上面的分析促使我们在计算一致性损失的时候,应该考虑两个输出的准确性,从而用相对准确的预测去监督另外一个预测。我们在统计中发现,对图像进行简单的图像增强后得到的结果要比进行困难的图像增强更准确。基于此,我们提出了一个非常简单的训练方式。
文章插图
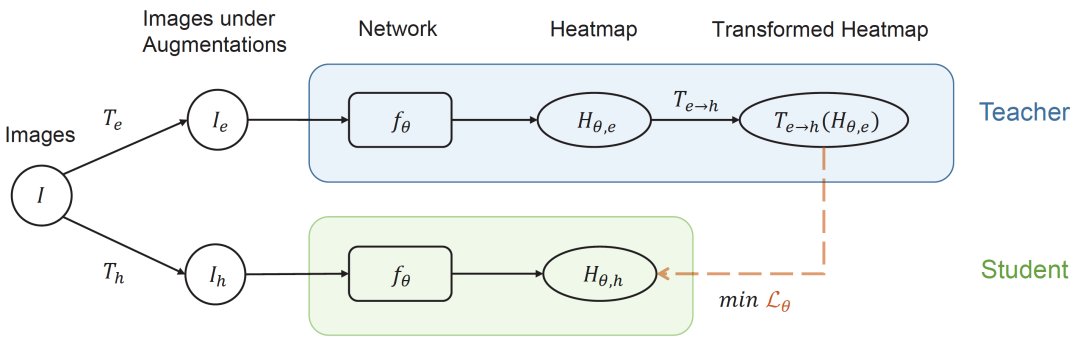
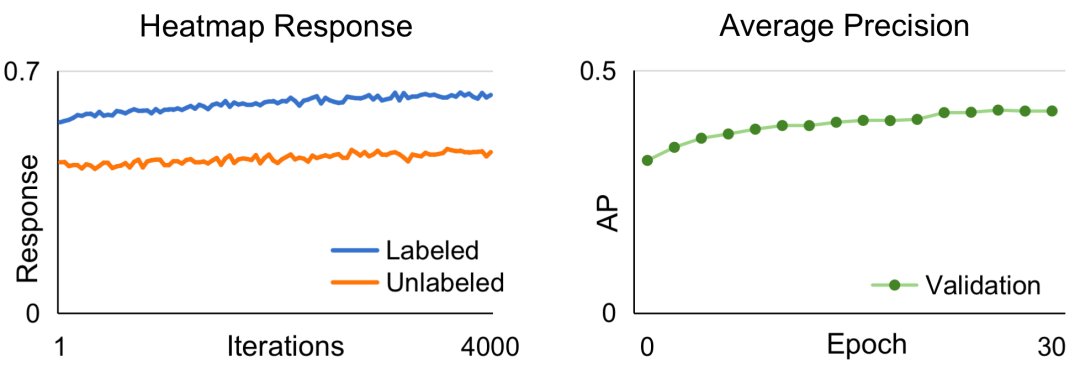
图3. 本文提出的 Easy-Hard 数据增强方法如上图所示,针对一张无标签图像,我们分别进行一次“Easy”和“Hard”的图像增强,并将其分别输入姿态估计模型预测 Heatmap。当网络接收来自于简单增强的图像时,得到的预测值被当作 Teacher,用于监督对应的接收困难增强的图像的预测。值得注意的是,这里的梯度传播是单向的,也就是说困难增强的图像的结果并不会去指导对应的简单增强的图像,从而尽可能降低因为错误的监督而导致模型退化的可能性。这种方法可以成功避免退化的问题,其训练过程和结果可参考图4。
文章插图
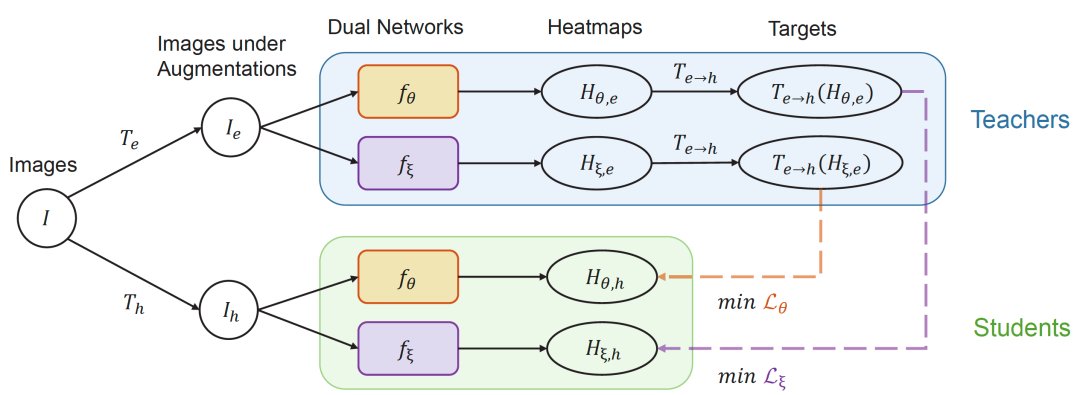
在 Easy-Hard 增强方法解决了模型退化问题的基础上,本文中进一步提出了双重网络的训练方式。双重网络通过增加 Teacher 和 Student 预测间的差异,来避免一致性训练过早收敛,从而提高了半监督学习的效果。如图5所示,该方法同时训练两个参数独立且初始化不同的网络,并且在它们之间通过无标记样本来交换信息。该方法同样使用了 Easy-Hard 增强方法来避免模型退化。具体来说,模型一在简单样本下得到的预测,将用于监督模型二在困难样本下的预测。反之亦然,模型二的预测值也同样用于指导模型一的训练,两者互为教师和学生模型。
文章插图
我们在多个数据集和多个基线方法上进行了大量的实验,验证了本文提出的训练方式可以取得非常好的效果。
文章插图
文章插图
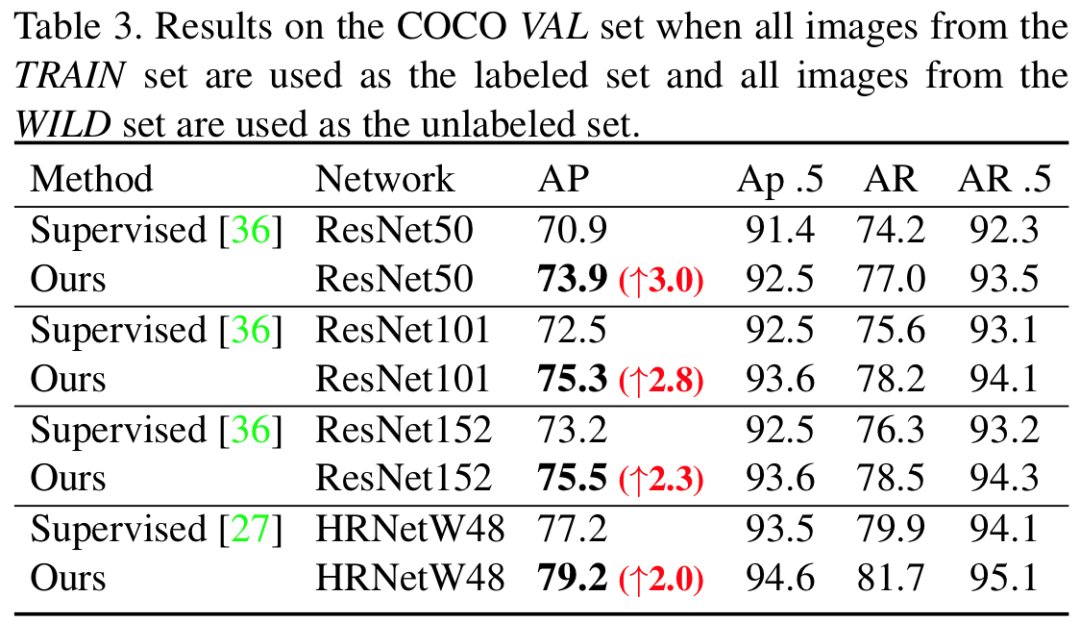
表2. COCO 数据集中使用全量标记样本,在验证集的结果
文章插图
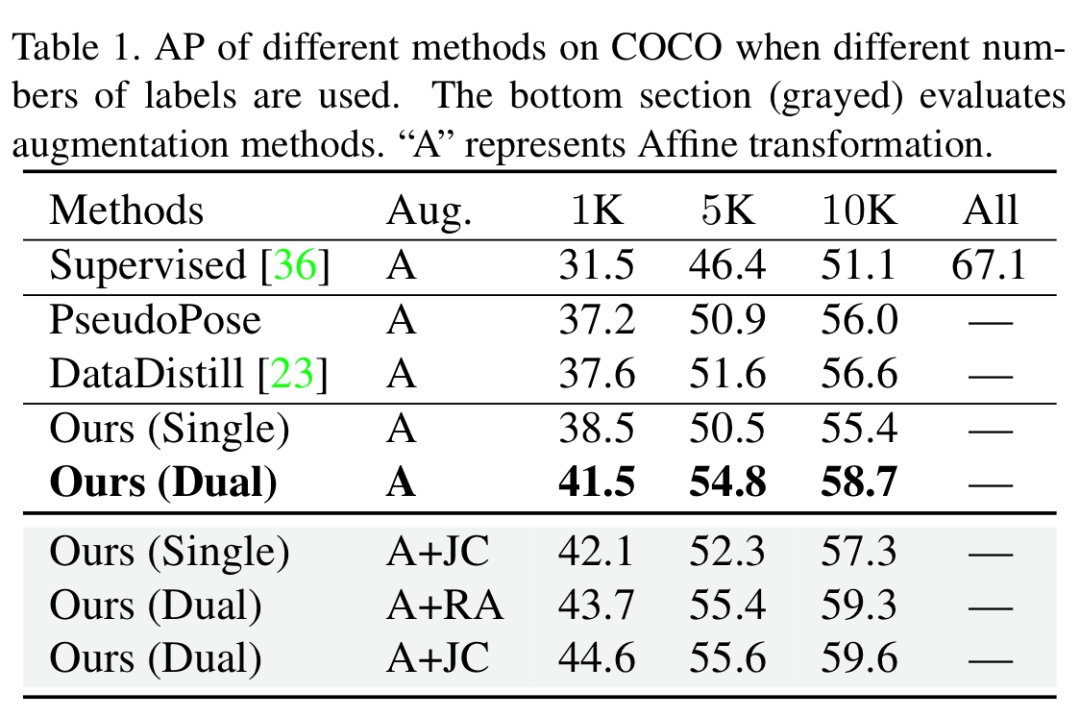
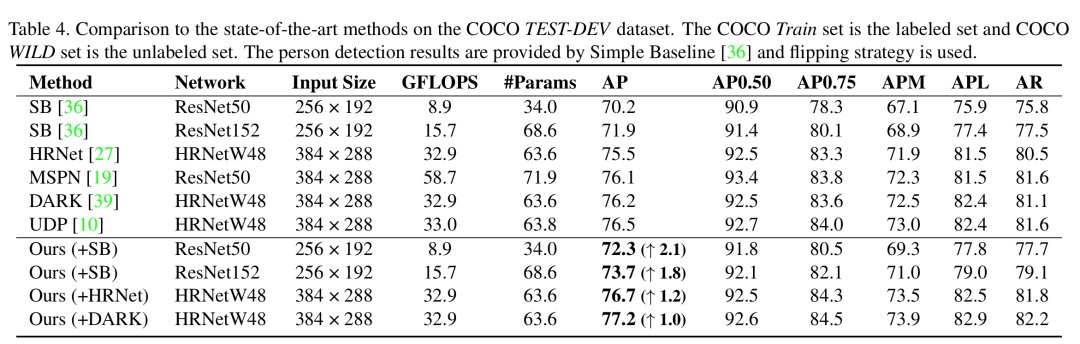
表3. COCO 数据集中使用全量标记样本,在测试集的结果在 COCO 数据集上,当只使用少量标签数据时(表1),本文的方法大约能提升8%-13%的平均精确率。如表2、表3所示,在使用训练集的全量数据时,本文方法仍然能够增加2%-3%的平均精确率。这些结果都验证了本文方法的有效性和实用性。此外,论文中还汇报了本文方法在领域自适应,模型预训练等任务中的应用结果,也取得了较显著的改善。参考文献
[1] Kihyuk Sohn, David Berthelot, Chun-Liang Li, Zizhao Zhang, Nicholas Carlini, Ekin D Cubuk, Alex Kurakin, Han Zhang, and Colin Raffel. Fixmatch: Simplifying semisupervised learning with consistency and confidence. In Advances in Neural Information Processing Systems, 2020.
[2] David Berthelot, Nicholas Carlini, Ian Goodfellow, Nicolas Papernot, Avital Oliver, and Colin A Raffel. Mixmatch: A holistic approach to semi-supervised learning. In Advances in Neural Information Processing Systems, pages 5049–5059, 2019.

文章插图
雷锋网雷锋网雷锋网
【 半监督二维人体姿态估计中的模型坍塌问题研究(代码已开源)|ICCV 2021 | 监督】