「系统架构」什么是链路追踪?分布式系统如何实现链路追踪?( 三 )
3、traceId 如何保证全局唯一
要保证全局唯一, 我们可以采用分布式或者本地生成的 ID 。 使用分布式的话 , 需要有一个发号器 , 每次请求都要先请求一下发号器 , 会有一次网络调用的开销 。 所以 SkyWalking 最终采用了本地生成 ID 的方式 , 它采用了大名鼎鼎的 snowflow 算法 , 性能很高 。
 文章插图
文章插图
snowflake 算法生成的 id
不过 snowflake 算法有一个众所周知的问题:时间回拨 , 这个问题可能会导致生成的 id 重复 。 那么 SkyWalking 是如何解决时间回拨问题的呢 。
 文章插图
文章插图
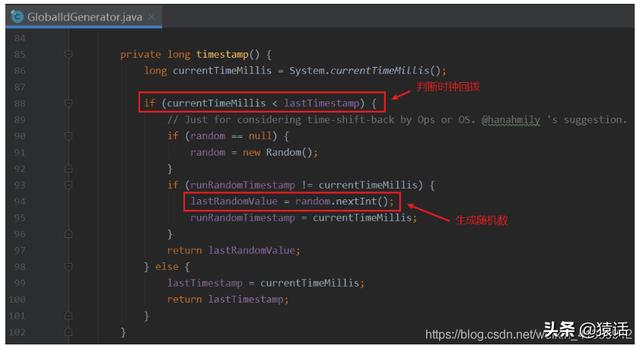
每生成一个 id , 都会记录一下生成 id 的时间(lastTimestamp) , 如果发现当前时间比上一次生成 id 的时间(lastTimestamp)还小 , 那说明发生了时间回拨 , 此时会生成一个随机数来作为 traceId 。 这里可能就有同学要较真了 , 可能会觉得生成的这个随机数也会和已生成的全局 id 重复 , 是否再加一层校验会好点 。
这里要说一下系统设计上的方案取舍问题了 , 首先如果针对产生的这个随机数作唯一性校验无疑会多一层调用 , 会有一定的性能损耗 , 但其实时间回拨发生的概率很小(发生之后由于机器时间紊乱 , 业务会受到很大影响 , 所以机器时间的调整必然要慎之又慎) , 再加上生成的随机数重合的概率也很小 , 综合考虑这里确实没有必要再加一层全局唯一性校验 。 对于技术方案的选型 , 一定要避免过度设计 , 过犹不及 。
4、请求量这么多 , 全部采集会不会影响性能?
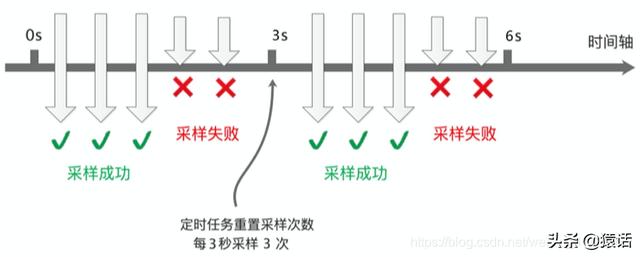
如果对每个请求调用都采集 , 那毫无疑问数据量会非常大 , 但反过来想一下 , 是否真的有必要对每个请求都采集呢?其实没有必要 , 我们可以设置采样频率 , 只采样部分数据 , SkyWalking 默认设置了 3 秒采样 3 次 , 其余请求不采样 , 如图所示:
 文章插图
文章插图
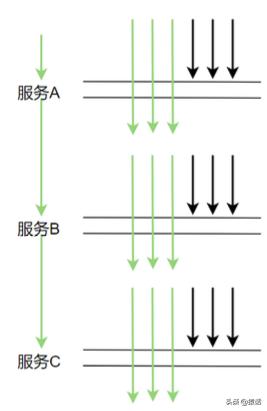
这样的采样频率其实足够我们分析组件的性能了 , 按 3 秒采样 3 次 , 这样的频率来采样数据会有啥问题呢 。 理想情况下 , 每个服务调用都在同一个时间点 , 这样的话每次都在同一时间点采样确实没问题 。 如下图所示:
 文章插图
文章插图
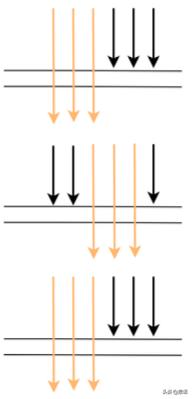
但在生产上 , 每次服务调用基本不可能都在同一时间点调用 , 因为期间有网络调用延时等 , 实际调用情况很可能是下图这样:
 文章插图
文章插图
这样的话就会导致某些调用在服务 A 上被采样了 , 在服务 B , C 上不被采样 , 也就没法分析调用链的性能 。
那么 SkyWalking 是如何解决的呢?
它是这样解决的:如果上游有携带 Context 过来(说明上游采样了) , 则下游将强制采集数据 , 这样可以保证链路完整 。
SkyWalking 的基础架构SkyWalking 的基础如下架构 , 可以说几乎所有的的分布式调用都是由以下几个组件组成的 。
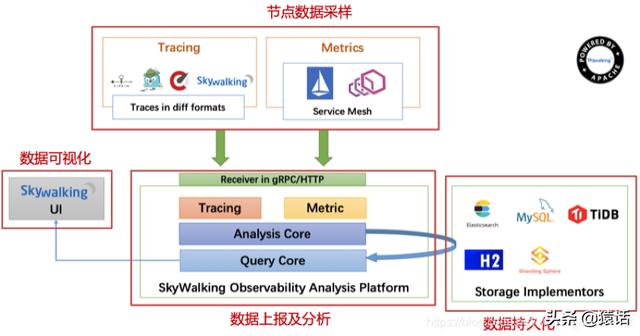 文章插图
文章插图
首先当然是节点数据的定时采样 , 采样后将数据定时上报 , 将其存储到 ES, MySQL 等持久化层 , 有了数据自然而然可根据数据做可视化分析 。
SkyWalking 的性能如何如下是官方的测评数据:
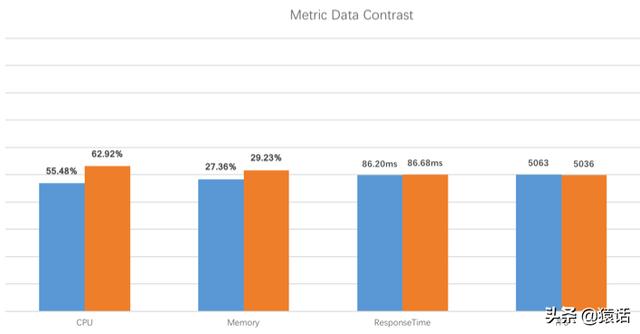 文章插图
文章插图
图中蓝色代表未使用 SkyWalking 的表现 , 橙色代表使用了 SkyWalking 的表现 , 以上是在 TPS 为 5000 的情况下测出的数据 , 可以看出 , 不论是 CPU , 内存 , 还是响应时间 , 使用 SkyWalking 带来的性能损耗几乎可以忽略不计 。
- vivo一款新机现身跑分网!运存和系统信息通通曝光
- vivo追求的本原设计是什么?X60 Pro给出了答案
- iQOO 7邀请函曝光“马”“鸭”“羊”代表什么
- 近期浙江引来这么多重磅级“帮手”传递什么信号?
- 都是为自己手机代言,为什么董明珠不行,雷军太行了?
- 有没有必要给老年人买台智能手机?
- 玩转光追大作最低需要什么配置?快来看小狮子的推荐
- 人瑞人才(06919):未来3年系统平台将发力智能化,打造职业生态链平台
- 消费者报告 | 美团充电宝电量不足也扣费,是质量问题还是系统缺陷?
- 谷歌修复Pixel 5系统音量问题 快门音效不再吵