Python|PySpark初级教程——大数据分析(附代码实现 )( 二 )
## 打开bashrcsudo gedit ~/bashrc文件中添加以下环境变量:
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64 export SBT_HOME=/usr/share/sbt/bin/sbt-launch.jar export SPARK_HOME=/usr/lib/sparkexport PATH=$PATH:$JAVA_HOME/binexport PATH=$PATH:$SBT_HOME/bin:$SPARK_HOME/bin:$SPARK_HOME/sbinexport PYSPARK_DRIVER_PYTHON=jupyterexport PYSPARK_DRIVER_PYTHON_OPTS='notebook'export PYSPARK_PYTHON=python3export PYTHONPATH=$SPARK_HOME/python:$PYTHONPATH现在 , 更新bashrc文件 。 这将在更新脚本的情况下重新启动终端会话:
source ~/.bashrc现在 , 在终端中输入pyspark , 它将在默认浏览器中打开Jupyter和一个自动初始化变量名为sc的Spark环境(它是Spark服务的入口点):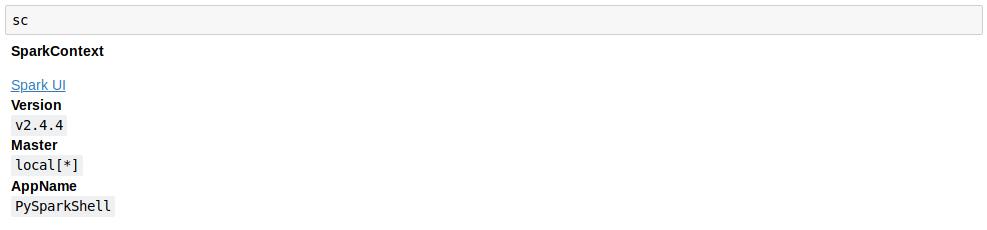 文章插图
文章插图
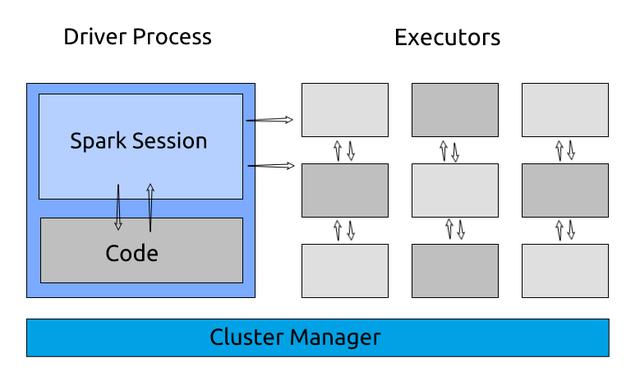
3.什么是Spark应用程序?Spark应用程序是Spark上下文的一个实例 。 它由一个驱动进程和一组执行程序进程组成 。
驱动进程负责维护关于Spark应用程序的信息、响应代码、分发和调度执行器中的工作 。 驱动进程是非常重要的 , 它是Spark应用程序的核心 , 并在应用程序的生命周期内维护所有相关信息 。
执行器负责实际执行驱动程序分配给他们的工作 。 因此 , 每个执行器只负责两件事:
- 执行由驱动程序分配给它的任务
- 将执行程序上的计算状态报告回驱动程序节点
 文章插图
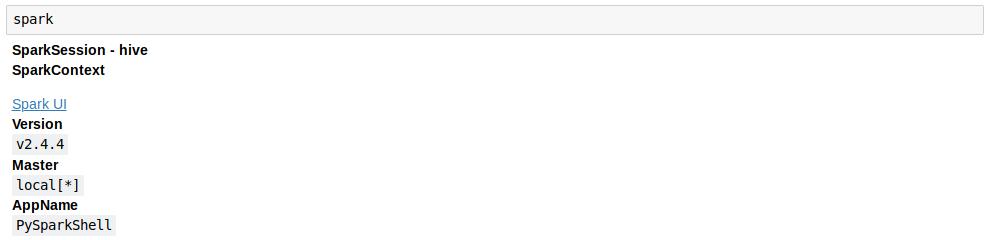
文章插图4.什么是Spark会话?我们知道一个驱动进程控制着Spark应用程序 。 驱动程序进程将自己作为一个称为Spark会话的对象提供给用户 。
Spark会话实例可以使用Spark在集群中执行用户自定义操作 。 在Scala和Python中 , 当你启动控制台时 , Spark会话变量就是可用的:
 文章插图
文章插图5.Spark的分区分区意味着完整的数据不会出现在一个地方 。 它被分成多个块 , 这些块被放置在不同的节点上 。
如果只有一个分区 , 即使有数千个执行器 , Spark的并行度也只有一个 。 另外 , 如果有多个分区 , 但只有一个执行器 , Spark的并行度仍然只有一个 , 因为只有一个计算资源 。
在Spark中 , 较低级别的api允许我们定义分区的数量 。
让我们举一个简单的例子来理解分区是如何帮助我们获得更快的结果的 。 我们将在10到1000之间创建一个包含2000万个随机数的列表 , 并对大于200的数字进行计数 。
让我们看看我们能多快做到这只一个分区:
from random import randint # 创建一个随机数字的列表在10到1000之间my_large_list = [randint(10,1000) for x in range(0,20000000)]# 创建一个分区的列表my_large_list_one_partition = sc.parallelize(my_large_list,numSlices=1)# 检查分区数量print(my_large_list_one_partition.getNumPartitions())# >> 1# 筛选数量大于等于200的数字my_large_list_one_partition = my_large_list_one_partition.filter(lambda x : x >= 200)# 在jupyter中运行代码 # 执行以下命令来计算时间%%time# 列表中元素的数量print(my_large_list_one_partition.count())# >> 16162207
 文章插图
文章插图使用一个分区时 , 花了34.5毫秒来筛选数字:
 文章插图
文章插图现在,让我们将分区的数量增加到5和检查执行时间:
# 创建五个分区my_large_list_with_five_partition = sc.parallelize(my_large_list, numSlices=5)# 筛选数量大于等于200的数字my_large_list_with_five_partition = my_large_list_with_five_partition.filter(lambda x : x >= 200)%%time # 列表中元素的数量print(my_large_list_with_five_partition.count())# >> 16162207
 文章插图
文章插图使用5个分区时 , 花了11.1毫秒来筛选数字:
 文章插图
文章插图6.转换在Spark中 , 数据结构是不可变的 。 这意味着一旦创建它们就不能更改 。 但是如果我们不能改变它 , 我们该如何使用它呢?
因此 , 为了进行更改 , 我们需要指示Spark如何修改数据 。 这些指令称为转换 。
回想一下我们在上面看到的例子 。 我们要求Spark过滤大于200的数字——这本质上是一种转换 。 Spark有两种类型的转换:
- 窄转换:在窄转换中 , 计算单个分区结果所需的所有元素都位于父RDD的单个分区中 。 例如 , 如果希望过滤小于100的数字 , 可以在每个分区上分别执行此操作 。 转换后的新分区仅依赖于一个分区来计算结果
- 告诉|阿里大佬告诉你如何一分钟利用Python在家告别会员看电影
- Python源码阅读-基础1
- Python调用时使用*和**
- 如何基于Python实现自动化控制鼠标和键盘操作
- 解决多版本的python冲突问题
- 学习python第二弹
- Python中文速查表-Pandas 基础
- 零基础小白Python入门必看:通俗易懂,搞定深浅拷贝
- Python 使用摄像头监测心率!这么强吗?
- 十分钟教会你使用Python操作excel,内附步骤和代码