值得一提的是,从因果角度出发,可解释性和稳定性之间存在一定的内在关系,即通过优化模型的稳定性亦可提升其可解释性,从而解决当前人工智能技术在落地中面临的困境。基于此,清华大学崔鹏团队从2016年起开始深入研究如何将因果推理与机器学习相结合,并最终形成了“稳定学习”(Stable Learning)的研究方向。稳定学习有望弥补机器学习模型的“预测”到经济生活等现实“决策”之间的鸿沟,随着对因果分析研究的进一步深入,以稳定学习为代表的因果分析建模技术将成为人工智能发展的突破口,帮助我们从数据中推断出因果关系并进行有效检验,从而做出更好的决策。因果推理近年来在机器学习和人工智能领域引起了广泛关注。它通常被定位为一个独特的研究领域,可以将机器学习的范围从预测建模扩展到干预和决策。而从作者的角度来看,即便对于机器学习所擅长的预测类问题,如果对预测稳定性、可解释性和公平性提出较高要求,那么因果统计的思想对于改善机器学习、预测建模也变得不可或缺。基于此,作者提出了稳定学习的概念和框架,以弥合因果推理中传统精确建模与机器学习中的黑盒方法之间的鸿沟。本文阐明了机器学习模型的风险来源,讨论了将因果关系引入机器学习的必要性,从因果推理和统计学习两个视角阐述了稳定学习的基本思想和最新进展,并讨论了稳定学习与可解释性和公平性问题的关系。
文章插图
论文指出,机器学习技术的优化目标是预测的精度和效率,而错误预测的潜在风险往往被忽视。对于预测点击量或对图像进行分类等应用,模型可以频繁更新,错误的代价也不会太高。因此,这些应用领域非常适合结合持续性能监控的黑盒技术,这也是近年来机器学习得以快速发展的基础。然而,近年来机器学习被应用于医疗健康、工业制造、金融和司法等高风险领域,在这些领域,机器学习算法犯下的错误可能会带来巨大的风险。尤其是当算法预测在决策过程中发挥重要作用时,错误会对安全、道德和正义等社会问题产生重大后果。因此,缺乏稳定性、可解释性和公平保障是当今机器学习中亟需解决的最关键和最紧迫的议题。如图所示,相关性有三种来源,即由因果性导致的相关性、干扰变量导致的相关性、由样本选择偏差导致的相关性。在这三种相关性中,只有由因果性导致的相关性是可以保证在各种环境下稳定成立、且可以被解释的。而目前的神经网络模型并没有对特征是否存在因果性加以区分,这也是导致模型性能不稳定的重要原因。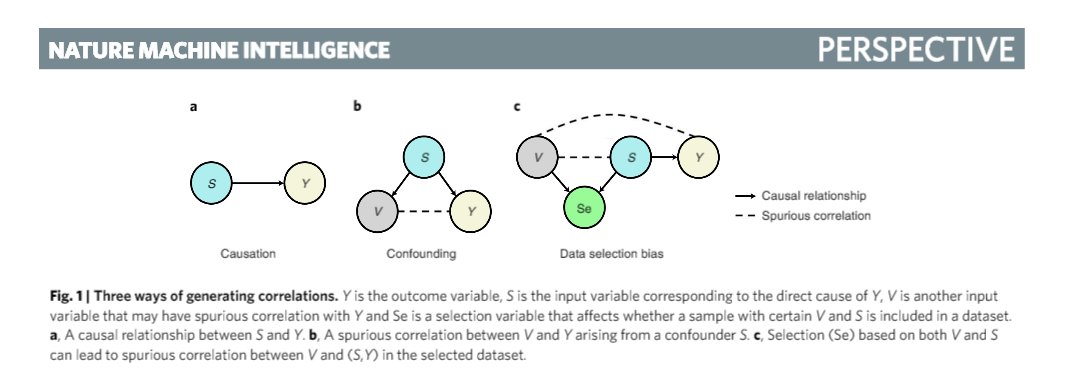
文章插图
论文进一步论述了机器学习可以避免由因果推理的基本问题引起的可验证性等挑战和局限性,并认为,机器学习和因果推理之间应该形成共识基础,稳定学习的框架正是实现这一目标的路径之一。论文还进一步阐述了稳定学习的定位与发展脉络,并比较了与常见的独立同分布模型和迁移学习模型的异同: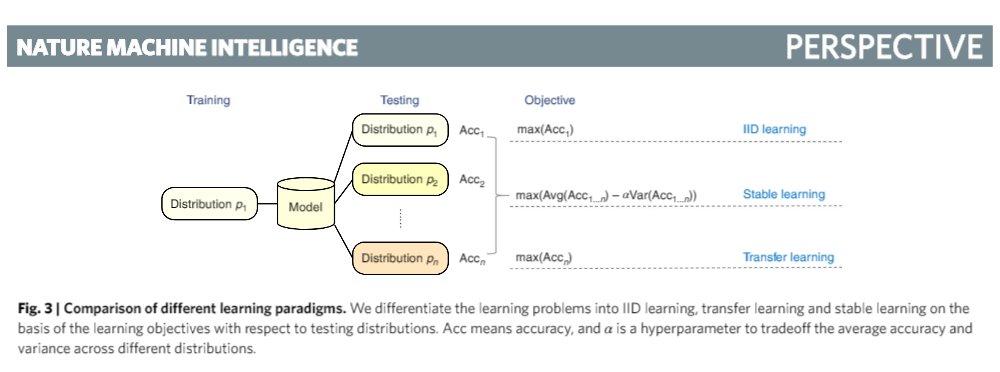
文章插图
- 独立同分布模型的训练和测试都在相同分布的数据下完成,测试目标是提升模型在测试集上的准确度,对测试集环境有较高的要求;
- 迁移学习同样期望提升模型在测试集上的准确度,虽然允许测试集的样本分布与训练集不同,但要求测试集样本分布已知;
- 稳定学习无需测试数据集与训练数据来自同一分布,并且不假设测试数据分布已知。测试目标是在保证模型平均准确度的前提下,降低模型性能在各种不同样本分布下的准确率方差。与上述学习模式相比,稳定学习的目标更接近现实的问题设置,理论上,稳定学习可以在不同分布的测试集下都有较好的性能表现。
文章最后提出,如果我们希望机器学习算法能被进一步应用,需要解决稳定性、可解释性和公平性问题,而这些问题是当今学习范式的根本局限,需要从根本上加以解决。尽管业内对预测、相关性和因果关系的基础仍存在争论,因果推理,尤其是在观察研究中所取得的一些最新进展已经可以为机器学习提供更多的见解和理论支持。作为一种新的学习范式,稳定学习试图结合这两个方向之间的共识基础。如何合理地放松严格的假设,以匹配更多具有挑战性的真实应用场景,并在不牺牲预测能力的情况下使机器学习更可信,是未来稳定学习需要解决的关键问题。