贝叶斯模型|数据分析经典模型——贝叶斯理论,10分钟讲清楚
说到贝叶斯模型 , 就算不是搞数据分析的人应该都会有所耳闻 , 因为它的应用范围实在是太广了 , 大数据、机器学习、数据挖掘、数据分析等领域几乎都能够找到贝叶斯模型的影子 , 甚至在金融投资、日常生活中我们都会用到 , 但是却很少有人真正理解这个模型 。
什么是贝叶斯模型?在介绍贝叶斯模型之前 , 我们先看一个经典的贝叶斯数据挖掘案例
如果你在一家购房机构上班 , 今天有8个客户来跟你进行了购房沟通 , 最终你将这8个客户的信息录入了系统之中: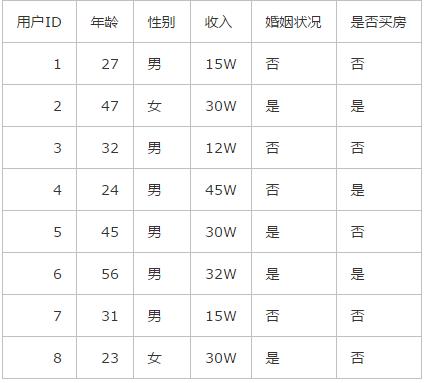 文章插图
文章插图
此时又有一个客户走了进来 , 经过交流你得到了这个客户的信息: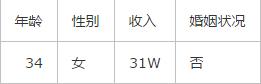 文章插图
文章插图
那么你是否能够判断出这位客户会不会买你的房子呢?
如果你没有接触过贝叶斯理论 , 你就会想 , 原来的8个客户只有3个买房了 , 5个没有买房 , 那么新来的这个客户买房的意愿应该也只有3/8。
这代表了传统的频率主义理论 , 就跟抛硬币一样 , 抛了100次 , 50次都是正面 , 那么就可以得出硬币正面朝上的概率永远是50% , 这个数值是固定不会改变的 。 例子里的8个客户就相当于8次重复试验 , 其结果基本上代表了之后所有重复试验的结果 , 也就是之后所有客户买房的几率基本都是3/8。
【贝叶斯模型|数据分析经典模型——贝叶斯理论,10分钟讲清楚】但此时你又觉得似乎有些不对 , 不同的客户有着不同的条件 , 其买房概率是不相同的 , 怎么能用一个趋向结果代表所有的客户呢?
对了!这就是贝叶斯理论的思想 , 简单点讲就是要在已知条件的前提下 , 先设定一个假设 , 然后通过先验实验来更新这个概率 , 每个不同的实验都会带来不同的概率 , 这就是贝叶斯公式: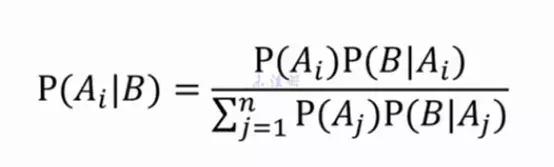 文章插图
文章插图
按照这个公式 , 我们就可以完美解决上面的这个例子:
先找出“年龄”、“性别”、“收入”、“婚姻状况”这四个维度中买房和不买房的概率:
年龄
P(b1|a1) :30-40买房的概率是1/3
P(b1|a2) : 30-40没买房的概率是2/5
收入
P(b2|a1) --- 20-40买房的概率是2/3
P(b2|a2) --- 20-40没买房的概率是2/5
婚姻状况
P(b3|a1) --- 未婚买房的概率是1/3
P(b3|a2) --- 未婚没买房的概率是3/5
性别:
P(b4|a1) --- 女性买房的概率是1/3
P(b4|a2) --- 女性没买房的概率是1/5
OK , 现在将所有的数据代入到贝叶斯公式中整合:
新用户买房的统计概率为P(b|a1)P(a1)=0.33*0.66*0.33*0.33*3/8=0.0089
新用户不会买房的统计概率为P(b|a2)P(a2)=0.4*0.4*0.6*0.2*5/8=0.012
所以可以得出结论:新用户不买房的概率更大一些 。
怎么做贝叶斯模型?贝叶斯的工作流程可以分为三个阶段进行 , 分别是准备阶段、分类器训练阶段和应用阶段 。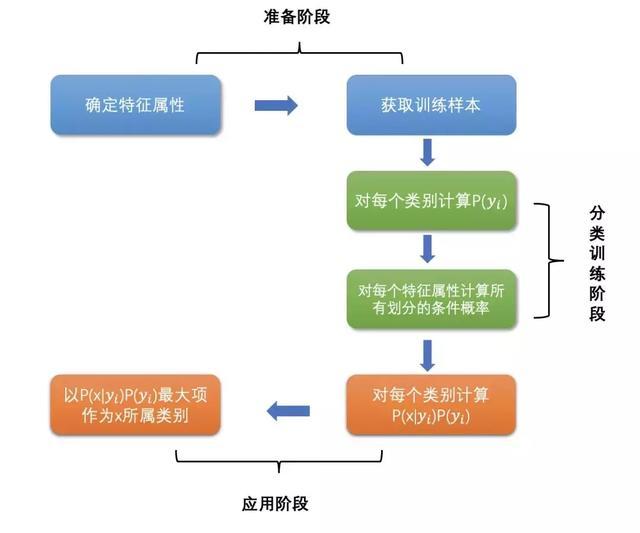 文章插图
文章插图
1、准备阶段:
这个阶段的任务是为朴素贝叶斯分类做必要的准备 , 主要工作是根据具体情况确定特征属性 , 并对每个特征属性进行适当划分 , 去除高度相关性的属性 , 然后由人工对一部分待分类项进行分类 , 形成训练样本集合 。
这一阶段的输入是所有待分类数据 , 输出是特征属性和训练样本 。 (相当于上述例子中那8个客户的信息 , 这个步骤是需要人工进行整合的)
2、分类器训练阶段:
这个阶段的任务就是生成分类器 , 主要工作是计算每个类别在训练样本中的出现频率及每个特征属性划分对每个类别的条件概率估计 , 并将结果记录 。 其输入是特征属性和训练样本 , 输出是分类器 。
这一阶段是机械性阶段 , 根据前面讨论的公式可以由程序自动计算完成 。
3、应用阶段:这个阶段的任务是使用分类器对待分类项进行分类 , 其输入是分类器和待分类项 , 输出是待分类项与类别的映射关系 。
这一阶段也是机械性阶段 , 由程序完成 。 文章插图
文章插图
贝叶斯有什么优、缺点?贝叶斯模型的优点有4个 , 分别是:
- 贝叶斯模型发源于古典数学理论 , 有稳定的分类效率 。
- 对缺失数据不太敏感 , 算法也比较简单 , 常用于文本分类 。
- 分类准确度高 , 速度快 。
- 俄罗斯手机市场|被三星、小米击败,华为手机在俄罗斯排名跌至第三!
- 出海|出海日报丨短视频生产服务商小影科技完成近4亿元 C 轮融资;华为成为俄罗斯在线出售智能手机的第一品牌
- 超级|特斯拉获准在柏林超级工厂所在地开始第二阶段的森林砍伐
- 小米|华为成俄罗斯线上销售最受欢迎品牌!小米紧随其后
- 新宠|俄罗斯向中国靠拢!华为手机成俄“新宠”:在线市场销量占比30%
- 车主|特斯拉发布了新的软件更新,这个导航功能只有中国才有
- 荷兰专家:中国突然宣布,将与日本尼康强强联合,阿斯麦处境危矣
- NeurIPS 2020论文分享第一期|深度图高斯过程 | 深度图
- 在线|华为成俄罗斯在线出售智能手机第一品牌,占在线销售总额的30%
- 俄罗斯|厉害了!华为手机在俄罗斯线上销量第一