DeepMind巨亏42亿、独角兽惨遭3折贱卖,AI公司为何难有“好下场”?
正当人们在为DeepMind接踵而来的技术突破惊叹连连的时候 , DeepMind交出了一份高达6.49亿美元(约42亿人民币)的亏损账单 。 而比DeepMind巨额亏损更惨的是Element AI , 这个背靠着全球最大深度学习社区的加拿大明星独角兽 , 在入不敷出的艰难处境下近期被低价甩卖 。 而同样的商业化挑战其实也存在于身在硅谷的人工智能研究机构Open AI身上 。
一眼望去 , AlphaFold、MuZero、GPT这些前沿人工智能技术闪闪发光地站在由钞票堆积的山峰上 , 但却彷佛很少有人能真的攀上去跟它们握手 。
那么 , 为何人工智能技术一路过关斩将已经发展到了第四代 , 但商业化的道路却仍旧困境重重?
| 亏钱的不仅只有DeepMind
实际上 , DeepMind作为世界上规模最大的人工智能研究机构之一 , 自从2010年正式成立以来 , 就从没实现过盈利 , 反而“烧钱”指数还在逐年攀升 , 若不是2013年谷歌花了6亿美元收购了DeepMind , 该实验室或许早已破产解散 。
幸运的是 , DeepMind的确是遇到了一个足够宠它的“金主爸爸” , 虽然被收购后连年巨额亏损 , 但最近谷歌表示仍旧乐意继续为DeepMind提供昂贵的AI研究资金 , 称公司对近期的研究进展很满意 , 还大臂一挥免除了其11亿英镑的债务 。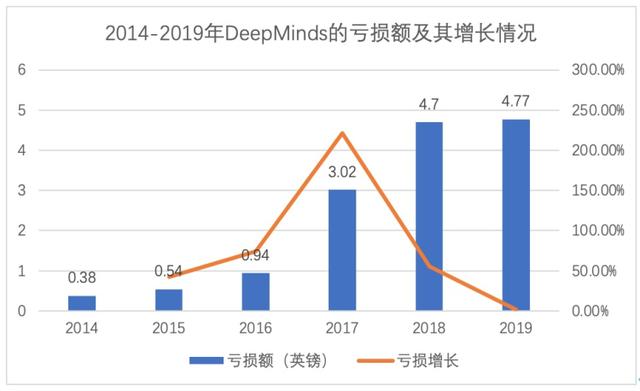 文章插图
文章插图
图 2014-2019年DeepMind的亏损额及其增长情况 , 硅星人制图
而跟DeepMind一样被大公司“宠”着的人工智能研究机构还有Open AI 。 Open AI是由马斯克、YC前总裁奥特曼以及诸多硅谷企业家联合于2015年12月创立的人工智能非营利组织 , 旨在预防人工智能可能带来的灾难性影响 , 并向公众开放专利和研究成果 , 到2017年时就募集了约10亿美元的融资 。
在2018年与马斯克因特斯拉发展和理念冲突分道扬镳之后 , Open AI宣布从非营利实验室转变为“上限盈利”公司 , 并在2019年7月接受了来自微软高达10亿美元的投资 。 而Open AI之所以做出商业转型 , 其直接原因是其现有的资金及收入情况并无法满足对计算和人才的持续投入需求 。
相比DeepMind和 Open AI还能在大公司的扶持下专注于技术研究 , 曾被加拿大视为“明日之星”的人工智能独角兽Element AI似乎就没有那么幸运了 。
关于Element AI的发展硅星人此前加拿大的系列文章还曾介绍过:一股“AIaaS”风正刮起:独角兽Element AI已变身人工智能“巨无霸” , 它由图灵奖得主、“深度学习三巨头”之一的Yoshua Bengio于2016年10月创立 。 Bengio所领导的蒙特利尔MILA实验室是目前世界上最大的深度学习学术社区 , Element AI所开发的产品都是基于MILA中大量学者几十年来的人工智能技术相关研究 , Element AI也是近年来世界上发展最快的人工智能初创公司之一 , 曾被认为是加拿大日后人工智能产业的领导者 。 文章插图
文章插图
然而 , 这家曾经意气风发、旨在要做全球人工智能咨询业开创者的明星公司 , 就在上个月被曝出将被美国云计算平台服务商 ServiceNow收购 , 而且收购价仅为2.3亿美元 。 不仅远远低于其上一轮融资中超过10亿加币的估值 , 甚至还不足4年来2.57亿美元的融资总额 。
据《环球邮报》此前披露的一份文件显示 , 收购前夕 , Element AI的资金链几乎已经枯竭、大量员工被解雇 , 年收入仅仅只有1000万加币左右 。 而在扣除成本费用后 , Element AI最终收购价格可能只有不到1.95 亿美元 。
|“烧钱”机器和应用困境
虽然这几个人工智能实验室的命运各不相同 , 但它们有一个共同点 , 即是都是围绕着深度学习、强化学习等前沿领域开展人工智能技术研究 , DeepMind、Open AI都旨在最终实现通用人工智能(AGI) 。 所谓的通用人工智能 , 就是让机器具有一般人类智慧 , 可以执行人类能够执行的任何智力任务 。
近年来 , 这些人工智能研究机构也确实在朝着通用人工智能方向行进 , 并取得了不俗的成绩 , 但技术的突破并没有带来商业回报 , 投入和产出相距甚远 。 而横梗在AI商业化道路上的两块巨石 , 一个是资金 , 另一个是应用 。
首先 , 要想在机器学习领域做出突破 , 不“烧钱”是不可能的 , 不仅要“烧”还是一车车的“烧” 。 由于深度强化学习展是建立在海量的数据处理、复杂的知识推理上的 , 常规的单机计算模式难以支撑 , 因此对训练模型时计算机资源的需求极高 。
比如2020年5月微软推出了为Open AI专门打造的超级计算机用于AI模型训练 , 花费上亿美元 , 谷歌的TPU一直处于打骨折给DeepMind租用的状态 。 除了硬件 , 在训练方面 , 以Open AI著名的文本生成算法GPT为例 , 一个拥有15亿参数的模型 , 每小时训练都要花费2048美元 , 而类似于DeepMind的AlphaGo算法 , 成功之前需要至少完成数百万次自我博弈 , 光训练费就要花 3500 万美元 。
- 会员|三年巨亏264亿!爱奇艺大规模裁员,波及多个业务线,部分团队全部被裁撤
- 人工智能|Zillow大牛市炒房巨亏,别把人祸甩锅人工智能
- 计算机科学|推特首席科学家Michael Bronstein加入牛津大学任职DeepMind教授
- 百度|第三季度巨亏319亿元,有多少用户为了不点击广告而卸载百度?
- 京东|百度、京东、B站、爱奇艺第三季度巨亏,字节跳动增长乏力
- 电池|京东方TCL华星大赚,OLED老二维信诺却巨亏,问题何在?
- 自动驾驶|巨亏借壳上市,Aurora:自动驾驶三分天下,必有我
- deepmind|谷歌母公司Alphabet成立人工智能公司,有望大幅提高药物发现速度
- 管理层|单季巨亏41亿,苏宁到了“最艰难的时期”|看财报
- 美团|被罚34.42亿元的美团 涉嫌停业机构“换马甲”入驻