直面L5级自动驾驶!Imagination推4NX芯片
桌面图形芯片领域被NVIDIA和AMD两大巨头牢牢把控 。 曾经统治手机GPU?IP市场的Imagination在2017年被苹果“抛弃” , 随后在2020年初重归于好 。 在经历多次变动之后 , Imagination先进占据36%的移动GPU?IP市场、汽车GPU?IP市占率更是达到43% 。 ? 文章插图
文章插图
??能够与苹果“再续前缘” , 主要得益于Imagination在最近两年技术上的大幅进步 。 Imagination在11月13日发布耗时两年研发的第三代神经网络加速器(NNA)产品IMG?Series4 , 面向先进驾驶辅助系统(ADAS)和自动驾驶应用 , 全新的多核架构可提供600?TOPS(每秒万亿次操作)甚至更高的性能 。
??对于外界来说 , 以低功耗产品见长Imagination推出高性能AI加速器 , 会在自动驾驶汽车芯片市场给NVIDIA带来哪些压力?是否会直接改变自动驾驶芯片市场格局?
??Imagination在2017年推出第一代神经网络加速器(NNA)PowerVR?2NX , 单核性能从1TOPS提升到4.1TOPS 。 2018年发布的PowerVR?3NX单核性能从0.6TOPS到10TOPS , 多核产品性能从20TOPS到160TOPS 。 虽然这两款芯片都是属于AI产品 , 但NNA除了面对2NX移动设备和汽车市场外 , Imagination进一步拓展到智能相机监控、消费电子(尤其是数字电视)、低功耗IoT智能设备领域 。
??虽然第三代NNA的4NX在时隔两年后发布 , 但Imagination为4NX的核心进行重新设计 , 新架构的每个单核能以不到1瓦的功耗提供12.5TOPS的性能 。 Imagination还为4NX带来全新的多核架构 , 新的多核架构支持在多个内核之间对工作负载进行灵活的分配和同步 , 实现更高性能 。 ? 文章插图
文章插图
??Imagination通过对多个工作负载进行批处理、拆分和调度 , 提高灵活性并为带来精细的控制能力 , 可以在任意数量的内核上使用 。 多核灵活架构带来的可扩展性让4NX实现高性能 , 但AI芯片的功耗控制同样非常重要 。 4NX系列的8内核集群要实现100TOPS的性能、超过30TOPS/Watt能耗比以及12TOPS/mm^2的性能密度 , 需要在5nm节点实现 。 ?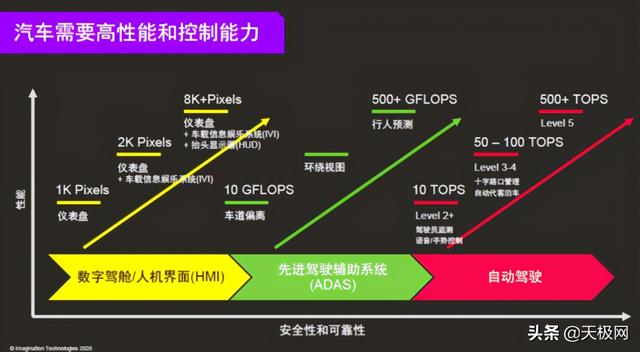 文章插图
文章插图
??Series4可为每个集群配置?2个、4个、6个或者8个内核 。 1个8内核的集群可提供100TOPS的算力 , 配有6个8核集群的解决方案就能够提供600TOPS的算力 。 AI推理方面 , Series4?NNA的性能比嵌入式GPU快20倍以上 , 比嵌入式CPU快1000倍 。 Imagination?Technologies产品管理部门总监Gilberto?Rodriguez表示 , 如果要用多个集群实现更高算力 , Imagination还可以提供多集群的协同机制 , 只是需要客户在应用层进行一些设计 。
??AI芯片需要处理大量的数据 , 而数据的搬运过程中的功耗远大于数据处理 , 所以高性能AI芯片必须尽量减少数据搬运 , 降低延迟和节省带宽 。 Imagination采用单核组成2核、4核、6核或8核的多核集群中、内核相互协作并行处理任务的方式 , 降低处理延迟、缩短响应时间 。 ? 文章插图
文章插图 文章插图
文章插图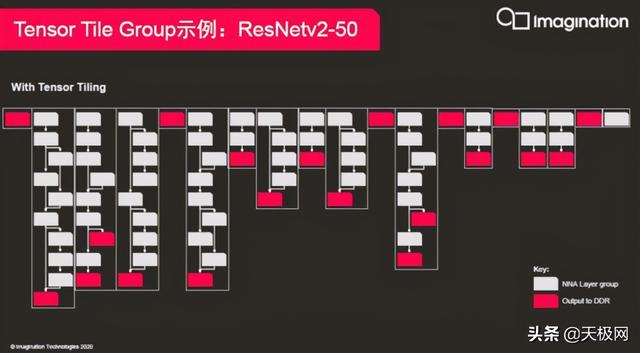 文章插图
文章插图
??带宽节省方面 , Imagination使用自家正在申请专利的Tensor?Tiling(?Imagination’s?Tensor?Tiling , ITT)技术 , 利用本地数据的依赖性将中间数据保存在片上存储器中 , 最大限度地减少将数据传输至外部存储器 , 带宽占用比上代产品低90% 。
??神经网络的多层以融合内核的形式运行在加速器的硬件流水线里 , 融合内核之间的特征图(Feature?Map)需要通过外部存储进行交换 。 Tiling技术充分利用紧耦合SRAM来融合更多的层 , 从而实现减少与外部存储交换的特征图 , 达到提升效率、节省带宽的目的 。
??Tensor?Tiling技术中的批处理和拆分 , 批处理是分配适合批处理的大量的小型网络任务到每个独立工作的NNA单核 , 提升并行处理能力 。 拆分只需通过Imagination提供的编译器即可完成 , 利用NNA的性能分析工具能够对AI任务进行更好地调度和分配;所有NNA单核共同执行推理任务 , 减少网络推理延迟 , 在理想情况下协同并行处理的吞吐量与独立并发处理的相同 , 非常适合网络层很大的网络 。
??ADAS和自动驾驶被视为未来的发展方向 , 相关芯片对硬件的算力需求相当高 , L2+的驾驶员检测或语音/手势控制需要10TOPS的性能 , L3-L4级别的自动驾驶有50-100TOPS的性能需求 , L5级别的自动驾驶性能需求超过500TOPS 。 虽然市场上已经有满足自动驾驶需求的AI芯片 , 但功耗不够理想 。 所以Imagination花两年时间了解和评估客户需求后 , 推出基于前两代低功耗产品的高性能低功耗4NX系列 。 Imagination?4NX系列不仅会应用于自动驾驶市场 , 也能应用于数据中心和桌面级GPU 。
- 闲鱼|电诉宝:“闲鱼”网络欺诈成用户投诉热点 Q3获“不建议下单”评级
- 逛逛|淘宝内容化再升级:“买家秀”变身“逛逛”试图冲破算法局限
- 自动|碳博士控股子公司推出最新款自动驾驶清扫车
- 启动|饿了么宣布启动“1212超级粉丝狂欢节”联合34家品牌推吃货卡季卡
- 拍照|iPhone12还没捂热13就曝光了,屏幕、信号、拍照均有升级!
- 开发自|不妥协不追随 Member’s Mark升级背后的“山姆哲学”
- 自动驾驶汽车|海外|自动驾驶无法可依?美国多个团体联合发布自动驾驶立法大纲
- Vlog|中国Vlog|中国基建如何升级?看5G+智慧工地
- 名单|河南8个项目入选国家级示范名单
- 品牌|为求差异化 山姆升级自有品牌Member’s Mark