深度学习算法完整简介( 二 )
#4循环神经网络(RNN)
循环神经网络在许多NLP任务中都非常成功 。 在传统的神经网络中 , 可以理解所有输入和输出都是独立的 。 但是 , 对于许多任务 , 这是不合适的 。 如果要预测句子中的下一个单词 , 最好考虑一下它前面的单词 。
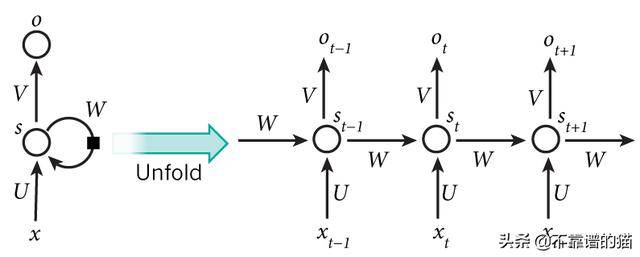
RNN之所以称为循环 , 是因为它们对序列的每个元素执行相同的任务 , 并且输出取决于先前的计算 。 RNN的另一种解释:这些网络具有“记忆” , 考虑了先前的信息 。
 文章插图
文章插图
例如 , 如果序列是5个单词的句子 , 则由5层组成 , 每个单词一层 。
在RNN中定义计算的公式如下:
- x_t-在时间步t输入 。 例如 , x_1可以是与句子的第二个单词相对应的one-hot向量 。
- s_t是步骤t中的隐藏状态 。 这是网络的“内存” 。 s_t作为函数取决于先前的状态和当前输入x_t:s_t = f(Ux_t + Ws_ {t-1}) 。 函数f通常是非线性的 , 例如tanh或ReLU 。 计算第一个隐藏状态所需的s _ {-1}通常初始化为零(零向量) 。
- o_t-在步骤t退出 。 例如 , 如果我们要预测句子中的单词 , 则输出可能是字典中的概率向量 。 o_t = softmax(Vs_t)
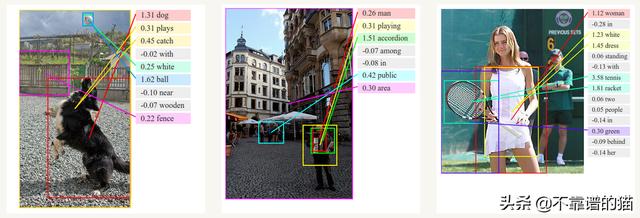
与卷积神经网络一起 , RNN被用作模型的一部分 , 以生成未标记图像的描述 。 组合模型将生成的单词与图像中的特征相结合:
 文章插图
文章插图最常用的RNN类型是LSTM , 它比RNN更好地捕获(存储)长期依赖关系 。 LSTM与RNN本质上相同 , 只是它们具有不同的计算隐藏状态的方式 。
LSTM中的memory称为cells , 您可以将其视为接受先前状态h_ {t-1}和当前输入参数x_t作为输入的黑盒 。 在内部 , 这些cells决定保存和删除哪些memory 。 然后 , 它们将先前的状态 , 当前memory和输入参数组合在一起 。
这些类型的单元在捕获(存储)长期依赖关系方面非常有效 。
#5递归神经网络
递归神经网络是循环网络的另一种形式 , 不同之处在于它们是树形结构 。 因此 , 它们可以在训练数据集中建模层次结构 。
由于其与二叉树、上下文和基于自然语言的解析器的关系 , 它们通常用于音频到文本转录和情绪分析等NLP应用程序中 。 然而 , 它们往往比递归网络慢得多
#6自编码器
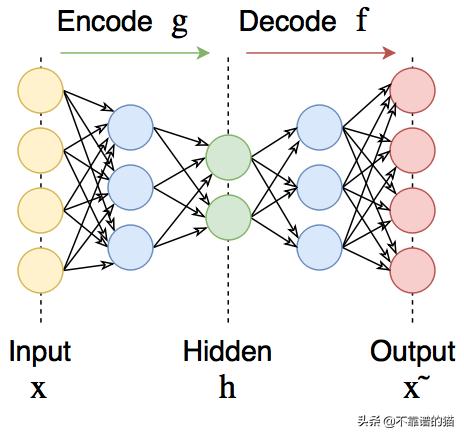
自编码器可在输出处恢复输入信号 。 它们内部有一个隐藏层 。 自编码器设计为无法将输入准确复制到输出 , 但是为了使误差最小化 , 网络被迫学习选择最重要的特征 。
 文章插图
文章插图自编码器可用于预训练 , 例如 , 当有分类任务且标记对太少时 。 或降低数据中的维度以供以后可视化 。 或者 , 当您只需要学习区分输入信号的有用属性时 。
#7深度信念网络和受限玻尔兹曼机器
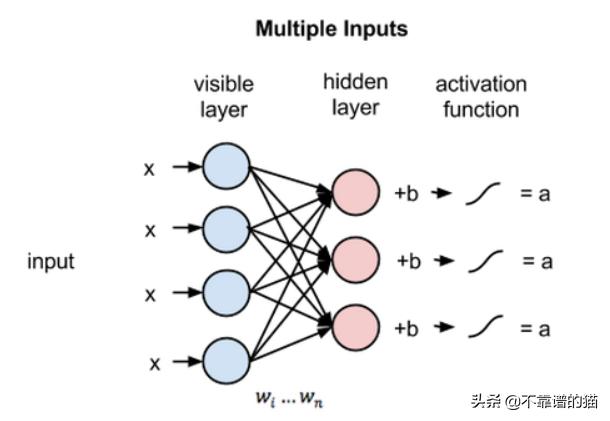
【深度学习算法完整简介】受限玻尔兹曼机是一个随机神经网络(神经网络 , 意味着我们有类似神经元的单元 , 其binary激活取决于它们所连接的相邻单元;随机意味着这些激活具有概率性元素) , 它包括:
- 可见单元层
- 隐藏单元层
- 偏差单元
 文章插图
文章插图为了使学习更容易 , 我们对网络进行了限制 , 使任何可见单元都不连接到任何其他可见单元 , 任何隐藏单元都不连接到任何其他隐藏单元 。
- 假期弯道超车 国美学习“神器”助孩子变身“学霸”
- 想自学Python来开发爬虫,需要按照哪几个阶段制定学习计划
- 未来想进入AI领域,该学习Python还是Java大数据开发
- Google AI建立了一个能够分析烘焙食谱的机器学习模型
- 学习大数据是否需要学习JavaEE
- 学习“时代楷模”精神 信息科技创新助跑5G智慧港口
- 创维小湃盒子P3 Pro深度评测
- 把时间花在更有价值的地方,关注这几个有深度的订阅号
- 非计算机专业的本科生,想利用寒假学习Python,该怎么入手
- 新基建下,系统集成商数字化建设及渠道管理深度解析