程序员失业第一步?斯坦福研究员用AI从编译器反馈中学习改Bug( 二 )
本文的步骤如下:
1、从GitHub和Codeforce等在线资源中收集未带标签的有效程序(上图 左) 。
2、设计随机程序破坏程序代码(例如 , 删除/插入/替换token) , 并破坏未标记程序(上图 中) 。
3、损坏的程序会报错(上图 右) 。
这样 , 人们就可以创建许多新的程序修复示例。
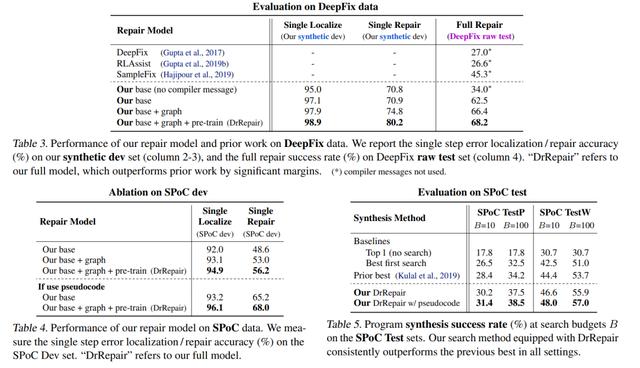
程序Bug修复模型本文在两个基准任务上应用和评估的修复模型(称为DrRepair):
- 纠正学生编写的C程序(DeepFix数据集)
- 纠正C ++程序合成的输出(SPoC数据集)
 文章插图
文章插图3 应用
应用于DeepFix(修正学生程序)
在DeepFix中 , 任务是更正学生在入门编程课中编写的C程序 , 以便它们能通过编译 。 输入程序可能有多行报错 , 因此需要迭代应用修复模型 , 一次解决一个报错 。
 文章插图
文章插图例如 , 上图显示了DeepFix中的示例程序 , 该程序有一个编译器错误 , 指出“i未声明” 。
这时应用修复模型DrRepair就派上用场了 , 它通过插入以下声明来修复此错误:i在第5行中 。
完成此修复后 , 还有另外一个错误 , 该错误为
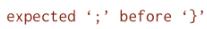 文章插图
文章插图。
再次应用修复模型:这次 , DrRepair模型在第12行中插入了分号 , 程序编译成功!
这种方法也即是迭代优化的思想:逐步运行修复模型并逐步修复报错 。
使用报错信息 , 程序反馈图和自监督的预训练有什么影响?
在DeepFix上研究的现有修复系统未使用编译器报错信息 , 它们旨在直接将有Bug的代码转换为固定代码 。
为了首先查看使用报错信息的效果,本文尝试从系统中删除所有技术:使用编译器消息 , 程序反馈图和预训练 。
下图中没有编译器的模型版本在DeepFix上实现了34%的修复精度 , 与现有系统相当 。 现在将编译器提示信息添加到输入中 , 作者发现该模型实现了更好的性能提升和泛化性(准确度为62.5%) 。
这表明 , 通过访问报错信息 , 模型可以基于反馈学习正确的归纳偏差来修复代码 。
 文章插图
文章插图接下来 , 作者添加了程序反馈图和自监督的预训练 。 作者发现这两者都作出了进一步的性能提升(“ours: base+graph” 以及“ours: base+graph+pretrain”) , 并且本文的最终系统可以修复DeepFix中68.2%的含Bug程序!
应用于SPoC(自然语言编码)
程序合成 , 特别是可以将自然语言描述(例如英语)转换为代码(例如Python , C ++)的系统是很有用的 , 因为它们可以帮助更多的人使用编程语言 。
在SPoC(伪代码-to-代码)中 , 任务是从伪代码(程序的自然语言描述)合成C ++代码实现 。
 文章插图
文章插图但是 , 现有合成器(应用于SPoC的机器翻译模型)遇到的一个挑战是它们倾向于输出不一致的代码 , 这些代码无法编译 , 例如 , 在上图中 , 变量i在合成代码中被声明了两次 。
作者发现可以将程序修复模型应用于此无效代码 , 并将其修复为正确的代码 , 从而帮助完成程序合成任务 。
在对SPoC的评估中 , 使用本文的修复模型可使最终合成成功率从现有系统的34%提高到37.6% 。
4 总结
在这项工作中 , 作者研究了如何使用机器学习来修复报错信息中的程序 , 并提出了三个主要见解:
- 报错信息对学习程序Bug修复而言至关重要 。
- 程序反馈图(代码和错误消息的共同表示)有助于对修复的原因进行建模(例如 , 跟踪引起报错的变量) 。
- 自监督学习使人们能够将免费获取的、未标记的程序(例如GitHub开放代码)转换成有用的程序修复训练示例 。
本文GitHub上源代码/数据链接:
最后需要指出的是 , 本文只是AI从编译器反馈中学习修改代码Bug的一项研究工作 , 还远远不能用于实际生产环境开发中 。
这只是程序员开发AI程序让自己失业的远大理想的第一步~
参考链接:
文末附上两种祖传无Bug的秘法:
秘法1:佛祖保佑~
- 互联网|苏宁跳出“零售商”重组互联网平台业务 融资60亿只是第一步
- 现状|程序员现状揭秘:平均年薪20.36万,Java人才需求量最大
- 联网时代|34岁转行做程序员是否还有成功的机会
- 程序员学英语第1天——JavaScript 程序测试的介绍1
- 这些错误,程序员经常会犯,你了解过吗?
- 睿哲信息:想做跨境电商,第一步你千万不能选错
- 程序员面试主要看哪些 该怎么准备面试内容
- 中国程序员最容易发音错误的单词,看看你有没有读错
- 程序员大佬整理的300本编程电子书,整整12个G你想学的都有
- 程序员年包90w,回老家被月薪3800表哥怼,催他赶紧上岸