模型|超越谷歌 BERT!依图推出预训练语言理解模型 ConvBERT,入选 NeurIPS 2020( 二 )
【 模型|超越谷歌 BERT!依图推出预训练语言理解模型 ConvBERT,入选 NeurIPS 2020】此处卷积核是由对应的词的特征经过线性变换和 softmax 之后产生的。为了提升卷积核对于同一词在不同语境下的多样性,依图提出了如下的动态卷积
此处,输入 X 先经过线性变换生成和,同时经过卷积生成基于跨度的,由经过线性变换以及 softmax 来产生卷积核与进一步做轻量卷积,从而得到最终的输出。
在基于跨度的卷积的基础上,依图将其与原始的自注意力机制做了一个结合,得到了如图所示的混合注意力模块。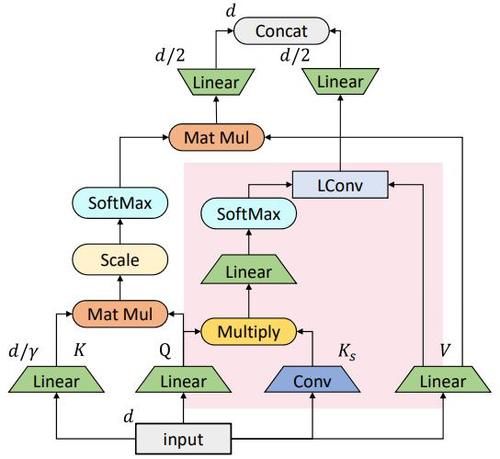
文章插图
可以看到,被标红的部分是基于跨度的卷积模块,而另一部分则是原始的自注意力模块。其中原始的自注意力机制主要负责刻画全局的词与词之间的关系,而局部的联系则由替换进来的基于跨度的卷积模块刻画。从下图 BERT 和 ConvBERT 中的自注意力模块的 attention map 可视化图对比也可以看出,不同于原始的集中在对角线上的 attention map,ConvBERT 的 attention map 不再过多关注局部的关系,而这也正是卷积模块减少冗余的作用体现。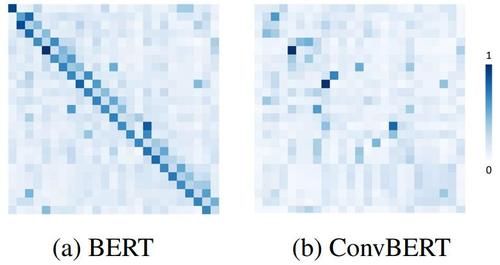
文章插图
对比 state-of-the-art 模型,ConvBERT 所需算力更少、精度更高为分析不同卷积的效果,依图使用不同的卷积得到了如下表所示的结果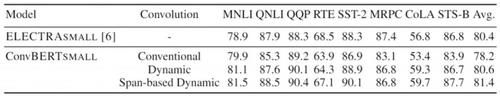
文章插图
可以看出在模型大小一致的情况下,传统卷积的效果明显弱于动态卷积。并且,本文提出的基于跨度的动态卷积也比普通的动态卷积拥有更好的性能。同时,依图也对不同的卷积核大小做了分析。实验发现,在卷积核较小的情况下,增大卷积核大小可以有效地提高模型性能。但是当卷积核足够大之后提升效果就不明显了,甚至可能会导致训练困难从而降低模型的性能。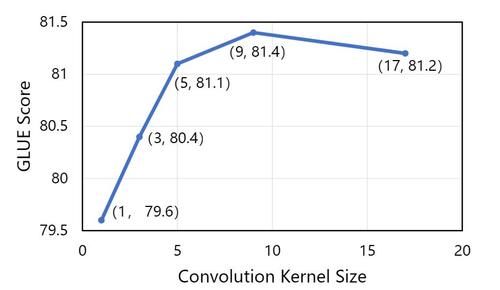
文章插图
最后,依图将提出的 ConvBERT 模型在不同的大小设定下与 state-of-the-art 模型进行了对比。值得注意的是,对小模型而言,ConvBERT-medium-small 达到了 81.1 的 GLUE score 平均值,比其余的小模型以及基于知识蒸馏的压缩模型性能都要更好,甚至超过了大了很多的 BERT-base 模型。而在大模型的设定下,ConvBERT-base 也达到了 86.4 的 GLUE score 平均值,相比于计算量是其 4 倍的 ELECTRA-base 还要高出 0.7 个点。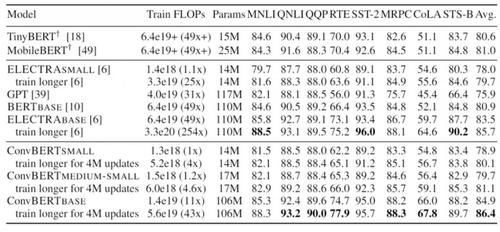
文章插图
更多实验以及算法细节可参考原文:原文链接:https://arxiv.org/pdf/2008.02496.pdf
代码地址:https://github.com/yitu-opensource/ConvBert
本文为机器之心发布,转载请联系本公众号获得授权。
------------------------------------------------
加入机器之心(全职采访人员 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com
- Facebook|谷歌、Facebook未来几周将面临更多的反垄断诉讼
- 谷歌|小米10i惊现谷歌商店,网友:这不就是我们的Redmi Note 9?
- 中国首富又换人了?马云凭100亿优势超越马化腾,网友:厉害了
- iPhone12Pro|华为再爆新机,P50Pro暗藏三大优势,全面超越iPhone12Pro
- 搞事|法国人又搞事了!将命令谷歌、脸书、亚马逊等科技公司支付数字税
- 机构|英拟设新机构监管谷歌等科技巨头
- 反垄断|好日子到头?谷歌等美企将面临美国4起诉讼,30国已站在对立面
- 倡议|谷歌、FB等签署新倡议承诺积极缴税,亚马逊、苹果缺席
- 小米|小米11将至,全面超越华为mate40?
- 超越|三季度全球智能手机销量跌幅收窄 小米首次超越苹果