概率分布|语音识别第一课:基于Tensorflow的端到端语音识别技术
全文共6655字 , 预计学习时长13分钟 文章插图
文章插图
本文阐述了如何利用Tensorflow编写一个基本的端到端自动语音识别(Automatic Speech Recognition , ASR)系统 , 详细介绍了最小神经网络的各个组成部分以及可将音频转为可读文本的前缀束搜索解码器 。
虽然当下关于如何搭建基础机器学习系统的文献或资料有很多 , 但是大部分都是围绕计算机视觉和自然语言处理展开的 , 极少有文章就语音识别展开介绍 。 本文旨在填补这一空缺 , 帮助初学者降低入门难度 , 提高学习自信 。
前提
初学者需要熟练掌握:
· 神经网络的组成
· 如何训练神经网络
· 如何利用语言模型求得词序的概率
概述
· 音频预处理:将原始音频转换为可用作神经网络输入的数据
· 神经网络:搭建一个简单的神经网络 , 用于将音频特征转换为文本中可能出现的字符的概率分布
· CTC损失:计算不使用相应字符标注音频时间步长的损失
· 解码:利用前缀束搜索和语言模型 , 根据各个时间步长的概率分布生成文本
本文重点讲解了神经网络、CTC损失和解码 。
音频预处理
搭建语音识别系统 , 首先需要将音频转换为特征矩阵 , 并输入到神经网络中 。 完成这一步的简单方法就是创建频谱图 。
def create_spectrogram(signals): stfts = tf.signal.stft(signals, fft_length=256) spectrograms = tf.math.pow(tf.abs(stfts), 0.5) return spectrograms这一方法会计算出音频信号的短时傅里叶变换(Short-time Fourier Transform)以及功率谱 , 其最终输出可直接用作神经网络输入的频谱图矩阵 。 其他方法包括滤波器组和MFCC(Mel频率倒谱系数)等 。
了解更多音频预处理知识:
神经网络
下图展现了一个简单的神经网络结构 。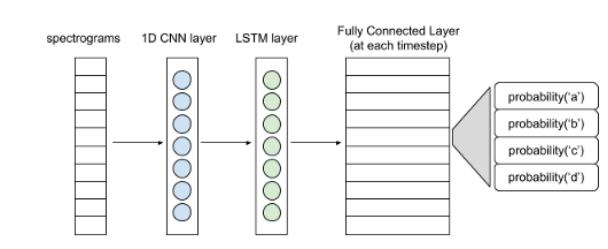 文章插图
文章插图
语音识别基本结构
频谱图输入可以看作是每个时间步长的向量 。 1D卷积层从各个向量中提取出特征 , 形成特征向量序列 , 并输入LSTM层进一步处理 。 LSTM层(或双LSTM层)的输入则传递至全连接层 。 利用softmax激活函数 , 可得出每个时间步长的字符概率分布 。 整个网络将会用CTC损失函数进行训练(CTC即Connectionist Temporal Classification , 是一种时序分类算法) 。 熟悉整个建模流程后可尝试使用更复杂的模型 。
class ASR(tf.keras.Model): def __init__(self, filters, kernel_size, conv_stride, conv_border, n_lstm_units, n_dense_units): super(ASR, self).__init__() self.conv_layer = tf.keras.layers.Conv1D(filters, kernel_size, strides=conv_stride, padding=conv_border, activation='relu') self.lstm_layer = tf.keras.layers.LSTM(n_lstm_units, return_sequences=True, activation='tanh') self.lstm_layer_back = tf.keras.layers.LSTM(n_lstm_units, return_sequences=True, go_backwards=True, activation='tanh') self.blstm_layer = tf.keras.layers.Bidirectional(self.lstm_layer, backward_layer=self.lstm_layer_back) self.dense_layer = tf.keras.layers.Dense(n_dense_units) def call(self, x): x = self.conv_layer(x) x = self.blstm_layer(x) x = self.dense_layer(x) return x为什么使用CTC呢?搭建神经网络旨在预测每个时间步长的字符 。 然而现有的标签并不是各个时间步长的字符 , 仅仅是音频的转换文本 。 而文本的各个字符可能横跨多个步长 。 如果对音频的各个时间步长进行标记 , C-A-T就会变成C-C-C-A-A-T-T 。 而每隔一段时间 , 如10毫秒 , 对音频数据集进行标注 , 并不是一个切实可行的方法 。 CTC则解决上了上述问题 。 CTC并不需要标记每个时间步长 。 它忽略了文本中每个字符的位置和实际相位差 , 把神经网络的整个概率矩阵输入和相应的文本作为输入 。
CTC 损失计算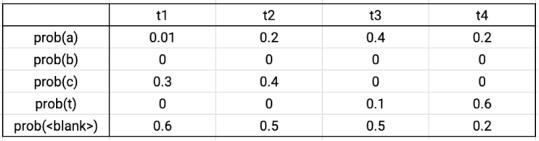 文章插图
文章插图
输出矩阵示例
假设真实的数据标签为CAT , 在四个时间步长中 , 有序列C-C-A-T , C-A-A-T , C-A-T-T , _-C-A-T , C-A-T-_与真实数据相对应 。 将这些序列的概率相加 , 可得到真实数据的概率 。 根据输出的概率矩阵 , 将序列的各个字符的概率相乘 , 可得到单个序列的概率 。 则上述序列的总概率为0.0288+0.0144+0.0036+0.0576+0.0012=0.1056 。 CTC损失则为该概率的负对数 。 Tensorflow自带损失函数文件 。
解码
由上文的神经网络 , 可输出一个CTC矩阵 。 这一矩阵给出了各个时间步长中每个字符在其字符集中的概率 。 利用前缀束搜索 , 可从CTC矩阵中得出所需的文本 。
除了字母和空格符 , CTC矩阵的字符集还包括两种特别的标记(token , 也称为令牌)——空白标记和字符串结束标记 。
- 自动任务|赶在三星 S21 发布之前实现语音解锁
- 「软件分享」语音转文字软件
- 分布式锁的这三种实现90%的人都不知道
- 巨杉亮相 DTCC2019,引领分布式数据库未来发展
- Martian框架发布 3.0.3 版本,Redis分布式锁
- 为什么分布式应用程序需要依赖管理?
- 大规模分布式强化学习基础架构Menger, 大幅提高真实任务的学习效率
- 分布式云对智能化战争有何影响
- 米家投影仪青春版2代体验:硬件升级,支持侧投+远场语音
- 新能源汽车火热 产业链分布速览(附名单)