
文章插图
AI科技评论报道

文章插图
论文地址:https://arxiv.org/abs/2011.12498
目前半监督学习的方法中,结果最好的方法大多基于一致性训练(Consistency-based)[1][2]。也就是要求模型在一张图像的不同扰动(Perturbation)上产生一致的输出,从而去探索无标签图像中存在的特征。一致性损失如公式所示,
但当我们把这些方法应用到二维人体姿态估计时,我们发现大部分的一致性训练方法都遇到了模型坍塌的问题(Model Collapsing)—— 模型在有标注的图像上能够预测出正确的heatmap,但在无标注的图像上对每个像素的预测都是0。注意在这种情况下,虽然一致性损失是最小的,但模型在无标签数据上却没有学到任何有意义的信息。
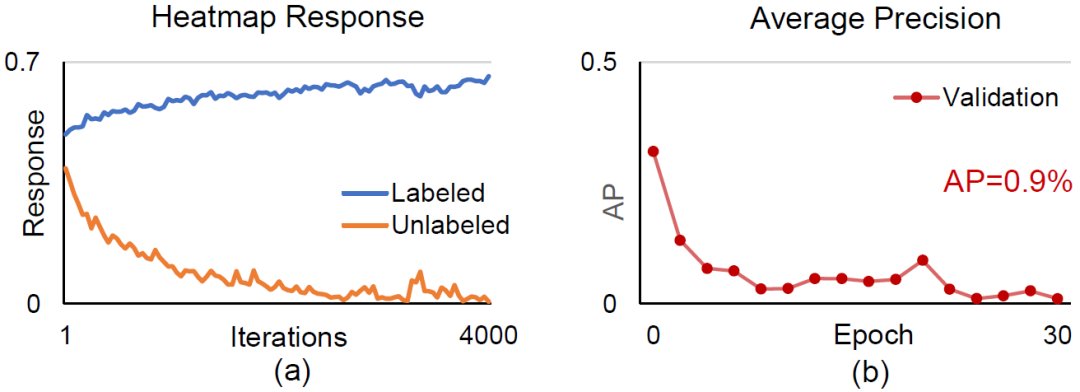
文章插图
当模型针对两个对应的像素(来自于两个 Perturbations)产生不一致的预测时,比如一个预测为1(前景),一个预测为0(背景)。经典的一致性训练方法中,试图同时更新两个预测值,从而移动决策边界,使得两者位于边界的同一侧。而因为类别不均衡问题的存在,决策边界倾向于移动到全局来看样本数目更稀疏的少数类别区域(也就是前景)。因此,随着训练的进行,我们发现越来越多的像素被预测成背景。图示分析可见图2。
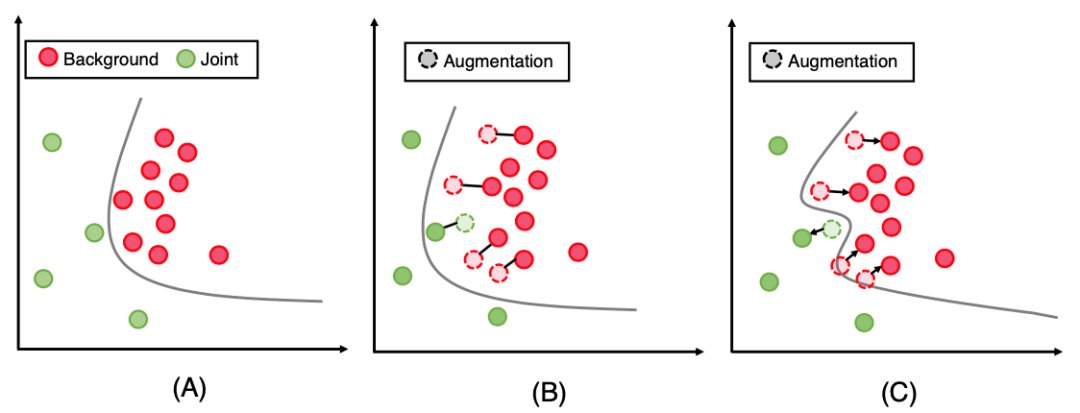
文章插图
- 芯片|功率半导体有多紧俏?博世亲自下场生产碳化硅芯片,目标产能上亿颗!
- 中关村|柳传志在这里被骗、掘金,书写半部科技史的中关村经历了什么?
- saas|上半年的Redmi K40 Pro,现在入手2500元不到,还等?
- steam|各大数码板块,关于骁龙888的机型发热的讨论,已经持续了大半年了
- 刘德音|台积电董事长刘德音:2030年全球半导体产值有望达1万亿美元
- 电视盒子|1天1亿流量,却赚不到半毛钱?
- 半导体|台积电董事长刘德音:未来10年将会感受到真实与虚拟世界结合
- 大疆|大疆劲敌要上市了:半年卖出1.2万台农业无人机,估值近100亿
- 蓝牙音箱|“半夜看电影的邻居,能不能删掉,你手机的蓝牙音箱?”
- 三星|红米Note10Pro半年使用体验,谈一谈现在还值不值得入手?