AMD 已经完成了对 Xilinx 的收购 , 由于过去一年半时间里 AMD 的股价上涨 , 最终成本接近 490 亿美元 , 而不是最初在 2020 年 10 月宣布该交易时预计的 350 亿美元 。
现在 , 随着 AMD 获得监管机构的批准并花光了所有“钱”——稀释后的市值与实际现金不同 , 但你可以用它买东西——很自然地想知道 CPU 和GPU 设计师将使用他们所获得的东西 。 不仅是作为 Xilinx 器件核心的 FPGA 可编程逻辑 , 还包括在所有 FPGA 混合中变得普遍的晶体管硬块 , 例如 DSP 引擎、AI 加速器、内存控制器、I/O 控制器和其他类型的互连 SerDes 。
AMD 需要很长时间才能建立一支工程师团队 , 该团队拥有赛灵思在可编程逻辑方面以及在其航空航天、国防、电信/通信、工业和广播/媒体业务领域所获得的专业知识 。 再加上 Vitis 软件堆栈 , Xilinx 的价值超过了收购一家在其他领域拥有收入和利润流且与 AMD 核心业务几乎没有重叠的公司的价值 。 它立即转化为一个更广泛的潜在市场 , AMD 首席执行官 Lisa Su 现在将其定为 1350 亿美元 , 这比Su 所说的 790 亿美元的潜在市场要大得多 。
不断增加的 TAM 对于 AMD(实际上是任何半导体设计师)实现增长至关重要 , 并将Xilinx 的收入和利润流(在过去 12 个月中分别为 36.8 亿美元和 9.29 亿美元)添加到AMD 的收入和利润流中- 2021 年分别为 163.4 亿美元和 31.6 亿美元也有其内在价值 。
但真正的价值 , 以及为什么 Su & Company 花了这么多钱来收购 Xilinx , 它需要做很多事情来最大化投资并推动收入高于仅仅通过合并和推动成本低于它所能达到的水平只需合并一些后台功能和实体办公室即可 。
AMD 以及数据中心的任何主要芯片设计师都不清楚他们从第三方获得了多少 IP 块的许可 。 在我看来 , 这可能比我们许多人意识到的成本更高 , 并且假设赛灵思实际上创建了自己的内存控制器、I/O 控制器、网络控制器和更通用的 SerDes 以及片上互连 , 那么 AMD 可能随着时间的推移转移到赛灵思 IP 块 , 能够节省一些钱 。 如果赛灵思 IP 块比 AMD 替代品更好或完全从 AMD 堆栈中消失 , 那么这里有各种可能性来改进 AMD 在 CPU 和 GPU 插槽中的内容以及它如何从中创建自己的新 IP 。
例如 , 想象一下基于 Xilinx SerDes 的数据中心级 Infinity Fabric 交换结构以及由 AMD 和 Xilinx 融合团队共同创建的数据包处理引擎?想象一下类似于IBM 为其 Power10 处理器创建的内存区域网络 , 但跨机架和机架以及 Epyc CPU 和 Instinct CPU 加速器的行和行运行 。 想象一下 , 根本不关心以太网或 InfiniBand , 除了作为集群的入口点 。 那会有多酷?
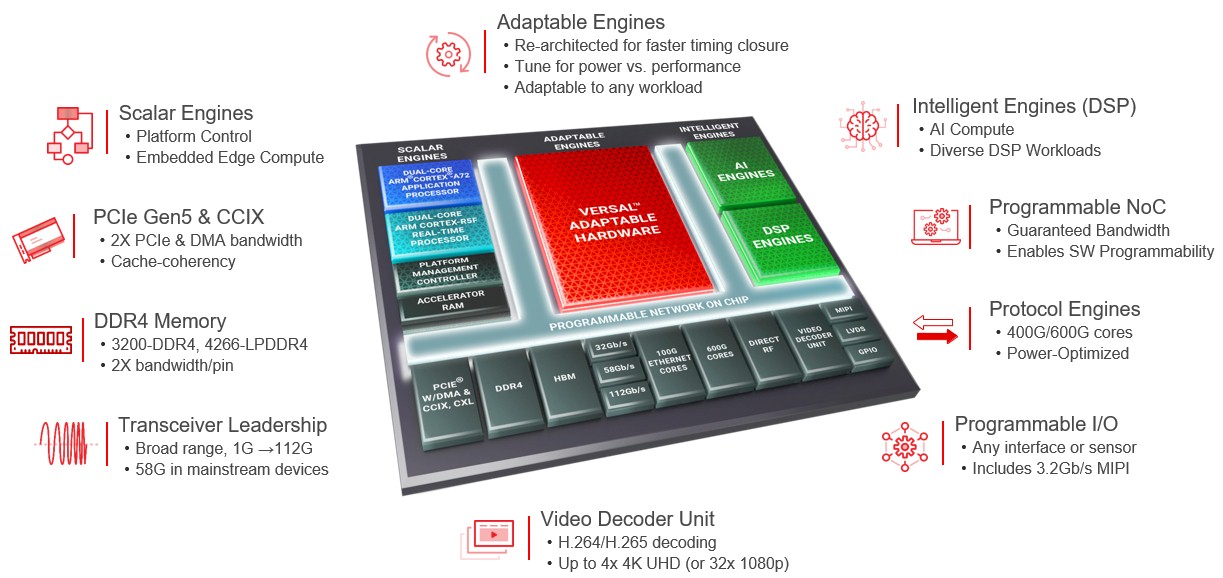
Versal 系列的“Everest”一代中的 Xilinx FPGA 混合器件?
那些用于机器学习推理处理的 AI 矩阵引擎和用于各种信号处理的 DSP 引擎是过去在可编程逻辑中实现的硬块——赛灵思在其 Versal 系列中一直将其称为自适应引擎——但由于空间、热量和性能问题 , 将这些块实现为 ASIC 并使用芯片上的高速互连将所有这些块相互连接并连接到可编程逻辑要高效得多 。
AMD 的工程师在考虑如何构建计算引擎、系统和集群时 , 可以使用这些硬块中的每一个 , 包括 Arm 内核 。 AMD 设计的每个计算设备 , 无论是单片芯片还是封装中的小芯片集合 , 都可以在 AMD 认为合适的时候添加一些可编程逻辑 。
那么除了在很大程度上保持业务不变之外 , AMD 将如何与 Xilinx 合作呢?它还没有说 , 除了说 AMD 在交易失败之前已经授权了一些 Xilinx IP , 并且无论该 IP 是什么——不要假设它是可编程逻辑——都将在之前的某个时候出现在 AMD 芯片中明年年底 。
做些大胆的猜测 , 也欢迎提出你的看法进行交流:
首先 , 我们认为整个 CPU 和整个 FPGA 的单芯片混合实现是不太可能的 , 但有可能会发生共同封装的 CPU-FPGA 混合 。
这是英特尔早在 2014 年就与 FPGA 制造商 Altera 合作的东西 , 甚至在它收购该公司之前 , 然后在 2018 年宣布将“Skylake”至强 SP 处理器与 Arria 10 FPGA 混合在一个封装中的产品 。 我们认为这些不会在数据中心起飞 , 原因与为什么我们在数据中心的单个封装中看不到 CPU-GPU 混合体的原因相同 , 除非是非常特殊的情况 , 例如带有集成显卡的 PC 芯片被重新用作媒体处理服务器引擎 , 就像 AMD 和英特尔过去在其嵌入式产品线中所做的那样 。
在其 frankensocket CPU-GPU 复合体中 , 英特尔将 125 瓦的成熟 20 核 Xeon SP-6138P 与额定 70 瓦的成熟Arria 10 GX FPGA 1150放在同一封装中 。 它们通过 UltraPath 互连 (UPI) 链接进行连接 , 这些链接用于与 CPU 进行共享内存 NUMA 配置 , 这意味着英特尔将 UPI 控制器移植到 Arria 10 上 。 (这个 UPI 控制器似乎不太可能在可编程控制器中实现逻辑 , 但 UPI 协议可能是在硬编码 SerDes 之上实现的 , 该 SerDes 适合 UPI 的时序 , 可编程逻辑填补了空白 。 )Arria 10 GX 没有在 FPGA 复合体上激活 Arm 内核(他们可能一直在那里 , 英特尔从未明确表示过) 。
- 新东方|小鹏汽车回应高管年薪超4亿;阿里将设立品牌自营旗舰店;小米12号创始员工离职;星巴克涨价丨邦早报
- 安卓|iPad剪辑神器LumaFusion将推安卓版!支持中文,平板生产力将释放
- 小米科技|小米怎么了?公司高层频繁离职,雷军再失一员大将
- 显卡|显卡何时真正降价?AMD苏妈回应:下半年显卡价格会松动
- 三星Galaxy|为什么很多真正懂手机的,却更喜欢用一加、魅族这些“小众”品牌
- 富士康|下定决心撤离大陆?富士康正式官宣,郭台铭可能别有用心
- 华为|iOS15.4beta3凌晨发布,首批用户评价出炉,附不同机型升级建议
- 投影仪|2022年家用投影仪性价比之王 经济又高能的1080p投影仪推荐
- 青春版|京东金融 App 青春版宣布下线,聚焦学生用户和校园场景
- iPhoneSE|不到三千元!iPhone SE3将有3个版本,已经量产