通用版AlphaGo登《Nature》!最强AI棋手,不懂规则也能精通游戏
 文章插图
文章插图
智东西(公众号:zhidxcom)
编译 | 子佩
编辑 | Panken
智东西12月24日消息 , 继AlphaGo扬名海外后 , DeepMind再推新模型MuZero , 该模型可以在不知道游戏规则的情况下 , 自学围棋、国际象棋、日本将棋和Atari游戏并制定最佳获胜策略 , 论文今日发表至《Nature》 。
 文章插图
文章插图
论文链接:
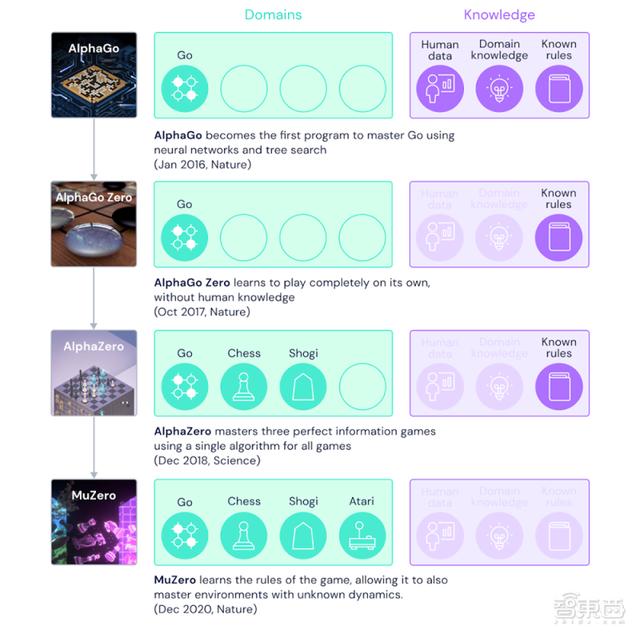
自2016年 , 令柯洁流泪、让李世石沉默的AlphaGo横空出世 , 打遍棋坛无人能敌后 , AI棋手的名号就此一炮打响 , 而其背后的发明家DeepMind却没有因此止步 , 四年之内迭代了四代AI棋手 , 次次都有新突破 。
始祖AlphaGo基于人类棋手的训练数据和游戏规则 , 采用了神经网络和树状搜索方法 , 成为了第一个精通围棋的AI棋手 。
二代AlphaGo Zero于2017年在《Nature》发表 , 与上代相比 , 不需要人类棋手比赛数据作为训练集 , 而是通过自对抗的方式自己训练出最佳模型 。
三代AlphaZero在2018年诞生 , 将适应领域拓宽至国际象棋和日本将棋 , 而不是仅限于围棋 。
第四代、也就是今天新公布MuZero最大的突破就在于可以在不知道游戏规则的情况下自学规则 , 不仅在更灵活、更多变化的Atari游戏上代表了AI的最强水平 , 同时在围棋、国际象棋、日本将棋领域也保持了相应的优势地位 。
 文章插图
文章插图
一、从未知中学习:三要素搭建动态模型与机器擅长重复性的计算和牢固的记忆不同 , 人类最大的优势就是预测能力 , 也就是通过环境、经验等相关信息 , 推测可能会发生的事情 。
比如 , 当我们看到乌云密布 , 我们会推测今天可能有雨 , 然后再重新考虑是否要出门 。 即使对于仅有几岁的孩子而言 , 学会这种预测方式 , 然后推广到生活的方方面面也是很容易 , 但这对于机器来说并不简单 。
对此 , DeepMind研究人员提出了两种方案:前向搜索和基于模型的规划算法 。
前向搜索在二代AlphaZero中就已经应用过了 , 它借助对游戏规则或模拟复盘的深刻理解 , 制定如跳棋、国际象棋和扑克等经典游戏的最佳策略 。 但这些的基础是已知游戏规则及对可能出现的状况大量模拟 , 并不适用情况相对混乱的Atari游戏 , 或者未知游戏规则的情况 。
基于模型的规划则是通过学习环境动态进行精准建模 , 再给予模型给出最佳策略 。 但对于环境建模是很复杂的 , 也不适用于Atari等视觉动画极多的游戏 。 目前来看 , 能够在Atari游戏中获得最好结果的模型(如DQN、R2D2和Agent57) , 都是无模型系统 , 也就是不使用学习过的模型 , 而是基于预测来采取下一步行动 。
也是由于以上两个方法中的优劣 , MuZero没有对环境中所有的要素进行建模 , 而是仅针对三个重要的要素:
1、价值:当前处境的好坏情况;
2、策略:目前能采取的最佳行动;
3、奖励:最后一个动作完成后情况的好坏 。
那接下来 , 我们就来看看MuZero是如何通过这三个要素进行建模 。
MuZero从当前位置开始(动画顶部) , 使用表示功能H将目前状况映射到神经网络中的嵌入层(S0) , 并使用动态函数(G)和预测函数(F)来预测下一步应该采取的动作序列(A) 。
 文章插图
文章插图
基于蒙特卡洛树状搜索和MuZero神经网络进行规划
那如何知道这一步行动好不好呢?
MuZero会与环境进行互动 , 也是模拟对手下一步的走向 。
- 下一代 AlphaGo,裸考也能拿满分
- “通用云健康”互联网医院启用拥抱互联网实现高质量发展
- 民营运营商为什么引热议?9元享5G、流量全网通用无套路
- 面向普通用户!冷门品牌逆袭之路,性能和续航哪个更重要?
- 极品"看片"神器!震撼来袭~手机端盒子端全部通用
- 微软披露Windows 10X更新的更多新细节:引入通用驱动程序
- 又一9元套餐诞生!高速流量全网通用,5年品牌耐玩无套路
- Spotify入驻Epic游戏商城:欲打造成更通用的应用分发平台
- 针对普通用户,荣耀低调中端性价比热销,促进缺货原因简单
- Android 通用的Intent介绍