新一代搜索引擎项目 ZeroSearch 设计探索(11)
关于近邻查找的篇幅显得有点啰嗦了 , 最后再简单总结一下:由于文档在索引分片分库的过程中被稀疏和聚集过一次 , 求交过程的连续性 , 以及索引数据相对稳定的特点 , 我们尝试去寻找一些特征来帮助我们加速整个倒排查找过程 。
如果把两种查找方式的时间复杂度相减 , 即2X + logT - 1 - logn , 由于T和n都是常数 , 因此它们的差值为f(x) = 2x + logT - 1 - logn当f(x)大于0时 , 表示对近邻Block进行搜索时 , 步长增长方式的查找消耗更高当f(x)小于0时 , 表示对近邻Block进行搜索时 , 步长增长方式的查找消耗更低很明显 , 在二元坐标轴里 , f(x)是一根斜向上的直线 , 当f(x) = 0时x = (1 + logn - logT) / 2x = (1 + log(n/T)) / 2x = (1 + logN) / 2即只有当x < (1 + logN) / 2 时 , 步长增长查找方式性能才会比二分查找性能会好 。 需要注意的是这里的f(x)中x的定义 , 其定义为步长增长式查找时确认到了目标位置时的查找次数 。 引擎组件化在文章的开头提到过 , 我们以组件化的思想来进行设计 , 在线检索能力被封装成了一个库 , 相比于携带 RPC 框架的引擎 , 检索库的形式可较好的融入已有的开发体系和运维体系 。 既然是以库的形式存在 , 就需要有合适的接口暴露出来 , 让使用者能嵌入业务逻辑和业务数据 。 对于组件化设计 , 核心的设计点如下
1 在线检索过程中检索逻辑与数据需要进行分离 , 一个请求相关的所有数据都是通过检索 Session 来进行管理
2 业务数据的嵌入通过检索入口传入 , 之后交由检索 Session 管理,在这里可以简单看下我们提供的唯一检索入口:
int32_t Retrieve(const RetrieveOptions* retrieve_options,void* business_session)@arg1 retrieve_options : 检索协议(pb格式)@arg2 business_session : 业务session数据3 对整个检索流程中的各个环节暴露出接口封装成类进行管理 , 业务逻辑的嵌入通过反射的形式来实现注入
4 相关性接口同样封装成类 , 业务通过反射的形式来实现注入
整体如下图所示: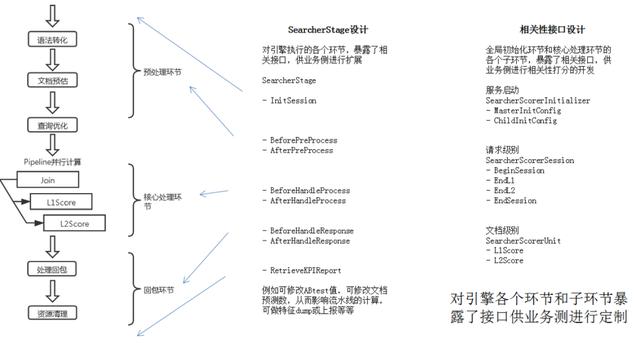 文章插图
文章插图
在进行组件化设计之后 , 检索的细节都被封装在库里 。 这里对 SearcherStage 设计和相关性接口设计再简单介绍一下 。
Searcher 是在线检索组件的名称 , Stage 是我以我拙劣的英文水平选的一个词 , 意为阶段 。 在大环节上面 , 检索流程分为预处理 , 核心处理 , 回包 3 个环节 , 我们在每个大环节的开始和结束阶段都暴露了接口 , 并把所有接口放到了 SearcherStage 类中进行管理 。 对于任何想使用 Searcher 来作为部门内通用搜索引擎的用户来说 , 它必须通过继承并实现 SearcherStage 类的相关接口来实现自己的通用搜索引擎 , 一般来说 , 至少需要通过 SearcherStage 类完成以下 2 件事情 。
1 在AfterHandleResponse中将索引数据转化为业务数据2 在RetrieveKPIReport中对本次请求的检索情况进行上报 , 如检索状态 , 各个阶段的文档数量 , 耗时等等 。 需要再次说明的是 , 每一个 SearcherStage 对象都是一个独立的通用搜索引擎 , 例如在搜一搜这边 , 也只是存在一个 S1SSearcherStage 类 , 并以它为基础封装为了搜一搜的检索库 , 其余的所有垂搜业务都是链接该检索库 , 而非 Searcher 组件 。
下面再简单介绍一下相关性接口的设计 。 相关性接口设计的总体原则:控制复杂度 。 其体现为以下两点
- 人性化的相关性输入信息
- 合理的逻辑拆分
末尾大概的内容就是这样了 , 在引擎的整个设计过程中 , 很多关键的设计点都是跟组内同事 sen 进行探讨后得到 , sen 给了我很多指导和把控 。 我们整体的设计原则其实非常简单:
- 研发|闽企制伞有“功夫”项目入选国家重点研发计划
- 建设|龙元建设中标中国移动宁波信息通信产业园二期施工项目
- 钢筋|海南国道G360文临公路项目引进钢筋智能“焊”将
- 名单|河南8个项目入选国家级示范名单
- 新一代|外媒: 高通新一代旗舰处理器或命名为骁龙888
- 项目|Yearn帝国正在崛起,有多少DeFi项目开始瑟瑟发抖
- 合并|Andre Cronje主导批量「合并」DeFi项目,是好事情吗?
- 贵阳|捷顺科技(002609.SZ)中标贵阳智慧停车公共信息服务平台系统建设项目
- 建设|日海智能(002313.SZ)中标板障山山地步道项目线路一智慧化建设设计施工总承包项目
- 团队|为什么项目管理非常重要?