30系列显卡抢不到,为了训练大型CNN,我该不该入手2080 Ti?
 文章插图
文章插图
作者 | 青暮
截至2020年11月 , NVidia RTX 3090和3080显卡仍然非常短缺 。 而读者们肯定也很好奇 , 30系列GPU与20系列相比 , 在训练AI模型上的表现如何 。 由于新系列显卡稀缺 , 很少有人可以做基准测试 。
近日 , reddit上的一位博主u/xxx-symbol近期晒出了自己做的基准测试结果 , Ta以TensorFlow Docker容器作为主要变量 , 对比了2080 Ti、3090和3080显卡在ResNet上的训练表现 , 对挑选好用的炼丹神器而言 , 是个不错的参考 。 而Ta仅选用TensorFlow作为框架 , 是因为目前PyTorch还不支持3080和3090显卡 。
博主总共对3到7个不同的TensorFlow容器进行了基准测试 , 并在TensorFlow 1.x和TensorFlow 2.x NGC容器中测试了4种不同的ResNet变体 。 这四种变体分别标记为Resnet50、resnet50、resnext101-32x4d、se-resnext101-32x4d , 具体的GitHub地址和模型配置见参考资料 。 测试设计的变量有4个 , 显卡型号、TF容器、批量大小和XLA优化 。
测试数据如下图所示 , 例如 , 图中标记的740表示:使用2080 Ti显卡、TensorFlow v1 20.10容器、批量160、XLA优化时 , 训练速度为740img/s(每秒740张图像) , 记为(2080 Ti , 20.10 TF v1 , 160 , XLA) , 使用的网络架构是Resnet50(右上角) 。 “mem lim”表示内存过载(批量太大) , “fail”表示训练失败 。 完整数据表格见文末 。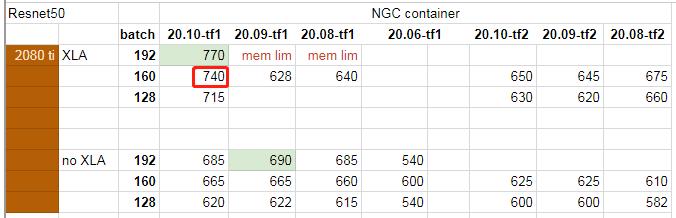 文章插图
文章插图
此外 , 在resnet50、resnext101-32x4d、se-resnext101-32x4d上 , 博主还测试了A100和V100的性能 , 不过测试数据只有一个 。
1 参数
所有测试均采用了自动混合精度训练 , 也称为FP16训练 。 如今 , 按照测试数据来看 , 至少在Volta系列显卡上训练已经没有比较意义 。
显卡
在Resnet50和resnet50上 , 三款显卡的测试结果为2080 Ti<3080<3090;在resnext101-32x4d、se-resnext101-32x4d上 , 三款显卡的测试结果为3080<2080 Ti<3090 。
TensorFlow Docker容器
从结果来看 , 使用不同的TensorFlow容器 , 显卡的性能差异很大 。 对于3080和3090显卡 , TensorFlow官方仅支持20.10以上版本的 NGC容器 。 但实际上在20.08的容器上 , 通常能获得比20.09容器更好的性能 , 有时甚至能超越20.10容器 。
总体而言 , 在ResNet50上 , 20.10容器好于20.08容器;在resnext101-32x4d和se-resnext101-32x4d上 , 20.08容器好于20.10容器 。
【30系列显卡抢不到,为了训练大型CNN,我该不该入手2080 Ti?】批量大小
训练速度和批量大小有一定关系 。 通常随着批量增加 , 训练速度一开始会随着增加 , 但增加幅度很小 , 并且会在某个批量下达到峰值 , 随后增加批量训练速度会降低 。 如果批量太大 , 会导致内存过载 。
不过最重要的 , 还是探索3090相对于3080的2.4倍内存带来的优势 , 这也是3090如此香的原因 。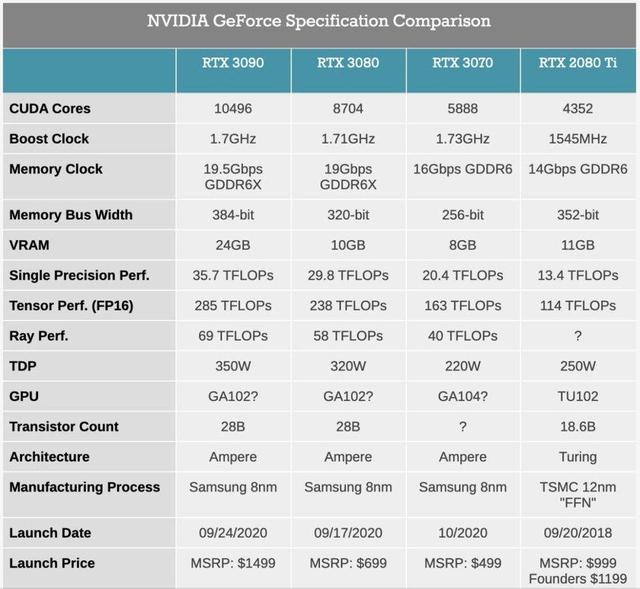 文章插图
文章插图
30系列显卡和2080 Ti的参数表
在相近的批量大小下 , 3090的训练速度有时不会比3080快多少 。 但是3090的批量大小可以超过3080的2.4倍 , 因为批量大小和激活值占用的空间相关 , 而模型和梯度大小具有固定的内存消耗 , 这让3090能取得比3080大得多的训练速度 。 比如 , 在Resnet50上 , (3080 , XLA优化 , 20.10容器 , TF v1)的最高训练速度是1052img/s(批量160) , (3090 , XLA优化 , 20.10容器 , TF v1)的最高训练速度是1355img/s(批量448) 。
XLA优化
博主还探索了XLA优化对训练性能的影响 。 不知什么原因 , 在NGC 20.09 TF v1容器上 , RTX 3080/3090在XLA优化情况下的性能较差 。 比如 , 在Resnet50上 , (3090 , XLA优化 , 20.09容器 , TF v1 , 448)的训练速度为765img/s , (3090 , 无XLA优化 , 20.09容器 , TF v1 , 448)的训练速度为895img/s 。 博主表示 , Ta会提醒TensorFlow开发人员这一点 。
A100/V100在resnet50、resnext101-32x4d、se-resnext101-32x4d三个架构上 , V100都取得了和3090相似的性能 , 而A100的表现基本都达到V100的两倍 。 另一位博主Tim Dettmers的测试数据与上述结论不谋而合 。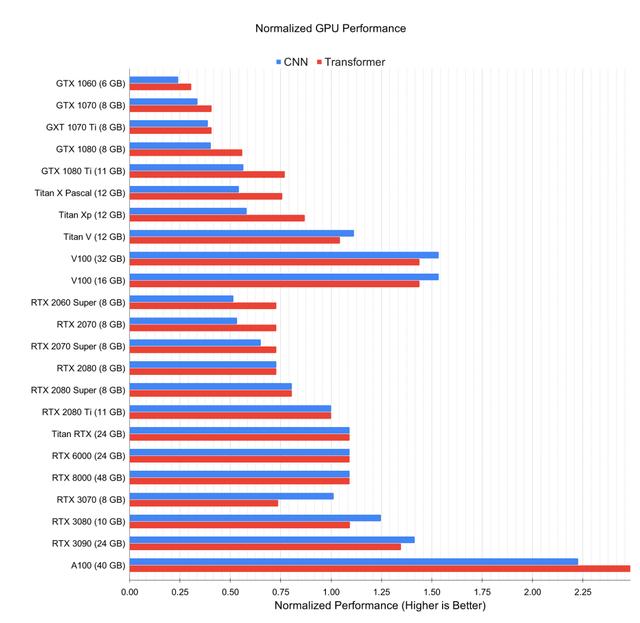 文章插图
文章插图
相对于RTX 2080 Ti的归一化GPU深度学习性能 。
2 结论
如果打算训练大型卷积神经网络 , 3090比V100更好 , 并且在性价比上肯定更具优势 。 而且因为有了更大的内存 , 在3090上可以运行更大的网络 , 而且训练批量更大 , 训练速度也更快 。
- 看不上|为什么还有用户看不上华为Mate40系列来看看内行人怎么说
- 采用|消息称一加9系列将推出三款新机,新增一加9E
- 视频社会生产力报告|视频社会雏形已成,绿厂或凭这技术抢占先机
- 系列|首销300000台!红米Note 9系列,或许可以说恭喜你了?
- 系列|联想碰瓷Redmi后正式复活乐檬手机!乐檬K12系列即将到来
- 热度|抢注商标,是蹭热度还是不要脸?
- 系列|Redmi Note9系列三剑客来袭,差别到底有多大?该如何选择?
- 超强|RedmiNote9系列发布!天玑800U赋予超强5G性能
- 回顾|华为P系列回顾
- 情况|刚发布就卖出30万台:红米Note9系列稳了,销售情况追赶前代