深入解析 Flink 的算子链机制
“为什么我的 Flink 作业 Web UI 中只显示出了一个框 , 并且 Records Sent 和Records Received 指标都是 0 ?是我的程序写得有问题吗?”
Flink 算子链简介笔者在 Flink 社区群里经常能看到类似这样的疑问 。 这种情况几乎都不是程序有问题 , 而是因为 Flink 的 operator chain ——即算子链机制导致的 , 即提交的作业的执行计划中 , 所有算子的并发实例(即 sub-task )都因为满足特定条件而串成了整体来执行 , 自然就观察不到算子之间的数据流量了 。
当然上述是一种特殊情况 。 我们更常见到的是只有部分算子得到了算子链机制的优化 , 如官方文档中出现过多次的下图所示 , 注意 Source 和 map() 算子 。 文章插图
文章插图
【深入解析 Flink 的算子链机制】算子链机制的好处是显而易见的:所有 chain 在一起的 sub-task 都会在同一个线程(即 TaskManager 的 slot)中执行 , 能够减少不必要的数据交换、序列化和上下文切换 , 从而提高作业的执行效率 。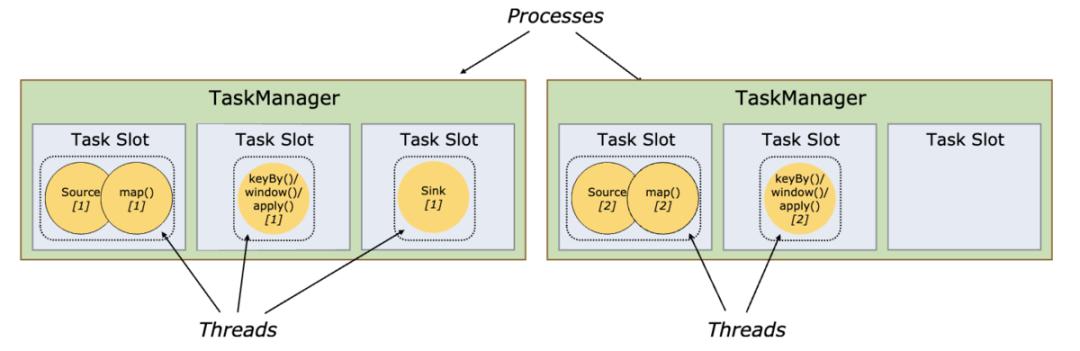 文章插图
文章插图
铺垫了这么多 , 接下来就通过源码简单看看算子链产生的条件 , 以及它是如何在 Flink Runtime 中实现的 。
逻辑计划中的算子链对 Flink Runtime 稍有了解的看官应该知道 , Flink 作业的执行计划会用三层图结构来表示 , 即:
- StreamGraph —— 原始逻辑执行计划
- JobGraph —— 优化的逻辑执行计划(Web UI 中看到的就是这个)
- ExecutionGraph —— 物理执行计划
private List createChain(Integer startNodeId,Integer currentNodeId,Map hashes,List> legacyHashes,int chainIndex,Map> chainedOperatorHashes) {if (!builtVertices.contains(startNodeId)) {List transitiveOutEdges = new ArrayList();List chainableOutputs = new ArrayList();List nonChainableOutputs = new ArrayList();StreamNode currentNode = streamGraph.getStreamNode(currentNodeId);for (StreamEdge outEdge : currentNode.getOutEdges()) {if (isChainable(outEdge, streamGraph)) {chainableOutputs.add(outEdge);} else {nonChainableOutputs.add(outEdge);}}for (StreamEdge chainable : chainableOutputs) {transitiveOutEdges.addAll(createChain(startNodeId, chainable.getTargetId(), hashes, legacyHashes, chainIndex + 1, chainedOperatorHashes));}for (StreamEdge nonChainable : nonChainableOutputs) {transitiveOutEdges.add(nonChainable);createChain(nonChainable.getTargetId(), nonChainable.getTargetId(), hashes, legacyHashes, 0, chainedOperatorHashes);}List> operatorHashes =chainedOperatorHashes.computeIfAbsent(startNodeId, k -> new ArrayList<>());byte[] primaryHashBytes = hashes.get(currentNodeId);OperatorID currentOperatorId = new OperatorID(primaryHashBytes);for (Map legacyHash : legacyHashes) {operatorHashes.add(new Tuple2<>(primaryHashBytes, legacyHash.get(currentNodeId)));}chainedNames.put(currentNodeId, createChainedName(currentNodeId, chainableOutputs));chainedMinResources.put(currentNodeId, createChainedMinResources(currentNodeId, chainableOutputs));chainedPreferredResources.put(currentNodeId, createChainedPreferredResources(currentNodeId, chainableOutputs));if (currentNode.getInputFormat() != null) {getOrCreateFormatContainer(startNodeId).addInputFormat(currentOperatorId, currentNode.getInputFormat());}if (currentNode.getOutputFormat() != null) {getOrCreateFormatContainer(startNodeId).addOutputFormat(currentOperatorId, currentNode.getOutputFormat());}StreamConfig config = currentNodeId.equals(startNodeId)? createJobVertex(startNodeId, hashes, legacyHashes, chainedOperatorHashes): new StreamConfig(new Configuration());setVertexConfig(currentNodeId, config, chainableOutputs, nonChainableOutputs);if (currentNodeId.equals(startNodeId)) {config.setChainStart();config.setChainIndex(0);config.setOperatorName(streamGraph.getStreamNode(currentNodeId).getOperatorName());config.setOutEdgesInOrder(transitiveOutEdges);config.setOutEdges(streamGraph.getStreamNode(currentNodeId).getOutEdges());for (StreamEdge edge : transitiveOutEdges) {connect(startNodeId, edge);}config.setTransitiveChainedTaskConfigs(chainedConfigs.get(startNodeId));} else {chainedConfigs.computeIfAbsent(startNodeId, k -> new HashMap());config.setChainIndex(chainIndex);StreamNode node = streamGraph.getStreamNode(currentNodeId);config.setOperatorName(node.getOperatorName());chainedConfigs.get(startNodeId).put(currentNodeId, config);}config.setOperatorID(currentOperatorId);if (chainableOutputs.isEmpty()) {config.setChainEnd();}return transitiveOutEdges;} else {return new ArrayList
- 高像素|加持高像素只为解析力?vivo S7丛林秘境展对样张细节的要求更严苛
- 启动|拼多多深入布局母婴产业带 补贴+直播启动“母婴产品溯源”行动
- 《深入理解Java虚拟机》:对象创建、布局和访问全过程
- 用了就停不下来,解析全网视频,不仅免费还能下载
- 深入理解Netty编解码、粘包拆包、心跳机制
- 详解mysql执行计划
- 在美国当快递小哥赚钱吗?西瓜视频解析除了努力,运气也很重要
- 标识|食品行业工业互联网标识解析二级节点、“星火·链网”骨干节点在漯河上线
- 《深入理解Java虚拟机》:锁优化
- Lock、Synchronized锁区别解析