使用Xpath进行数据爬虫,一个超好用的插件工具值得下载
前言使用python进行页面解析时 , 有三种方式:正则表达式、bs4、以及Xpath 。 其中Xpath是三种方法中最简便也是用得最广的一种 。 但是对于新手来说 , 编写代码来定位标签仍然是一个不小的难题 。 在我第一次使用Xpath的时候 , 试错了将近2h也没搞好标签定位 , 这里介绍我的第一个项目时 , 顺带推销个超好用的Xpath定位工具——插件:XPath Helper Chrome(但是个人的看法 , 还是要尽量自己写 , 不能仅仅依靠Helper , 可以作为一种对比工具 , 看你的答案和Helper有什么区别?)
一、Xpath是什么度娘说:XPath即为XML路径语言(XML Path Language) , 它是一种用来确定XML文档中某部分位置的语言 。 用于定位HTML页面中的某一元素 。
通过一张网图我们可以清晰看到HTML的组成部分 , 一般我们用Xpath确定路径来定位树形结构中的某个叶子节点 。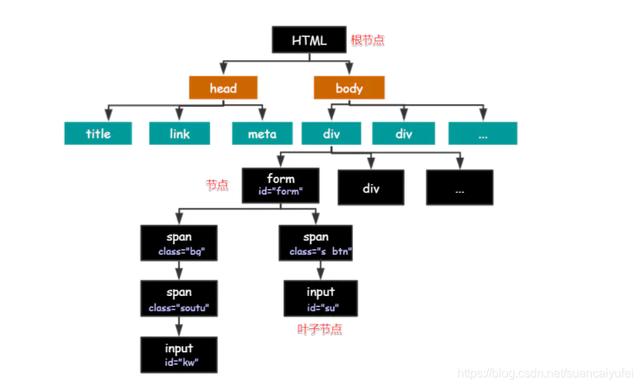 文章插图
文章插图
使用XPath Helper Chrome我们能快速得出节点的绝对路径和相对路径 。 (用电脑截图有点问题 , 此处继续借用网图)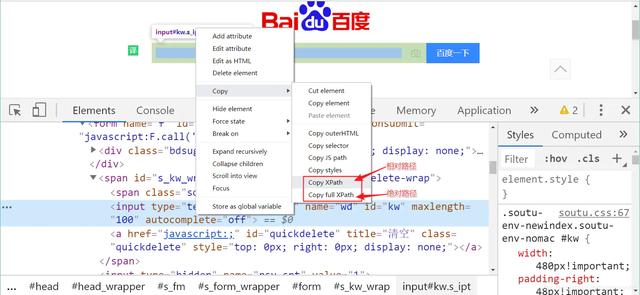 文章插图
文章插图
绝对路径比较直观、好理解 , 但是不灵活 , 相当于从一棵树的底部往上数 , 经过哪个树根、哪片树叶都数的清清楚楚 。 一个绝对路径的例子:/html/body/div[1]/div[3]/div[1]/div[3]/div[1]/h3/a
而相对路径则是我们最常使用的一种 , 以“//”开头 , 从任意节点开始 , 一般我们会选取一个可以唯一定位到的元素开始写 , 可以增加查找的准确性 。 文章插图
文章插图
二、使用步骤1.爬取网页PPT的一个实践环境搭建:pycharm2020.2版 , 加载requests模块、lxml模块、os模块 。 爬取对象:一个网页可供免费下载PPT的第一页 。
代码如下:
import requestsfrom lxml import etreeimport osif __name__ =="__main__":url = ''headers = {'User_Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36'}response = requests.get(url=url,headers=headers)response.encoding = 'utf-8'page_text = response.textif len(page_text)>100:print('页面数据爬取成功')#实例化一个对象tree = etree.HTML(page_text)list = tree.xpath('//*[@id="container"]/div')#创建一个文件夹if not os.path.exists('./PPT素材4'):os.mkdir('./PPT素材4')#遍历数据解析加进行局部解析for ppt_detail in list:ppt_name = ppt_detail.xpath('./p/a/text()')[0]+'.rar'ppt_link = "http:"+ppt_detail.xpath('./p/a/@href')[0]#获得了每个ppt的链接 , 向每个链接发起请求ppt_response = requests.get(url=ppt_link,headers=headers)ppt_page_text = ppt_response.text#实例化Xpath对象tree2 = etree.HTML(ppt_page_text)list2_link = tree2.xpath('//*[@id="down"]/div[2]/ul/li[1]/a/@href')[0]ppt_downlode =requests.get(url=list2_link,headers=headers).content#获得了该页ppt的下载链接 , 应该进行持久化储存PPt_path = 'PPT素材4/' + ppt_namewith open(PPt_path, 'wb') as fp:fp.write(ppt_downlode)print(ppt_name, '下载成功!!!')2.数据存储 文章插图
文章插图
总结简单地介绍一个工具 , 对Xpath的两种路径进行说明 , 并使用Xpath来进行爬虫实践 。
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取
【使用Xpath进行数据爬虫,一个超好用的插件工具值得下载】github地址:后台私信小编01即可
- 会员|美容院使用会员管理软件给顾客更好的消费体验!
- 桌面|日常使用的软件及网站分享 篇一:几个动态壁纸软件和静态壁纸网站:助你美化你的桌面
- QuestMobile|QuestMobile:百度智能小程序月人均使用个数达9.6个
- 轻松|使用 GIMP 轻松地设置图片透明度
- 电池容量|Windows 自带功能查看笔记本电脑电池使用情况,你的容量还好吗?
- 信服|深信服何朝曦:安全不能只面向静态风险进行建设,应该从"面向风险"转向"面向能力"
- 撕破脸|使用华为设备就罚款87万,英政府果真要和中国“撕破脸”?
- 冲突|智能互联汽车:通过数据托管模式解决数据使用方面的冲突
- 鼓励|(经济)商务部:鼓励引导商务领域减少使用塑料袋等一次性塑料制品
- 机身|轻松使用一整天,OPPO K7x给你不断电体验