通用版AlphaGo登《Nature》!最强AI棋手,不懂规则也能精通游戏( 二 )
 文章插图
文章插图
MuZero通过模拟下棋走向训练神经网络 。
而每一步棋对于整体棋局的贡献都会被累加 , 成为本次棋局最后的奖励 。
 文章插图
文章插图
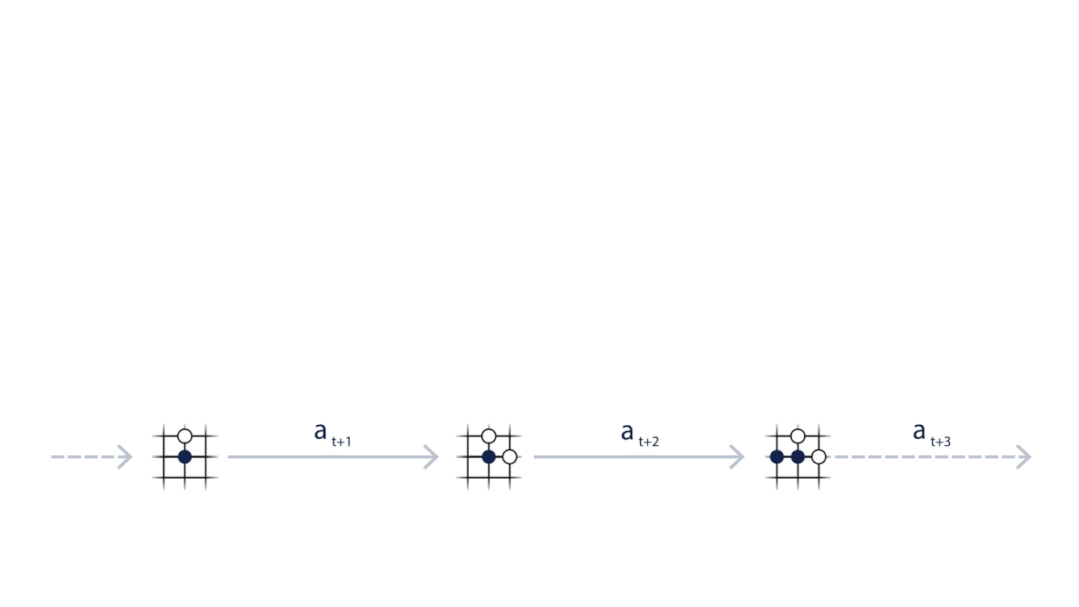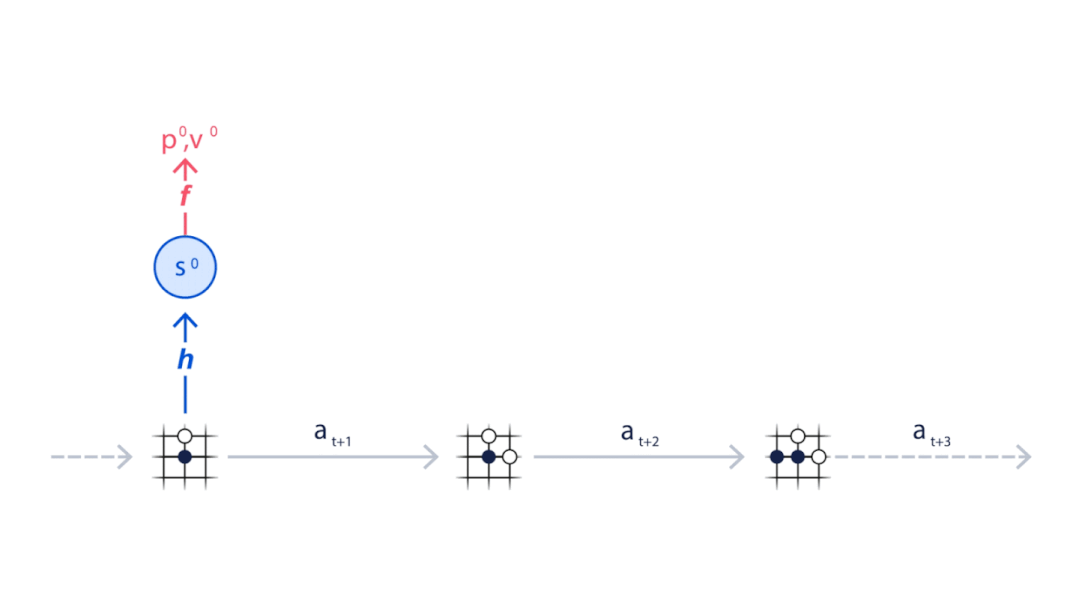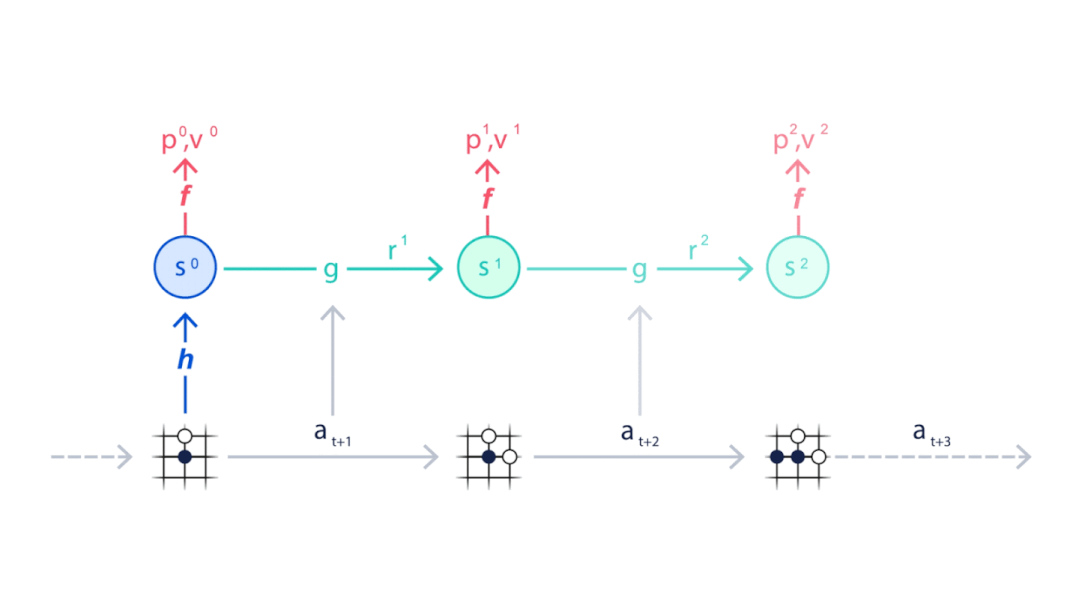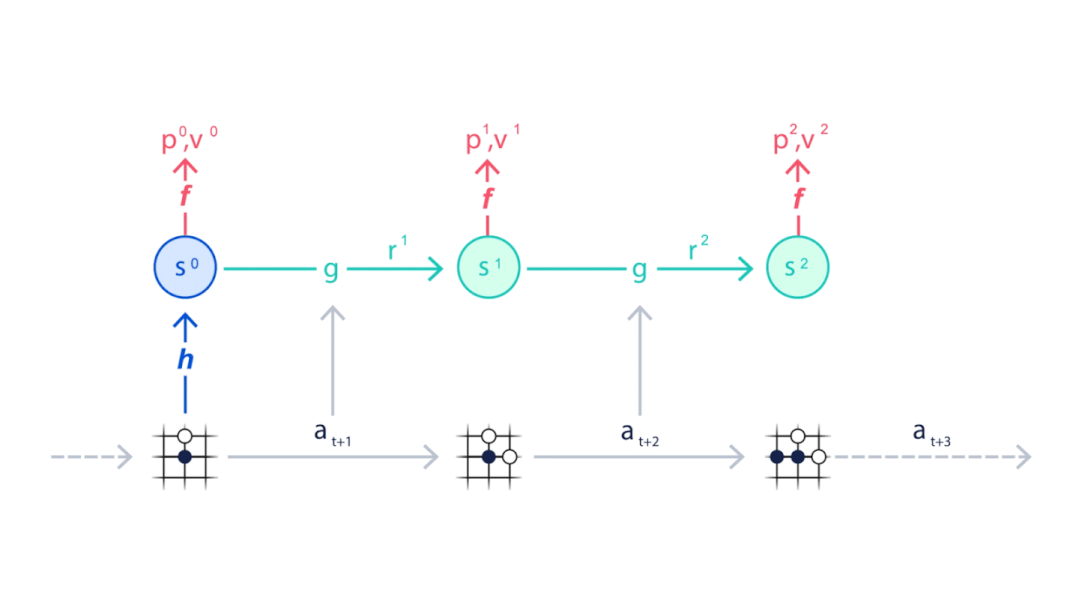
策略函数P得到每一步预测下法 , 价值函数V得到每一步的奖励 。
出了减少建模工作量外 , 这种方法的另一个主要优点就是可以不断复盘 , 而不需要得到外界的新数据 。 这样的优势也很明显 , 在Atari的测试中 , 名为MuZero Reanalyze的变体可以利用90%的时间使用学习过的模型进行重新规划 , 找到更优策略 。
二、MuZero强在哪?追平前辈 , 拓宽Atari游戏战场MuZero模型分别自学了围棋、国际象棋、日本将棋以及Atari游戏 , 前三者用来评估模型在规划问题上的表现 , Atari则用来评估模型面对视觉游戏时的表现 。
 文章插图
文章插图
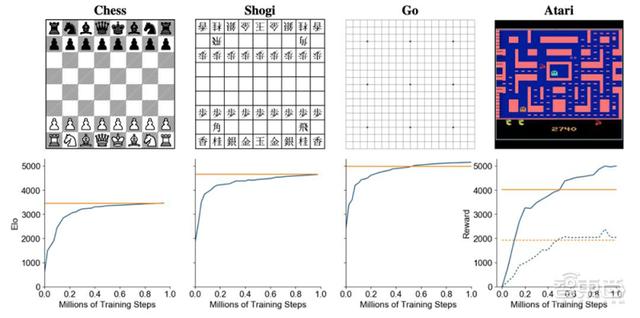
MuZero分别在国际象棋、日本将棋、围棋和Atari游戏训练中的评估结果 。 横坐标表示训练步骤数量 , 纵坐标表示 Elo评分 。 黄色线代表AlphaZero(在Atari游戏中代表人类表现) , 蓝色线代表MuZero 。
在围棋、国际象棋和日本将棋中 , MuZero不仅在多训练步骤的情况下达到甚至超过了“前辈”AlphaZero的水平 , 在Atari游戏中 , MuZero也表现突出 。
 文章插图
文章插图
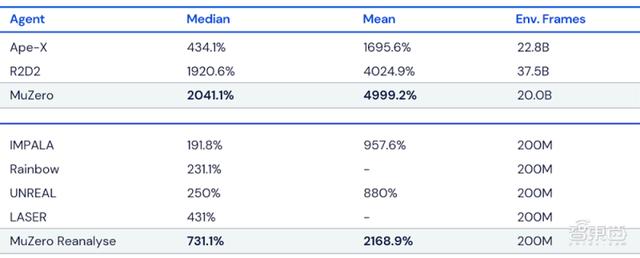
MuZero在Atari游戏中的性能 。 所有得分均根据人类测试的性能进行了归一化 , 最佳结果以粗体显示 。
为了进一步评估MuZero模型的精确规划能力 , DeepMind的研究人员还进行了围棋中经典的高精度规划挑战 , 即指下一步就判断胜负 。
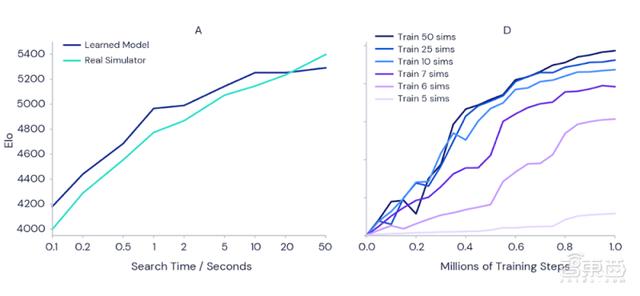
为了证实更多的训练时间能使MuZero模型更强大 , DeepMind进行了如下面左图实验 , 当每一步的判断时间从0.1秒延长到50秒 , 评价玩家技能的Elo指标能增加1000 , 相当于业余棋手和最强职业棋手之间的区别 。
而在右图的Atari游戏Ms Pac-Man(吃豆小姐)的测试中 , 也能很明显地看出训练时长越长时 , 模型表现越好 。
 文章插图
文章插图
左图:随着步骤判断时间增加 , 围棋Elo指标上涨;右图:训练时长越长 , 模型表现越好
结语:出身于游戏 , 期待更多应用基于环境要素建模的MuZero , 用在多个游戏上的“超人”表现证明了卓越的规划能力 , 也象征着DeepMind又一在强化学习和通用算法方面的重大进步 。
它的前辈AlphaZero也已投身于化学、量子物理学等领域 , 切身实地地为人类科学家们解决一系列复杂问题 。 在未来 , MuZero是否可以继承“家业” , 应对机器人、工业制造、未知“游戏规则”的现实问题所带来的挑战 , 我们拭目以待 。
【通用版AlphaGo登《Nature》!最强AI棋手,不懂规则也能精通游戏】来源:DeepMind
 文章插图
文章插图
- 下一代 AlphaGo,裸考也能拿满分
- “通用云健康”互联网医院启用拥抱互联网实现高质量发展
- 民营运营商为什么引热议?9元享5G、流量全网通用无套路
- 面向普通用户!冷门品牌逆袭之路,性能和续航哪个更重要?
- 极品"看片"神器!震撼来袭~手机端盒子端全部通用
- 微软披露Windows 10X更新的更多新细节:引入通用驱动程序
- 又一9元套餐诞生!高速流量全网通用,5年品牌耐玩无套路
- Spotify入驻Epic游戏商城:欲打造成更通用的应用分发平台
- 针对普通用户,荣耀低调中端性价比热销,促进缺货原因简单
- Android 通用的Intent介绍