使用Transformers和Faiss构建语义搜索引擎( 二 )
我检索了论文的摘要、标题、引用、发表年份和ID 。 我做了最少的数据清理 , 比如删除没有摘要的论文 。 数据是这样的: 文章插图
文章插图
导入Python包并从S3读取数据
让我们导入所需的包并读取数据 。 该文件是公开的 , 所以您可以在谷歌Colab上运行代码 , 或者通过访问GitHub repo在本地运行代码!
# Used to import data from S3.import pandas as pdimport s3fs# Used to create the dense document vectors.import torchfrom sentence_transformers import SentenceTransformer# Used to create and store the Faiss index.import faissimport numpy as npimport pickle# Used to do vector searches and display the results.from vector_engine.utils import vector_search, id2details# Use pandas to read files from S3 buckets!df = pd.read_csv('s3://vector-search-blog/misinformation_papers.csv')使用Sentence Transformers对文档进行矢量化
接下来 , 我们对论文摘要进行编码 。 Sentence Transformers提供了许多预先训练过的模型 , 其中一些可以在这个电子表格中找到 。 在这里 , 我们将使用base-nli- stbs -mean-tokens模型 , 该模型在语义文本相似度任务中表现出色 , 而且比BERT要快得多 , 因为它要小得多 。
我们将做如下的工作:
· 通过将模型名作为字符串传递来实例化transformer 。
· 切换到GPU , 如果它是可用的 。
· 使用' .encode() '方法对所有论文摘要进行向量化 。
# Instantiate the sentence-level DistilBERTmodel = SentenceTransformer('distilbert-base-nli-stsb-mean-tokens')# Check if CUDA is available ans switch to GPUif torch.cuda.is_available():model = model.to(torch.device("cuda"))print(model.device)# Convert abstracts to vectorsembeddings = model.encode(df.abstract.to_list(), show_progress_bar=True)建议使用GPU对文档进行矢量转换 。
用Faiss索引文档
Faiss包含的算法可以在任意大小的向量集合中搜索 , 甚至是那些无法放入RAM的向量 。 要了解更多关于Faiss的信息 , 你可以在arXiv阅读他们的论文 。
Faiss是围绕索引对象构建的 , 索引对象包含可搜索向量 , 有时还对其进行预处理 。 它处理一个固定维数d的向量集合 , 通常是几个10到100 。
Faiss只使用32位浮点矩阵 。 这意味着在构建索引之前 , 我们必须更改输入的数据类型 。
在这里 , 我们将使用IndexFlatL2索引来执行暴力的L2距离搜索 。 它在我们的数据集上工作得很好 , 但是 , 对于大型数据集 , 它会非常慢 , 因为它会随着索引向量的数量线性扩展 。 Faiss也提供快速索引!
要用抽象向量创建索引 , 我们将:
将抽象向量的数据类型更改为float32 。
建立一个索引 , 并传递它将要操作的向量的维数 。
将索引传递给IndexIDMap , 该对象使我们能够为索引的向量提供id的自定义列表 。
将抽象向量及其ID映射添加到索引 。 在我们的例子中 , 我们将从Microsoft Academic Graph将向量映射到它们的论文id 。
为了测试索引是否按预期工作 , 我们可以使用索引向量查询它 , 并检索其最相似的文档以及它们的距离 。 第一个结果应该是我们的查询!
# Step 1: Change data typeembeddings = np.array([embedding for embedding in embeddings]).astype("float32")# Step 2: Instantiate the indexindex = faiss.IndexFlatL2(embeddings.shape[1])# Step 3: Pass the index to IndexIDMapindex = faiss.IndexIDMap(index)# Step 4: Add vectors and their IDsindex.add_with_ids(embeddings, df.id.values)# Retrieve the 10 nearest neighboursD, I = index.search(np.array([embeddings[5415]]), k=10)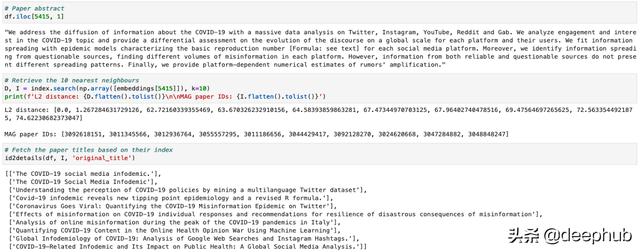 文章插图
文章插图
由于我们使用索引向量查询Faiss , 因此第一个结果必须是查询 , 并且距离必须等于零!
搜索用户输入的查询
让我们尝试为新搜索查询找到相关的学术文章 。在此示例中 , 我将使用WhatsApp的第一段查询索引 , 这可以从揭穿事实核查的故事中受益 , 以减少错误信息?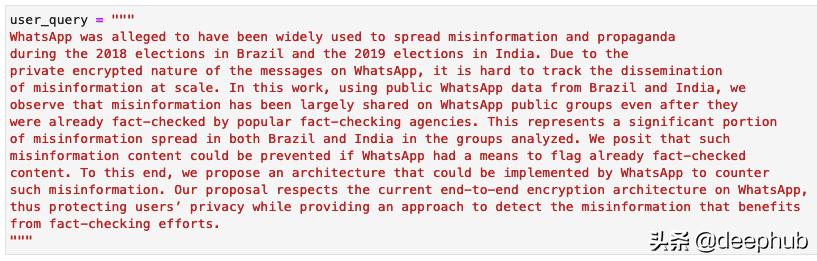 文章插图
文章插图
要检索学术文章以进行新的查询 , 我们必须:
· 使用与抽象向量相同的句子DistilBERT模型对查询进行编码 。
· 将其数据类型更改为float32
· 使用编码的查询搜索索引
为了方便起见 , 我将这些步骤包装在vector_search()函数中 。
import numpy as npdef vector_search(query, model, index, num_results=10):"""Tranforms query to vector using a pretrained, sentence-levelDistilBERT model and finds similar vectors using FAISS.Args:query (str): User query that should be more than a sentence long.model (sentence_transformers.SentenceTransformer.SentenceTransformer)index (`numpy.ndarray`): FAISS index that needs to be deserialized.num_results (int): Number of results to return.Returns:D (:obj:`numpy.array` of `float`): Distance between results and query.I (:obj:`numpy.array` of `int`): Paper ID of the results."""vector = model.encode(list(query))D, I = index.search(np.array(vector).astype("float32"), k=num_results)return D, Idef id2details(df, I, column):"""Returns the paper titles based on the paper index."""return [list(df[df.id == idx][column]) for idx in I[0]]# Querying the indexD, I = vector_search([user_query], model, index, num_results=10)
- 会员|美容院使用会员管理软件给顾客更好的消费体验!
- 中国|浅谈5G移动通信技术的前世和今生
- 芯片|华米GTS2mini和红米手表哪个好 参数功能配置对比
- 桌面|日常使用的软件及网站分享 篇一:几个动态壁纸软件和静态壁纸网站:助你美化你的桌面
- QuestMobile|QuestMobile:百度智能小程序月人均使用个数达9.6个
- 二维码|村网通?澳大利亚一州推出疫情追踪二维码 还考虑采用人脸识别和地理定位
- 不到|苹果赚了多少?iPhone12成本不到2500元,华为和小米的利润呢?
- 机器人|网络里面的假消息忽悠了非常多的小喷子和小机器人
- 华为|骁龙870和骁龙855区别都是7nm芯片吗 性能对比评测
- 花15.5亿元与中粮包装握手言和 加多宝离上市又进一步?|15楼财经 | 清远加多宝