98.7% 。 不过这个排行榜并没有列出训练时间、硬件和成本 , 所以和DAWNBench不能一概而论 。
排行榜地址: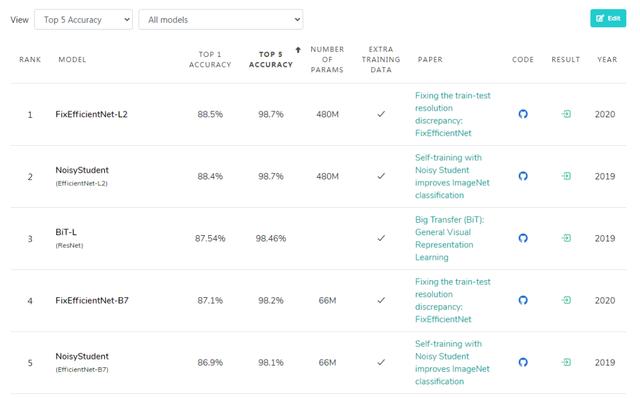 文章插图
文章插图
EfficientNet近日在这项竞逐中也出现了新突破 , 新加坡国立大学的尤洋和谷歌研究院的Quoc Le等人发表了一项新研究 , 表示其用1小时实现了ImageNet的训练 , 并且top-1准确率达到了83%(Papers With Code的排行榜前十名的top-1准确率在86.1%到88.5%之间) 。 文章插图
文章插图
论文地址:
尤洋在推特上表示 , 这项研究在准确率足够高的前提下 , 在速度上创造了一个世界记录 。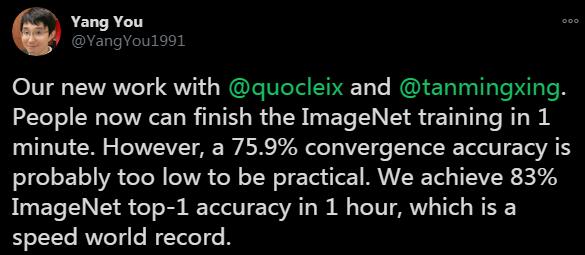 文章插图
文章插图
EfficientNets是基于有效缩放的新型图像分类卷积神经网络系列 。
目前 , EfficientNets的训练可能需要几天的时间;例如 , 在Cloud TPU v2-8节点上训练EfficientNet-B0模型需要23个小时 。
在这项研究中 , 作者探索了在2048个内核的TPU-v3 Pod上训练EfficientNets的技术 , 目的是在以这种规模进行训练时可以实现加速 。
作者讨论了将训练扩展到1024个TPU-v3内核、批量大小为65536时所需的优化 , 例如大批量优化器的选择和学习率的规划 , 以及分布式评估和批量归一化技术的利用 。
此外 , 作者还提供了在ImageNet数据集上训练EfficientNet模型的时序和性能基准 , 以便大规模分析EfficientNets的行为 。
通过优化后 , 作者能够在1小时4分钟内将ImageNet上的EfficientNet训练到83%的top-1准确率 。
图1展示了对不同TPU内核数 , EfficientNet-B2和B5训练时间达到的峰值准确率 。 训练时间在分布式训练和评估循环初始化之后立即开始计算 , 并在模型达到峰值准确率时结束 。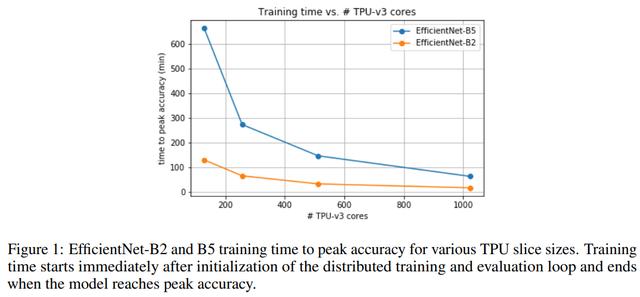 文章插图
文章插图
- 智能手机市场|华为再拿第一!27%的份额领跑全行业,苹果8%排在第四名!
- 体验|闭上眼睛点外卖是什么感觉?时隔一年再次体验,进步令人欣慰
- 逛逛|淘宝内容化再升级:“买家秀”变身“逛逛”试图冲破算法局限
- 再次|华为Mate40Pro干瞪眼?P50再次曝光,这次是真香!
- 打响|拼多多打响双12首枪,iPhone12降到“mini价”,苹果11再见
- 机器人|外骨骼康复训练机器人助力下肢运动功能障碍患者康复训练
- 再见|2020年:三星S20再见了!2021年:三星S21我来了!
- 任正非|任正非:“谁再建言造车,直接调离岗位!”华为为何这么做?
- 对焦速度|Mate40Pro之后,华为还有“硬菜”,或将再次领先行业?
- 关闭|虾米音乐的关闭,再次应证了互联网下竞争的规则,小而精很难生存