音乐人工智能的发展与思考
昨天在山西太原中北大学举行的“第八届全国声音与音乐技术会议”上做了一个Keynotes报告 , 也是三天会议keynotes中唯一一个线下报告的 。 这里 , 我就报告中关于音乐人工智能的内容 , 做下分段式的文字总结 , 分享给有兴趣了解的同仁们 。 文章插图
文章插图
图1:第八届全国声音与音乐技术会议
一、人工智能现状
自2012年以来 , 人工智能因为深度学习网络预测性能的显著提升得到了迅猛发展 , 论文发表数量在近两年更是呈现井喷 。 尽管数量众多 , 但事实上离不开程咬金的三板斧 , 即深层、隐结构和良态化 。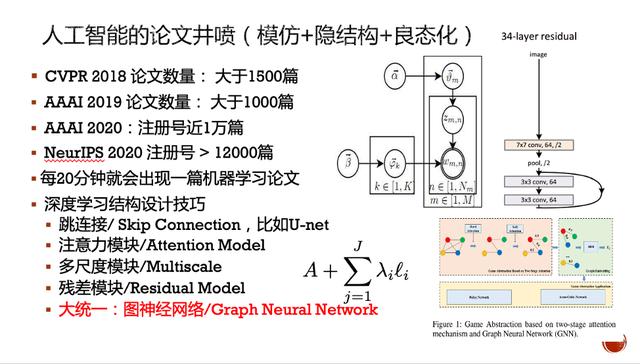 文章插图
文章插图
图2:人工智能三板斧
深层是为了模仿人的大脑结构 , 如从视网膜到视觉中枢一般认为是五层的通道 。 但人脑结构的复杂性和运作机理远没有到了解清楚的地步 , 简单的五层并不能达到人脑相应的能力 。 所以 , 人工智能想到了 , 用深层结构来实现预测 , 实际效果也确实不错 。
隐结构是因为我们观测到的内容往往是表面的 , 需要找到更多的隐特征来发现其内在的控制机理 , 所以 , 这个方向上早期是以图模型的理论和算法框架来展开研究的 。
良态化 , 因为我们处理的多数问题都是病态问题 , 即一个结果可以由多个原因引起 , 要找到真正的单个原因是一对多问题 , 也就是病态问题 。 在此前提下 , 常用的策略是引入约束条件 , 将问题限定后寻找最优解 , 即良态化 。
现在的人工智能基本上脱离不了这三个大框架的组合 。 在此前提下 , 我们能看到有保持信息在经过深层特征提取后不至于衰减的跳连接策略 , 有模拟人类能选择性关注目标的注意力选择模型 , 有模拟人可以在不同尺度下关注目标的多尺度或金字塔技巧 , 也有基于信号处理中残差熵的编码更短的残差深度模型 。 还值得注意的是 , 近两年图神经网络似乎有一统天下的想法 , 希望把隐结构、深层与良态化结合起来 。 但因为模型相对复杂 , 目前只有两层的图神经网络比较好处理 。 因此 , 图神经网络的前景还有待观望 。
除此以外 , 在音乐人工智能方面 , 还值得关注三个新的人工智能方向 。 一是元学习 。 它的发展时间其实也有五六年历史了 , 但在音乐这块可能还比较新 。 与需要大量有标签的监督学习相比 , 元学习可以用少量的、不同类型的任务集来学习新任务集的预测 。 以歌曲为例 。 它可以将每个风格下的歌曲和标签的预测看成是一个元训练样本 ,不同风格的则组成一组元训练样本集 。 通过对这组训练样本的学习 , 可以获得一组参数集 。 该参数集的用处 , 是在出现新的未知风格的歌曲和标签集时 , 可以直接调整参数集的权重来实现元学习 。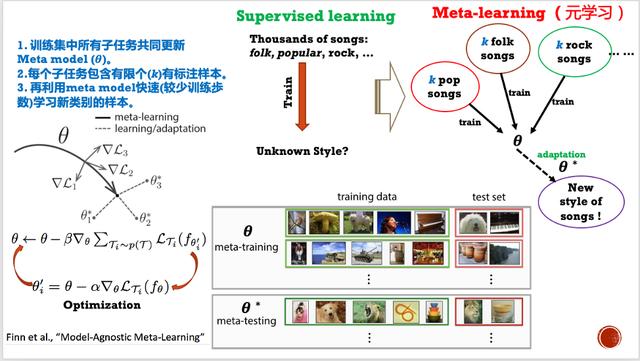 文章插图
文章插图
图3:元学习示例
其次 , 是自监督学习 。 这一方向是近两年出现的 , 它主要是希望利用大量未标注样本的结构关系来获得特征表达辅助信息 (Pretext) , 以帮助下游任务得到更好的预测 。 在图像处理中 , 常见的结构关系寻找有在图像不同位置上增加图像块 , 并标注不同图像块间的位置关系 。 另外 , 还有着色、旋转、多尺度排序等 。 而在声音与音乐方面 , 最近三年 , Zisserman教授组发表了三篇相关的工作 , 旨在发现视频中演奏乐器与音频中的语义一致性和同步性 。 他们将乐器演奏的视频帧与相同时刻的音频对应起来 , 以构造正样本;再将不同时间的音视频 , 或不同乐器声音的音视频作为负样本 。 通过构造能令正样本间距离变小、负样本间距离变大的对比损失(contrastive loss) , 并优化自监督模型 , 以获得辅助任务的有效特征表达 。 该模型可用于多个下游任务如音视频的跟踪、检测说话人说话与否 , 音源分离等 。 文章插图
文章插图
图4(a): 自监督学习在有声视频上的应用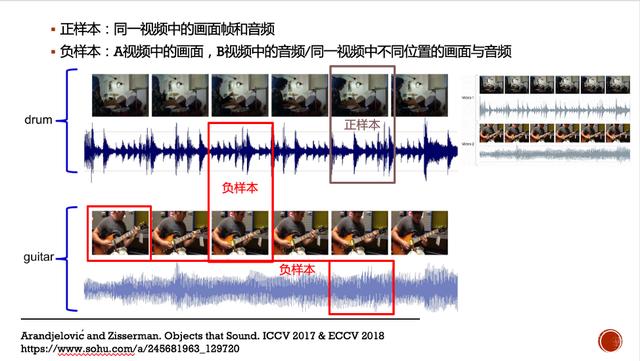 文章插图
文章插图
图4(b): 自监督学习在有声视频上的应用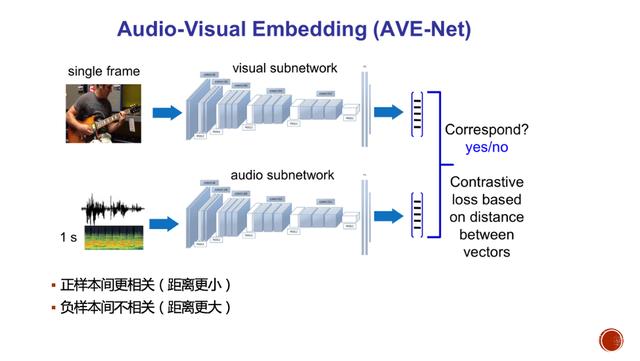 文章插图
文章插图
图4(c): 自监督学习在有声视频上的应用
第三是蒸馏学习 。 它的目的在利用教师模型来从大数据中学习一个相对粗略的特征表达 , 并基于这一结果再精细化训练一个小的学生模型 。 这一技术的好处在于 , 我们可以减少对深度学习最核心的运算硬件GPU的依赖 , 甚至可以让这些模型 , 在模型压缩后能进到手机上去处理 。 这样的话 , 就有可能更有利于实用化基于音乐人工智能的各种应用了 。
- 智能手机市场|华为再拿第一!27%的份额领跑全行业,苹果8%排在第四名!
- 会员|美容院使用会员管理软件给顾客更好的消费体验!
- 行业|现在行业内客服托管费用是怎么算的
- 人民币|天猫国际新增“服务大类”,知舟集团提醒入驻这些类目的要注意
- 国外|坐拥77件专利,打破国外的垄断,造出中国最先进的家电芯片
- 技术|做“视频”绿厂是专业的,这项技术获人民日报评论点赞
- 面临|“熟悉的陌生人”不该被边缘化
- 中国|浅谈5G移动通信技术的前世和今生
- 页面|如何简单、快速制作流程图?上班族的画图技巧get
- 桌面|日常使用的软件及网站分享 篇一:几个动态壁纸软件和静态壁纸网站:助你美化你的桌面