终极版AlphaGo,DeepMind新算法MuZero作者解读( 二 )
文章插图
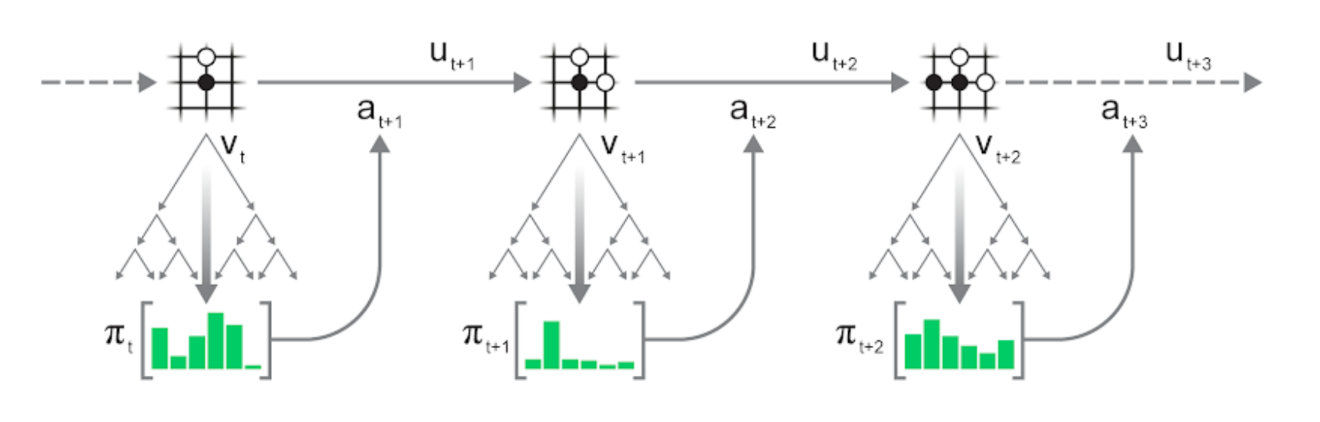
动作的选择可以是贪心的(选择访问次数最多的动作),也可以是探索性的:通过一定的温度t控制探索程度,并对与访问次数n(s,a)成比例的动作a进行采样:
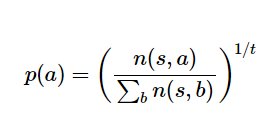
文章插图
当t = 0时,等效贪婪采样;当t = inf时,等效均匀采样。
训练现在,我们已经学会了运行MCTS来选择动作,并与环境互动生成过程,接下来就可以训练MuZero模型了。
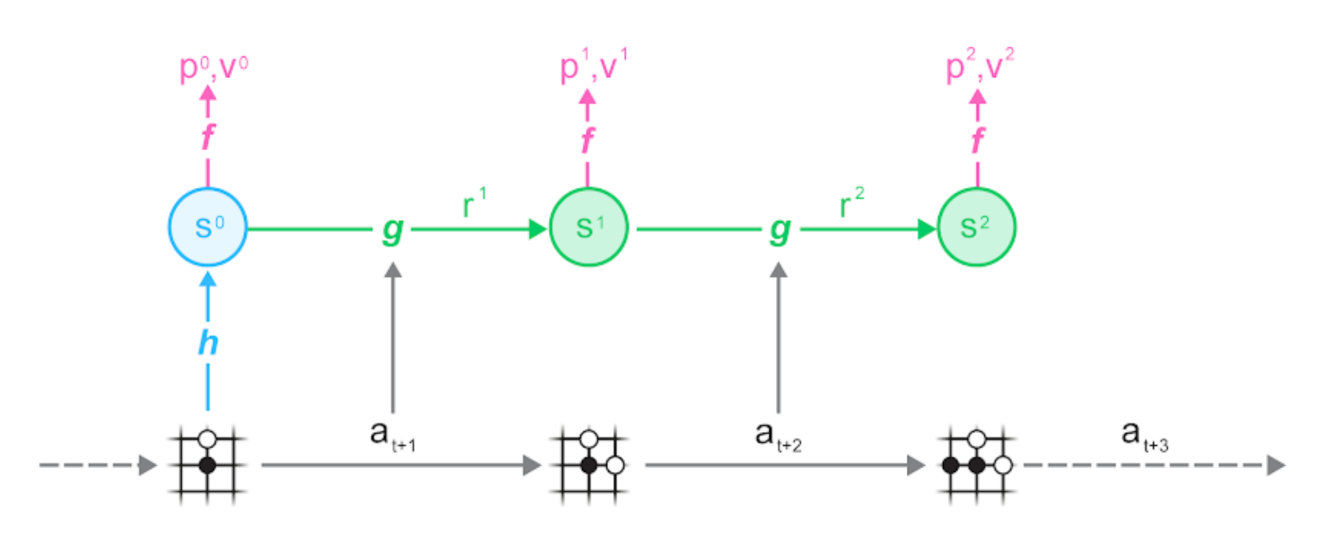
首先,从数据集中采样一条轨迹和一个位置,然后根据该轨迹运行MuZero模型:
文章插图
可以看到,MuZero算法由以下三部分组成:
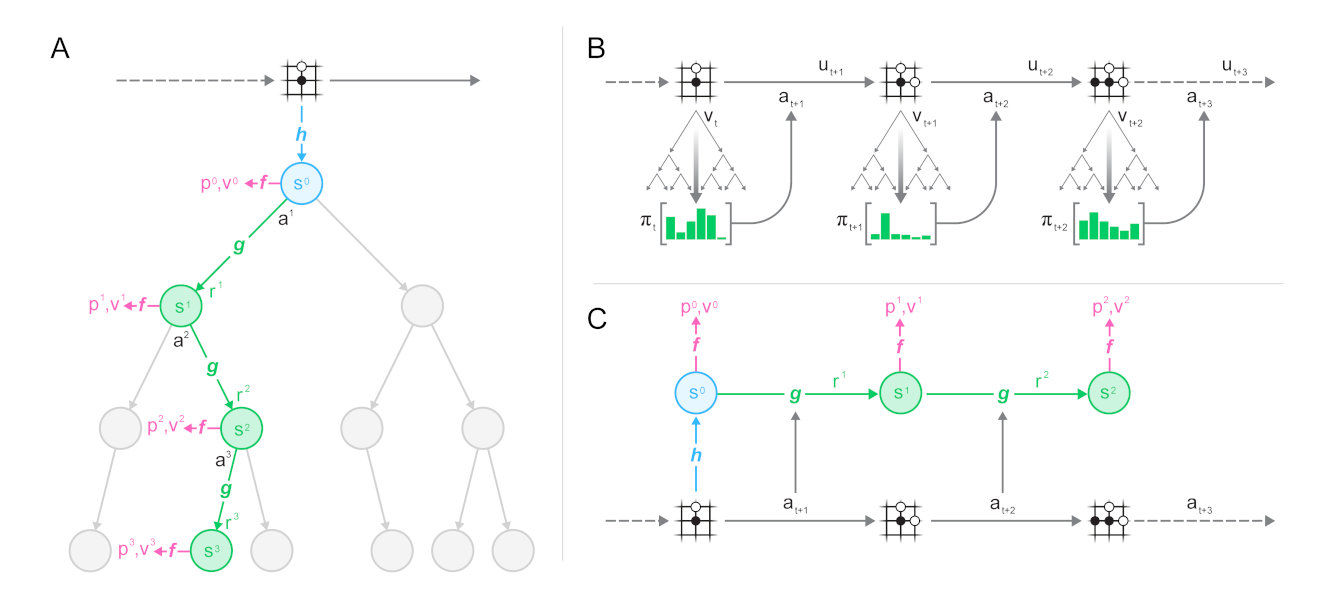
- 表示函数h将一组观察值(棋盘)映射到神经网络的隐藏状态s;
- 动态函数g根据动作a_(t + 1)将状态s_t映射到下一个状态s_(t + 1),同时估算在此过程的回报r_t,这样模型就能够不断向前扩展;
- 预测函数f根据状态s_t对策略p_t和值v_t进行估计,应用UCB公式并将其汇入MCTS过程。
从下图可以看到过程生成(B)与训练(C)之间的一致性:
文章插图
具体问言,MuZero估计量的训练损失为:
- 策略:MCTS访问统计信息与预测函数的策略logit之间的交叉熵;
- 值:N个奖励的折扣和+搜索值/目标网络估计值与预测函数的值之间的交叉熵或均方误差;
- 奖励:轨迹观测奖励与动态函数估计之间的交叉熵。
在一般训练过程中,通过与环境的相互作用,我们会生成许多轨迹,并将其存储在重播缓冲区用于训练。那么,我们可以从该数据中获得更多信息吗?

文章插图
很难。由于需要与环境交互,我们无法更改存储数据的状态、动作或奖励。在《黑客帝国》中可能做到,但在现实世界中则不可能。
幸运的是,我们并不需要这样。只要使用更新的、改进标签的现有输入,就足以继续学习。考虑到MuZero模型和MCTS,我们做出如下改进:

文章插图
保持轨迹(观测、动作和奖励)不变,重新运行MCTS,就可以生成新的搜索统计信息,从而提供策略和值预测的新目标。
我们知道,在与环境直接交互过程中,使用改进网络进行搜索会获得更好的统计信息。与之相似,在已有轨迹上使用改进网络重新搜索也会获得更好的统计信息,从而可以使用相同的轨迹数据重复改进。
重分析适用于MuZero训练,一般训练循环如下:
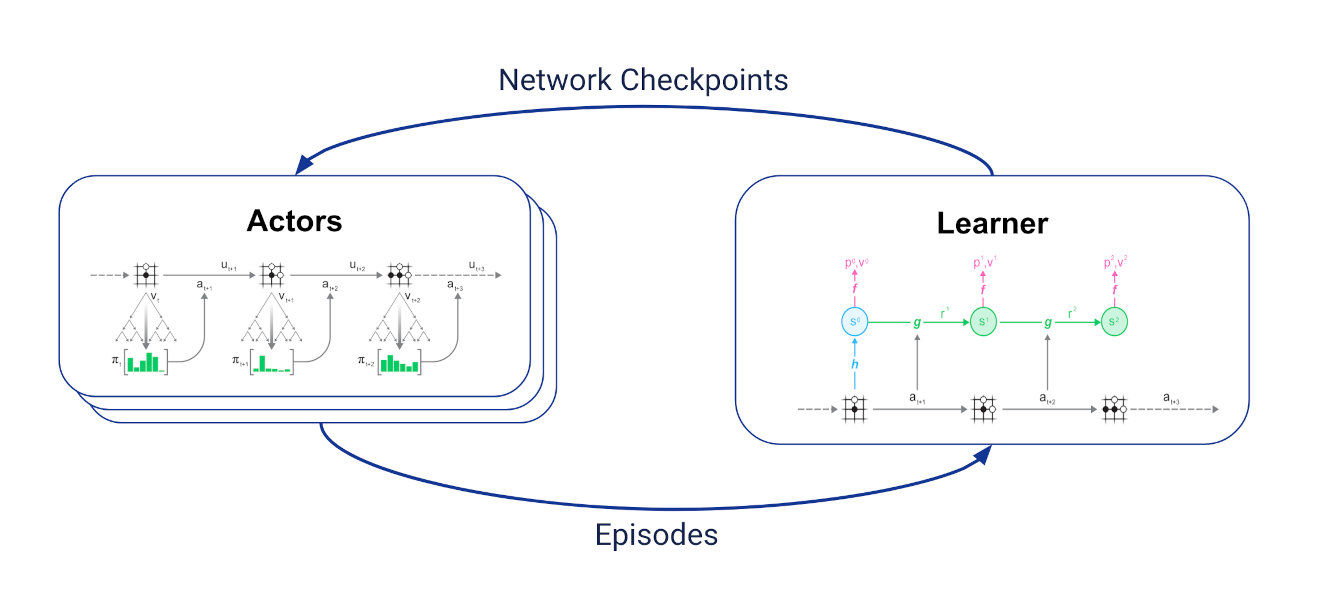
文章插图
设置两组异步通信任务:
- 一个学习者接收最新轨迹,将最新轨迹保存在重播缓冲区,并根据这些轨迹进行上述训练;
- 多个行动者定期从学习者那里获取最新的网络检查点,并使用MCTS中的网络选择动作,与环境进行交互生成轨迹。
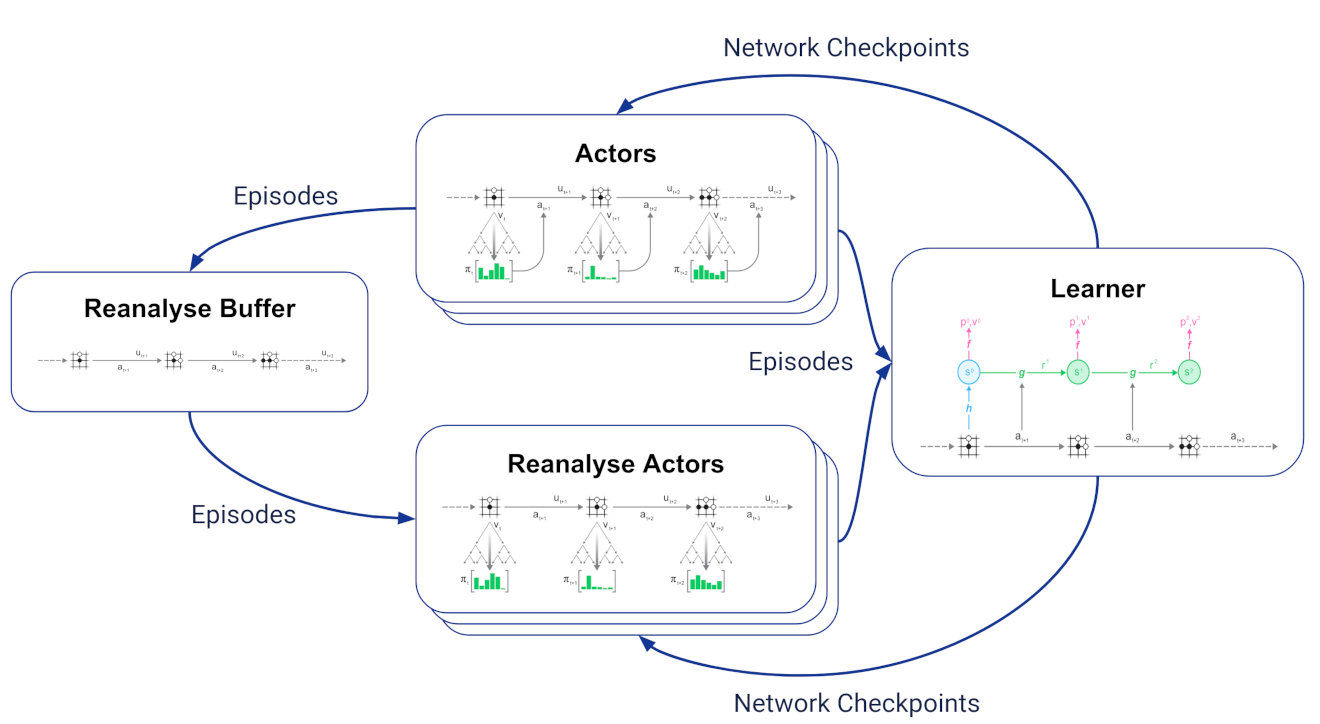
文章插图
- 重分析缓冲区,用于接收参与者生成的所有轨迹并保留最新轨迹;
- 多个重分析行动者从重分析缓冲区采样存储的轨迹,使用学习者的最新网络检查点重新运行MCTS,并将生成的轨迹和更新的统计信息发送给学习者。
MuZero命名含义MuZero的命名基于AlphaZero,其中Zero表示是在没有模仿人类数据的情况下进行训练的,Mu取代Alpha表示使用学习模型进行规划。
更研究一些,Mu还有其他丰富的含义:
- 夢,日语中读作mu,表示“梦”的意思, 就像MuZero通过学习的模型来想象未来状况一样;
- 希腊字母μ(发音为mu)也可以表示学习的模型;
- 無, 日语发音为mu,表示“无、没有”,这强调从头学习的概念:不仅无需模仿人类数据,甚至不需提供规则。
- playstation5|手慢就没有了!索尼PS5国行版将在双十二补货:库存一万台
- 英特尔|英特尔正在通过非K版本的Alder Lake改变现状
- 华为mate20pro|一台3年前256G版本的华为Mate20Pro放现在,相当于啥价位的手机?
- 原创|别花冤枉钱,我教你怎么样给电脑装系统,安装版与Ghost都不难!
- 米家|米家洗烘一体机尊享版10kg发布:首发2999元 一图看懂
- 联想|绷不住了!昔日虚空游戏本R9000P现货还便宜了,白色版降价更快
- nova9|5g版“华为nova9”发布,起步价格2999元,网友:价格太自信
- 车联网|加量不加价,荣耀60系列发布,俩版本差价1000元该选谁?
- 小米12|华为5G手机另类复活!Nova9新版发布:处理器和系统改头换面!
- 小米科技|小米12系列已知爆料汇总,新骁龙8+矩阵大底三摄,小屏版同时亮相