深入理解Netty编解码、粘包拆包、心跳机制( 二 )
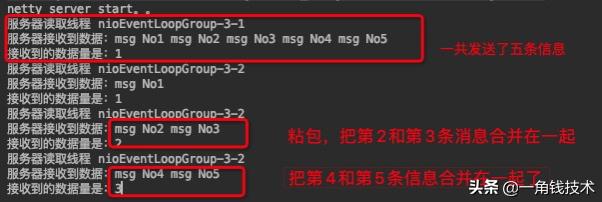
// count 变量 , 用于计数private int count;@Overridepublic void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception { System.out.println("服务器读取线程 " + Thread.currentThread().getName());ByteBuf buf = (ByteBuf) msg;byte[] bytes = new byte[buf.readableBytes()];// 把ByteBuf的数据读到bytes数组中buf.readBytes(bytes);String message = new String(bytes, Charset.forName("utf-8"));System.out.println("服务器接收到数据:" + message);// 打印接收的次数System.out.println("接收到的数据量是:" + (++this.count));}启动服务端 , 再启动两个客户端发送消息,服务端的控制台可以看到这样:
 文章插图
文章插图
粘包的问题其实是随机的 , 所以每次结果都不太一样 。
完整代码在 Github :
对应的包 com.niuh.splitpacket0
为什么出现粘包现象?【深入理解Netty编解码、粘包拆包、心跳机制】TCP 是面向连接的 , 面向流的 , 提供高可靠性服务 。 收发两端(客户端和服务器端)都要有成对的 socket , 因此 , 发送端为了将多个发送给接收端的包 , 更有效的发送给对方 , 使用了优化方法(Nagle算法) , 将多次间隔较少且数据量小的数据 , 合并成一个大的数据块 , 然后进行封包 , 这样做虽然提供了效率 , 但是接收端就难以分辨出完整的数据包了 , 因为面向流的通信是无消息保护边界的 。
如何理解TCP是面向字节流的
- 应用程序和 TCP 的交互是一次一个数据块(大小不等) , 但 TCP 把应用程序交下来的数据仅仅看成是一连串的无结构的字节流 。 TCP 并不知道所传送的字节流的含义;
- 因此 TCP 不保证接收方应用程序所收到的数据块和发送方应用程序所发出的数据块具有对应大小的关系(例如 , 发送方应用程序交给发送方的 TCP 共 10 个数据块 , 但接收方的 TCP 可能只用了 4 个就把收到的字节流交付上层的应用程序);
- 同时 , TCP 不关心应用进程一次把多长的报文发送到 TCP 的缓存中 , 而是根据对方给出的窗口值和当前网络阻塞的程度来决定一个报文段应包含多少个字节(UDP 发送的报文长度是应用进程给出的) 。 如果应用进程传送到 TCP 缓存的数据块太长 , TCP 就可以把它划分短一点再传送 。 如果应用程序一次只发来一个字节 , TCP 也可以等待积累有足够多的字节后再构成报文段发送出去 。
- 缓冲区数据达到 , 最大报文长度 MSS;
- 由发送端的应用进程指明要求发送报文段 , 即 TCP 支持的推送(push)操作;
- 当发送方的一个计时器期限到了 , 即使长度不超过 MSS , 也发送 。
- 在数据的末尾添加特殊的符号标识数据包的边界 。 通常会加\n、\r、\t或者其他的符号
- 在数据的头部声明数据的长度 , 按长度获取数据
- 规定报文的长度 , 不足则补空位 。 读取时按规定好的长度来读取 。 比如 100 字节 , 如果不够就补空格;
- 使用更复杂的应用层协议 。
原理是上面讲的第一种思路 , 在数据末尾加上特殊符号以标识边界 。 默认是使用换行符\n 。
- 全新8核国产CPU深入探秘:马上能买到
- 数据|新基建时代,高大全的数据管理解决方案是怎样“炼”成的?
- 16G运存+256G内存,专业骁龙865旗舰,性价比深入人心
- 绿色骑行深入校园,共享单车长途长时需求量提升
- 不被理解的超时代发明,你知道几个?在线膜拜大神,西瓜视频真相
- 深入调查SolarWinds黑客事件 微软已查封一个核心服务器
- 《深入理解Java虚拟机》:Java内存区域
- 基于Netty高性能RPC框架Nifty协议、传输层、编解码
- 深入探讨 JavaScript 逻辑赋值运算符
- 彻底理解 IO 多路复用实现机制