Python|知识图谱——用Python代码从文本中挖掘信息的强大数据科学技术( 五 )
plt.show()
输出: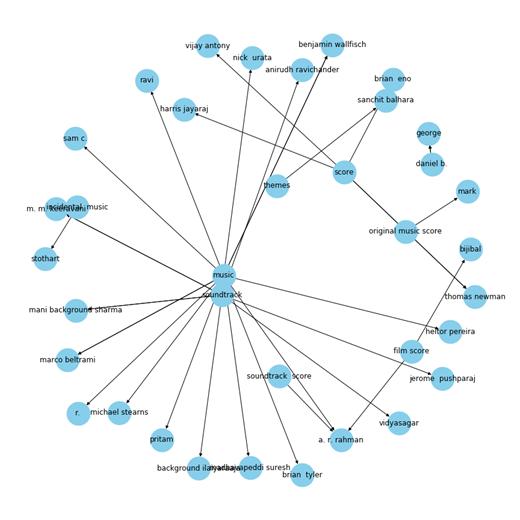 文章插图
文章插图
这是一个更清晰的图谱 。 这里箭头指向作曲家 。 例如 , A.R.拉赫曼是一位著名的音乐作曲家 , 在上面的图谱中 , 他有诸如“电影原声带”、“电影配乐”和“音乐”这样的实体 。
再看更多的关系 。
因为编写在任何一部电影中都占重要角色 , 所以我想把“编写”关系的图谱可视化:
G=nx.from_pandas_edgelist(kg_df[kg_df['edge']=="written by"], "source", "target",
edge_attr=True, create_using=nx.MultiDiGraph())
plt.figure(figsize=(12,12))
pos = nx.spring_layout(G, k=0.5)
nx.draw(G, with_labels=True, node_color='skyblue', node_size=1500, edge_cmap=plt.cm.Blues, pos= pos)
plt.show()
输出: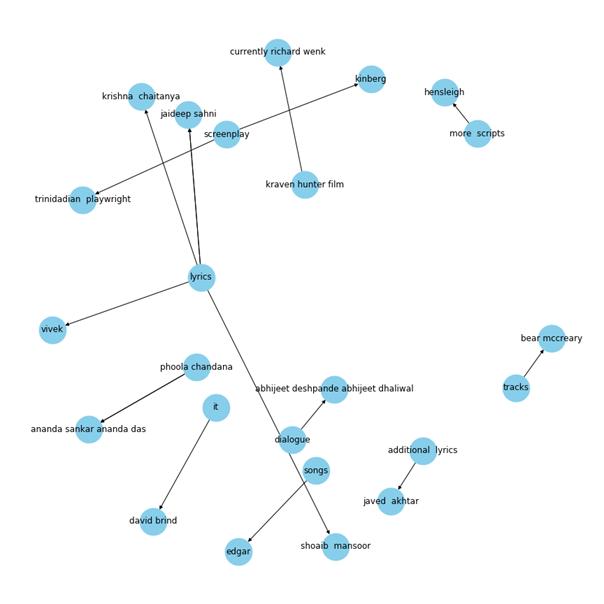 文章插图
文章插图
太棒了!这张知识图谱给了我们一些非同寻常的信息 。 像Javed Akhtar、Krishna Chaitanya和Jaideep Sahni都是著名的作词家 , 这张图谱很好地捕捉到了这种关系 。
看看另一个重要谓语的知识图谱 , 即“释放(发布于)”:
G=nx.from_pandas_edgelist(kg_df[kg_df['edge']=="released in"], "source", "target",
edge_attr=True, create_using=nx.MultiDiGraph())
plt.figure(figsize=(12,12))
pos = nx.spring_layout(G, k=0.5)
nx.draw(G, with_labels=True, node_color='skyblue', node_size=1500, edge_cmap=plt.cm.Blues, pos= pos)
plt.show()
输出: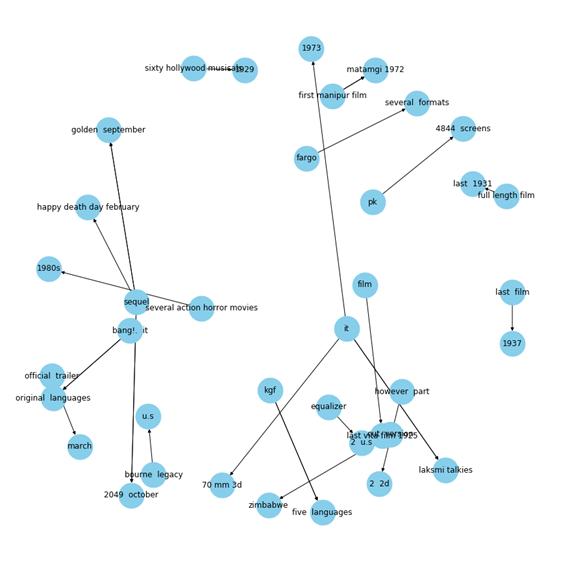 文章插图
文章插图
我们可以在这个图谱中看到不少有趣的信息 。 例如这种关系:“20世纪80年代上映的几部动作恐怖电影”和“4844块屏幕上放映的格斗电影” 。 这些都是事实 , 这张图谱告诉我们 , 确实可以从文本中挖掘出这些事实 。 真是太神奇了! 文章插图
文章插图
结语
在本文中 , 我们学习了如何以三元组的形式 , 从给定文本中提取信息 , 并借此构建知识图谱 。
然而 , 我们只使用恰好有两个实体的句子 。 即使这样 , 也能够建立信息量很大的知识图谱 , 所以想象一下它的潜力!
我鼓励大家探索这个领域的信息抽取 , 学习更复杂关系的提取 。 如果你有任何疑问或想要分享你的想法 , 请随时留言 。 文章插图
文章插图
留言点赞关注
我们一起分享AI学习与发展的干货
【Python|知识图谱——用Python代码从文本中挖掘信息的强大数据科学技术】如转载 , 请后台留言 , 遵守转载规范
- 快递|国家邮政局:推动邮政快递行业由劳动密集型向知识密集型发展
- 手机|原来微信一键就能拼接长图,朋友圈可发送几十张照片,涨知识了
- 双行合一|关于Word我们要了解的知识(12)
- 经济总量|美国经济总量世界第一,究竟是靠哪些产业支撑的呢?看完长知识了
- 电脑知识|北大青鸟:零基础学电脑从哪里入手
- 打击|莫让知识产权侵权“打击”了家电行业的创新积极性
- 告诉|阿里大佬告诉你如何一分钟利用Python在家告别会员看电影
- Python源码阅读-基础1
- Python调用时使用*和**
- 如何基于Python实现自动化控制鼠标和键盘操作