PyTorch实现用于文本生成的循环神经网络( 二 )
 文章插图
文章插图
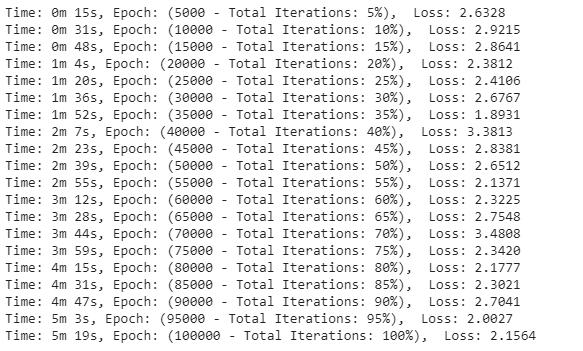
我们将可视化训练中的损失 。
【PyTorch实现用于文本生成的循环神经网络】plt.figure(figsize=(7,7))plt.title("Loss")plt.plot(all_losses)plt.xlabel("Epochs")plt.ylabel("Loss")plt.show()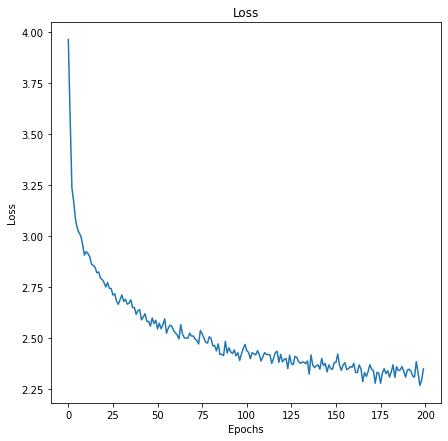 文章插图
文章插图
最后 , 我们将对我们的模型进行测试 , 以测试在给定起始字母表字母时生成属于语言的名称 。
max_length = 20# 类别和起始字母中的示例def sample_model(category, start_letter='A'):with torch.no_grad():# no need to track history in samplingcategory_tensor = categ_Tensor(category)input = inp_Tensor(start_letter)hidden = NameGenratorModule.initHidden()output_name = start_letterfor i in range(max_length):output, hidden = NameGenratorModule(category_tensor, input[0], hidden)topv, topi = output.topk(1)topi = topi[0][0]if topi == n_let - 1:breakelse:letter = all_let[topi]output_name += letterinput = inp_Tensor(letter)return output_name# 从一个类别和多个起始字母中获取多个样本def sample_names(category, start_letters='XYZ'):for start_letter in start_letters:print(sample_model(category, start_letter))现在 , 我们将检查样本模型 , 在给定语言和起始字母时生成名称 。
print("Italian:-")sample_names('Italian', 'BPRT')print("\nKorean:-")sample_names('Korean', 'CMRS')print("\nRussian:-")sample_names('Russian', 'AJLN')print("\nVietnamese:-")sample_names('Vietnamese', 'LMT') 文章插图
文章插图
因此 , 正如我们在上面看到的 , 我们的模型已经生成了属于语言类别的名称 , 并从输入字母开始 。
参考文献:
- Trung Tran, “Text Generation with Pytorch”.
- “NLP from scratch: Generating names with a character level RNN”, PyTorch Tutorial.
- Francesca Paulin, “Character-Level LSTM in PyTorch”, Kaggle.
- 与用户|掌握好这4个步骤,实现了规模性的盈利
- 优化|微软亚洲研究院发布开源平台“群策 MARO” 用于多智能体资源调度优化
- 落地|“电竞之都”争夺战中,城市们该怎样实现产业落地?
- 输送|新时达:“用于机器人码垛的输送系统”获发明专利
- 美好生活|以人为本实现万物互融,中国视频社会化时代开启
- 用于|用于半监督学习的图随机神经网络
- 手机|女神的自拍秘密,只需一部vivo S7便可以实现
- 自动任务|赶在三星 S21 发布之前实现语音解锁
- 核磁共振|研发用于教研的核磁共振量子计算机,「量旋科技」还想在超导量子技术上取得突破
- 产业|新主导力量来了,上海如何实现一次“革命性重塑”?