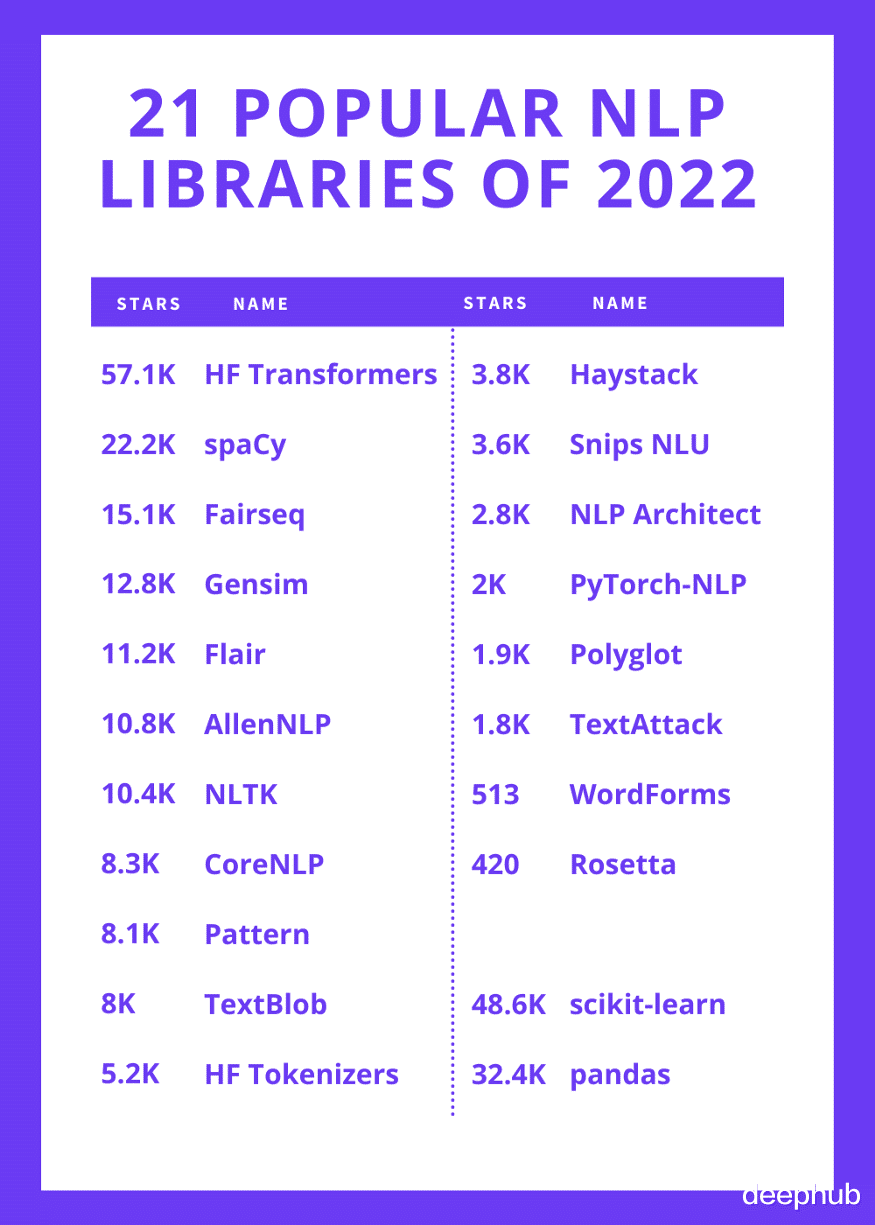
在本文中 , 我列出了当今最常用的 NLP 库 , 并对其进行简要说明 。它们在不同的用例中都有特定的优势和劣势 , 因此它们都可以作为专门从事 NLP 的优秀数据科学家备选方案 。 每个库的描述都是从它们的 GitHub 中提取的 。
NLP库以下是顶级库的列表 , 排序方式是在GitHub上的星数倒序 。
1、Hugging Face Transformers
57.1k GitHub stars.
Transformers 提供了数千个预训练模型来执行不同形式的任务 , 例如文本、视觉和音频 。这些模型可应用于文本(文本分类、信息提取、问答、摘要、翻译、文本生成 , 支持超过 100 种语言)、图像(图像分类、对象检测和分割)和音频(语音识别和音频分类 ) 。Transformer 模型还可以结合多种模式执行任务 , 例如表格问答、OCR、从扫描文档中提取信息、视频分类和视觉问答 。
2、spaCy
22.2k GitHub stars.
spaCy是 Python 和 Cython 中用于自然语言处理的免费开源库 。它从一开始就设计用于生产环境 。spaCy 带有预训练的管道 , 目前支持 60 多种语言的标记化和训练 。它具有最先进的神经网络模型 , 可以用于标记、解析、命名实体识别、文本分类、并且使用 BERT 等预训练Transformers进行多任务学习 , 可以对模型进行 打包、部署和工作 , 方便生产环境的部署 。spaCy 是商业开源软件 , 在 MIT 许可下发布 。
3、Fairseq
15.1k GitHub stars.
Fairseq 是一个序列建模工具包 , 允许研究人员和开发人员为翻译、摘要、语言建模和其他文本生成任务训练自定义模型 。它提供了各种序列建模论文的参考实现 。
4、Gensim
12.8k GitHub stars.
Gensim 是一个 Python 库 , 用于主题建模、文档索引和大型语料库的相似性检索 。目标受众是 NLP 和信息检索 (IR) 社区 。Gensim 具有流行算法的高效多核实现 , 包括但不限于Latent Semantic Analysis (LSA/LSI/SVD)、Latent Dirichlet Allocation (LDA)、Random Projections (RP)、Hierarchical Dirichlet Process(HDP) 或 word2vec 深度学习等 。
5、Flair
11.2k GitHub stars.
Flair 是一个强大的 NLP 库 。Flair 的目标是将最先进的 NLP 模型应用于文本中 , 例如命名实体识别 (NER)、词性标注 (PoS)、对生物医学数据的特殊支持、语义消歧和分类 。Flair 具有简单的界面 , 允许使用和组合不同的单词和文档嵌入 , 包括 Flair 嵌入、BERT 嵌入和 ELMo 嵌入 。该框架直接构建在 PyTorch 上 , 可以轻松地训练自己的模型并使用 Flair 嵌入和类库来试验新方法 。
6、AllenNLP
10.8k GitHub stars.
AllenNLP是基于 PyTorch 构建的 NLP 研究库 , 使用开源协议为Apache 2.0, 它包含用于在各种语言任务上开发最先进的深度学习模型并提供了广泛的现有模型实现集合 , 这些实现都是按照高标准设计 , 为进一步研究奠定了良好的基础 。AllenNLP 提供了一种高级配置语言来实现 NLP 中的许多常见方法 , 例如transformer、多任务训练、视觉+语言任务、公平性和可解释性 。这允许纯粹通过配置对广泛的任务进行实验 , 因此使用者可以专注于解决研究中的重要问题 。
7、NLTK
10.4k GitHub stars.
NLTK — Natural Language Toolkit — 是一套支持自然语言处理研究和开发的开源 Python 包、数据集和教程的集合 。它为超过 50 个语料库和词汇资源(如 WordNet)提供易于使用的接口 , 以及一套用于分类、标记化、词干提取、标记、解析和语义推理的文本处理库 。
8、CoreNLP
8.3k GitHub stars.
斯坦福 CoreNLP 提供了一组用 Java 编写的自然语言分析工具 。它可以接收原始的人类语言文本输入 , 并给出单词的基本形式、词性、公司名称、人名等 , 规范化和解释日期、时间和数字量 , 标记句子的结构 在短语或单词依赖方面 , 并指出哪些名词短语指的是相同的实体 。
9、Pattern
8.1k GitHub stars.
注意:该库已经2年没有更新了
Pattern 是 Python 的web的挖掘工具包 , 它包含了:网络服务(谷歌、推特、维基百科)、网络爬虫和 HTML DOM 解析器 。它有几个自然语言处理模型:词性标注器、n-gram 搜索、情感分析和 WordNet 。它实现了机器学习模型:向量空间模型、聚类、分类(KNN、SVM、感知器) 。模式也可用于网络分析:图形中心性和可视化 。
10、TextBlob
8k GitHub stars.
TextBlob 是一个用于处理文本数据的 Python 库 。它提供了一个简单的 API , 用于深入研究常见的自然语言处理任务 , 例如词性标注、名词短语提取、情感分析、分类、翻译等 。TextBlob 站在 NLTK 和 Pattern 的基础上制作 , 并且可以很好地与两者配合使用 。
- 小米科技|小米MIX5一马当前,微挖孔回归,200W快充是重点
- 庄俊|2022年小红书内容营销必看39条建议
- 小米科技|家电升级计划:幸福感+N,盘点近期入手的家电好物
- 快科技|云鲸用创新技术强势出圈,市场发展潜力巨大
- 高通骁龙|2022年了,骁龙870手机还值得买吗?
- 机箱|小米4nm新机上线,12+256G大存储四千出头,还是雷军靠谱
- 飞利浦·斯塔克|「手慢无」高刷2.5K屏 小米平板5Pro促销送快充
- 小米科技|小米12系列或有mini版本,看齐iPhone SE,定位2K价位段
- 红米手机|1999元起!Redmi K50全系售价曝光,干翻小米12
- 一加科技|一加OxygenOS 13官宣:将与OPPO ColorOS合并