深度学习在 Airbnb 中的探索与应用( 二 )
发现:
- DL 中的每一层 , 输出都是越来越平滑上图中 , 从下到上 , 分别是模型每层的输出
- 如果在输入层就平滑 , 将会提升泛化能力底层的平滑输出 , 将保证高层对未知特征组合的稳定性
- 便于排查异常 , 保证特征完整性下图是预定天数特征 , 左边为原始预定天数分布 , 右图为考虑预定天数中值后的分布
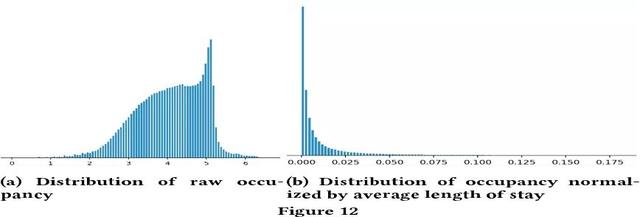 文章插图
文章插图3. 特殊特征 ( 经纬度 ) 平滑
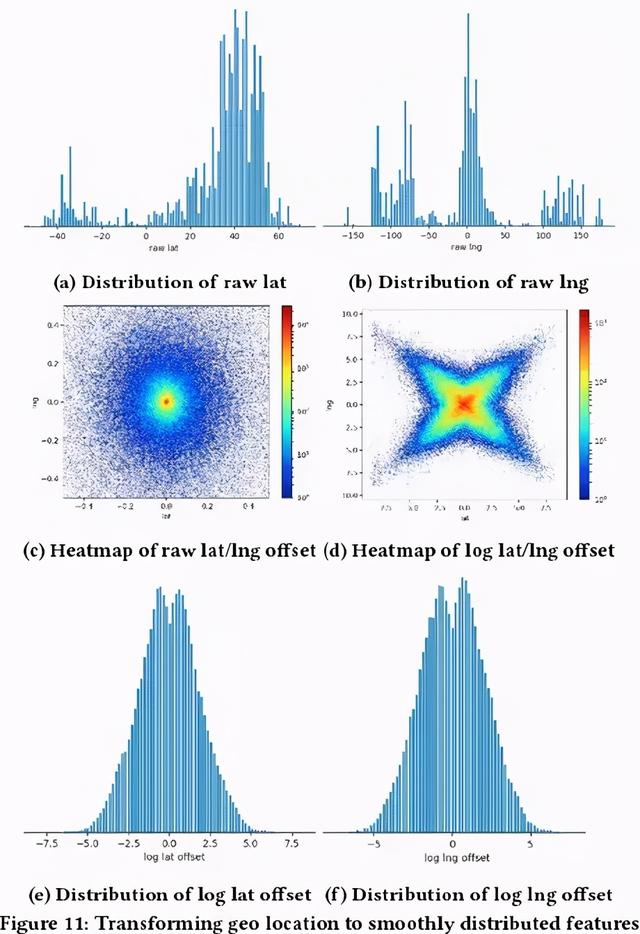 文章插图
文章插图经纬度平滑过程:
直接使用经纬度特征 , 分布极其不均衡 ( 见上图第一层图片 )。
第二层图片左图 , 是对目标地点的距离特征分布 , 可以看出大部分的点走在原点位置 , 其他的很多点以原点为中心均匀的分散开来 。
第二层图片右图 , 是对经纬度分别取 log。
将经纬度的 offset 分别取 log ( 上图最底层图片 ), 得到基于距离的全局特征 , 而不是基于特定地理位置的特征 。
4. 离散特征 embedding
 文章插图
文章插图发现:
- 虽然 item-embedding 在此场景不适用 , 但一些零散特征的 embedding 仍然有效 ( 主要针对不可比较、选项较多的离散值特征 )
- 利用搜索城市后的街道连续点击行为 , 构建街道 embedding
- 对全局query搜索内容进行初步聚合 , 再建立 embedding , 产出作为用户搜索特征输入
失败做法:
- 分解深度学习的 score , 给出每一部分特征重要度分析:多层非线性断绝分解的希望
- 依次移除特征 , 查看模型性能变化 。 分析:特征之间不完全独立 , 在特征工程后尤其如此
- 随机修改某些特征 , 查看性能变化分析:特征依旧不独立 , 没法排除 noise
- 产出测试集预测的 list 排序
- 观察某个特征在头部 list 与尾部 list 的区别 , 有区分度为重要特征
- 下图中 , 左侧为 price, 头部 price 比尾部低;右侧为评论数 , 头部与尾部没区别
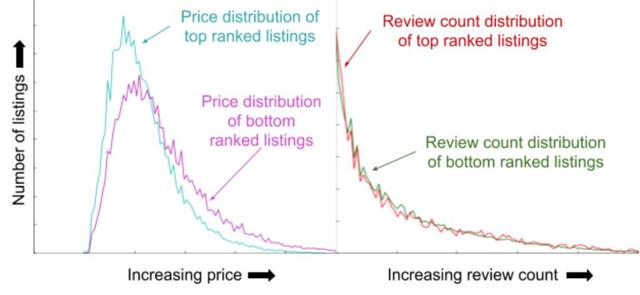 文章插图
文章插图五、系统工程
Airbnb 系统介绍:
1. 工程架构
- JavaServer 处理 query
- Spark 记录 logs
- Tensorflow 进行模型训练
- JavaNNLibrary 线上低延迟预测
- GBDT 时代采用 CSV, 读入耗时长
- Tf 时代改用 Protobufs, 效率提升17倍 , GPU 利用率达到90%
- 大量样本共同拥有的统计类特征 , 成为数据读取瓶颈
- 整合统计类特征 , 将其汇总后 , 看作不可训练的 embedding 矩阵 , 作为 tf 的统计特征节点输入层参数
- Dropout 层没有带来增益
- 初始化采用 {-1,1} 的范围均匀随机 , 比全0初始化要好
- Batchsize 选用200 , 最优化使用 lazyAdom
- 麒麟|荣耀新款,麒麟810+4800万超清像素,你还在犹豫什么呢?
- 智能手机市场|华为再拿第一!27%的份额领跑全行业,苹果8%排在第四名!
- 行业|现在行业内客服托管费用是怎么算的
- 零部件|马瑞利发力电动产品,全球第七大零部件供应商在转型
- 通气会|12月4~6日,2020中国信息通信大会将在成都举行
- 俄罗斯手机市场|被三星、小米击败,华为手机在俄罗斯排名跌至第三!
- 体验|闭上眼睛点外卖是什么感觉?时隔一年再次体验,进步令人欣慰
- 当初|这是我的第一部华为手机,当初花6799元买的,现在“一文不值”?
- 出海|出海日报丨短视频生产服务商小影科技完成近4亿元 C 轮融资;华为成为俄罗斯在线出售智能手机的第一品牌
- 看过明年的iPhone之后,现在下手的都哭了