百度背叛激光雷达路线了吗?( 四 )
与激光雷达不同 , 摄像头成像是“被动”式的(Passive sensing) , 感光元件仅接收物体表面反射的环境光 , 三维世界经投影变换(Projective transformation)被“压缩”到二维相平面上 , 成像过程中场景“深度”(景深)信息丢失了 。
当算法再试图从二维图像中恢复目标物体原本在三维空间中所处的位置时 , 面对的是一个欠约束的“逆问题”(ill-posed inverse problem) , 其难度可直观理解为用2个方程式求解3个未知数 。
由一张二维图像恢复场景中的三维信息(「2D-to-3D」)是计算机视觉学科诞生之初定义的经典问题之一 , 时至今日仍是视觉界热门研究方向 , 也是使用摄像头代替激光雷达为无人驾驶提供感知结果所面临的核心技术挑战 。
进入技术分享前 , 先看一段一镜到底的日常Apollo Lite亦庄路测视频 。 视频中测试区域处于亦庄中心繁华路段 , 包含两条路线 , 累计自动驾驶行驶时长接近60分钟 , 全程无接管 。
从视频中可以看出 , 主车以40公里/小时左右的速度行驶 , 宽阔道路行驶时速度可提升至55公里/小时以上(亦庄道路限速为60公里/小时) 。 行驶过程中 , 主车与其他车辆 , 行人 , 自行车和电动车等道路参与者交互频繁 , 在成功处理切车、变道、过路口、掉头、等城市道路基础交通场景之外 , 车辆也展示了出色的通行能力和与道路参与者的交互能力 , 视频中呈现了其在路桩摆放密集的狭窄路段、施工区域以及双向单车道上的通行能力 , 车辆能够合理避让车流中横穿道路的行人和在车流中穿梭的摩托车和电动车 。 可视化来自车端实时感知结果 , 视频内容未经任何剪辑加工 , 力求客观真实的呈现完整测试过程 。
03 Apollo Lite视觉感知技术揭秘百度在近一年视觉感知攻坚过程中积累了丰富的实践经验并沉淀了有效的方法论 , 总结下来 , 三个关键技术层面的深耕突破成就了Apollo Lite驾驶能力迅速提升 。
2D-to-3D难题近年来 , 视觉目标检测任务伴随深度学习技术的进步取得了突飞猛进的发展 。 今天 , 经对人工标注数据进行监督学习 , 在图像上将目标物体(如车辆、行人、自行车等)2D框选出来已经不是视觉感知的头部难题 , 单纯2D框检测无法支持3D空间中的车辆规划控制 , 打造一套纯视觉感知系统 , 解决2D-to-3D问题首当其冲 。
传统算法计算2D检测框的框底中心后通过道路平面假设和几何推理物体深度信息 , 这类方法简单轻量 , 但对2D框检测完整性和道路的坡度曲率等有较强的依赖假设 , 对遮挡和车辆颠簸比较敏感 , 算法欠缺鲁棒性 , 不足以应对复杂城市道路上的3D检测任务 。 Apollo Lite延续「模型学习+几何推理」框架同时对方法细节进行了大量打磨升级 。
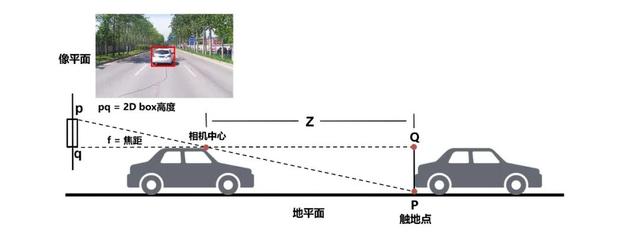 文章插图
文章插图
△传统基于地平面假设和相似关系计算2D-to-3D的方法模型学习 – 数据和学习层面 , 利用激光雷达的点云数据将2D标注框和3D检测框关联 , 在标注阶段为每个2D包围框赋予了物理世界中的距离、尺寸、朝向、遮挡状态/比例等信息 。
通过从安装相同摄像头(Camera configuration)并配备高线数激光雷达的百度L4自动驾驶车队获取海量时空对齐的「图像+点云」数据 , 训练阶段DNN(Deep neural networks)网络模型从图像appearance信息做障碍物端到端的三维属性预测 , 模型端完成从仅预测2D结果到学习2D+3D信息的升级 , 将传统“几何推理”后处理模块的任务大程度向模型端前置 , “深度学习+数据驱动”为提升预测效果提供了便捷有效的路径和更高的天花板 。
在添加模型端3D预测能力外 , 为给后续几何约束阶段提供丰富的图像线索 , 针对不同位置/朝向相机的安装观测特性 , 模型从学习障碍物矩形包围框拓展到预测更多维度更细粒度的特征 , 如车轮和车底接地轮廓线 。
- 用户|2020互联网「年终盘点」之盘点:百度最泪目,趣头条接地气
- 2021年互联网巨头第一仗!飞书开撕微信,阿里华为百度全都入局
- 2020百度地图生态大会:开放平台十周年 为行业送出多个解决方案“大礼包”
- 一个人完成AI开发和部署 百度飞桨实现铁路货车车号精准检测
- 曝iPhone 13全系标配激光雷达扫描仪 真就十三香?
- 百度网盘主体公司发生变更,市值翻倍正值拆分上市好时机?
- 从工程师到“水果猎人”他在百度做科普
- 百度华为阿里领衔,聚焦最值得关注的十家人工智能公司
- 网课平台专项整治第三批问题网站平台曝光 涉新浪微博、百度贴吧
- 百度|百度输入法“AI助聊”功能使用指南来了!纠错、预测、帮写轻松搞定