如何保证核心链路稳定性的流控和熔断机制?
首发公众号:码农架构
仅从设计优化、服务拆分、自动扩容等方面进行优化 , 有时候并不能完全解决问题 。 比如 , 有时流量增长过快 , 扩容流程还来不及完成 , 服务器可能就已经抗不住了
既然突发流量我们没法预测 , 业务上也不可能不依赖任何外部服务和资源 , 那么有什么办法能尽量避免 , 或者降低出现这些问题时对核心业务的影响呢?
流量控制01.流控常用的算法
目前业内常用的流控方法有两种:漏桶算法和令牌桶算法
- 漏桶算法
- 令牌算法
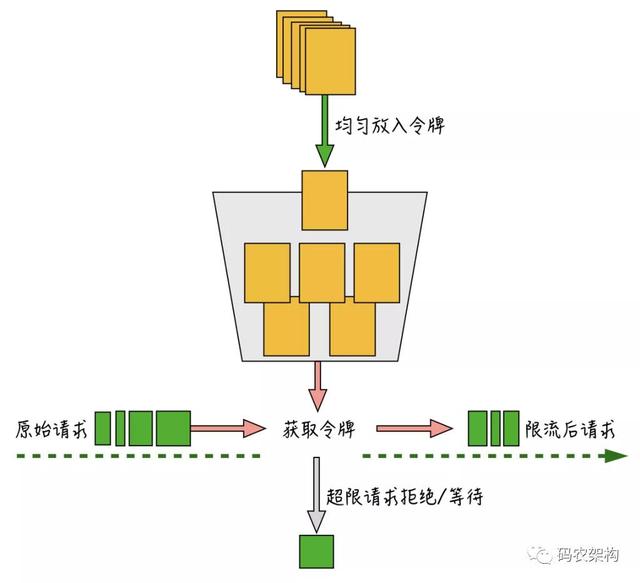
- 每 1/r 秒往桶里放入一个令牌 , r 是用户配置的平均发送速率(也就是每秒会有 r 个令牌放入) 。
- 桶里最多可以放入 b 个令牌 , 如果桶满了 , 新放入的令牌会被丢弃 。
- 如果来了 n 个请求 , 会从桶里消耗掉 n 个令牌 。
- 如果桶里可用令牌数小于 n , 那么这 n 个请求会被丢弃掉或者等待新的令牌放入 。
 文章插图
文章插图算法按一定速度均匀往桶里放入令牌 , 原始请求进入后 , 根据请求量从令牌桶里取出需要的令牌数 , 如果令牌数不够 , 会直接抛弃掉超限的请求或者进行等待 , 能成功获取到令牌的请求才会进入到后端服务器 。
与漏桶算法“精确控制速率”不太一样的是 , 由于令牌桶的桶本身具备一定的容量 , 可以允许一次把桶里的令牌全都取出 , 因此 , 令牌桶算法在限制请求的平均速率的同时 , 还允许一定程度的突发流量 。
算法按一定速度均匀往桶里放入令牌 , 原始请求进入后 , 根据请求量从令牌桶里取出需
02.全局流控
在分布式服务的场景下 , 很多时候的瓶颈点在于全局的资源或者依赖 , 这种情况就需要分布式的全局流控来对整体业务进行保护 。
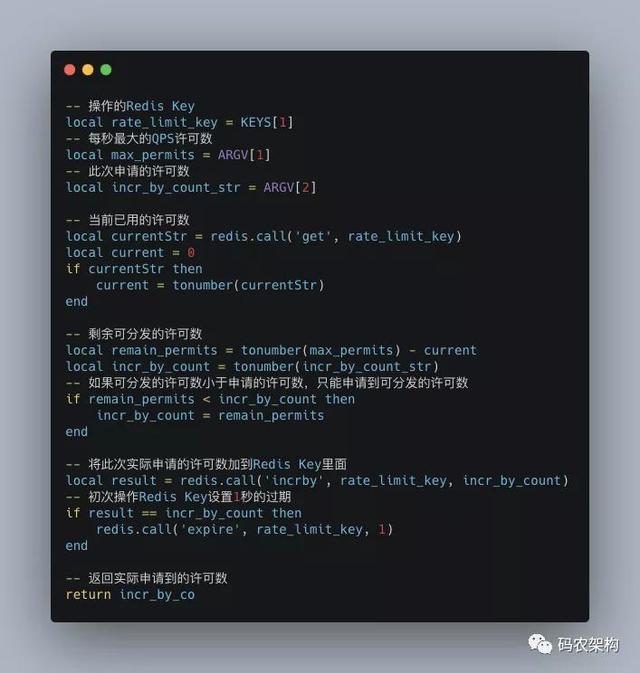
业界比较通用的全局流控方案 , 一般是通过中央式的资源(如:Redis、Nginx)配合脚本来实现全局的计数器 , 或者实现更为复杂的漏桶算法和令牌桶算法 , 比如可以通过 Redis 的 INCR 命令配合 Lua 实现一个限制 QPS(每秒查询量)的流控组件 。
 文章插图
文章插图一个需要注意的细节是:在每次创建完对应的限流 Key 后 , 你需要设置一个过期的时间 。 整个操作是原子化的 , 这样能避免分布式操作时设置过期时间失败 , 导致限流的 Key 一直无法重置 , 从而使限流功能不可用 。 此外 , 在实现全局流控时还有两个问题需要注意:一个是流控的粒度问题 , 另一个是流控依赖资源存在瓶颈的问题 。 下面我们分别来看一下 , 在实现全局流控时是如何解决这两个问题的 。
03.细粒度控制
首先是针对流控的粒度问题 。 举个例子:在限制 QPS 的时候 , 流控粒度太粗 , 没有把 QPS 均匀分摊到每个毫秒里 , 而且边界处理时不够平滑 , 比如上一秒的最后一个毫秒和下一秒的第一个毫秒都出现了最大流量 , 就会导致两个毫秒内的 QPS 翻倍 。
【如何保证核心链路稳定性的流控和熔断机制?】一个简单的处理方式是把一秒分成若干个 N 毫秒的桶 , 通过滑动窗口的方式 , 将流控粒度细化到 N 毫秒 , 并且每次都是基于滑动窗口来统计 QPS , 这样也能避免边界处理时不平滑的问题 。
自动熔断机制雪崩效应在多依赖服务中往往会导致一个服务出问题 , 从而拖慢整个系统的情况 。
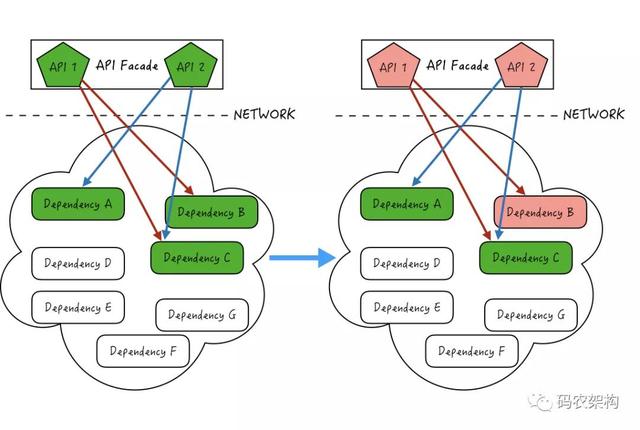
为了便于管理和隔离 , 我们经常会对服务进行解耦 , 独立拆分解耦到不同的微服务中 , 微服务间通过 RPC 来进行调用和依赖:
 文章插图
文章插图- 手动通过开关来进行依赖的降级
- 自动熔断机制主要是通过持续收集被依赖服务或者资源的访问数据和性能指标 , 当性能出现一定程度的恶化或者失败量达到某个阈值时 , 会自动触发熔断 , 让当前依赖快速失败(Fail-fast) , 并降级到其他备用依赖 , 或者暂存到其他地方便于后续重试恢复 。 在熔断过程中 , 再通过不停探测被依赖服务或者资源是否恢复 , 来判断是否自动关闭熔断 , 恢复业务 。
- 王兴称美团优选目前重点是建设核心能力;苏宁旗下云网万店融资60亿元;阿里小米拟增资居然之家|8点1氪 | 美团
- 页面|如何简单、快速制作流程图?上班族的画图技巧get
- 培育|跨境电商人才如何培育,长沙有“谱”了
- 抖音小店|抖音进军电商,短视频的商业模式与变现,创业者该如何抓住机遇?
- 计费|5G是如何计费的?
- 车轮旋转|牵引力控制系统是如何工作的?它有什么作用?
- 视频|短视频如何在前3秒吸引用户眼球?
- Vlog|中国Vlog|中国基建如何升级?看5G+智慧工地
- 涡轮|看法米特涡轮流量计如何让你得心应手
- 手机|OPPO手机该如何截屏?四种最简单的方法已汇总!