「系统架构」什么是链路追踪?分布式系统如何实现链路追踪?( 二 )
 文章插图
文章插图
OpenTracing 的数据模型 , 主要有以下三个:
- Trace:一个完整请求链路
- Span:一次调用过程(需要有开始时间和结束时间)
- SpanContext:Trace 的全局上下文信息 , 如里面有traceId
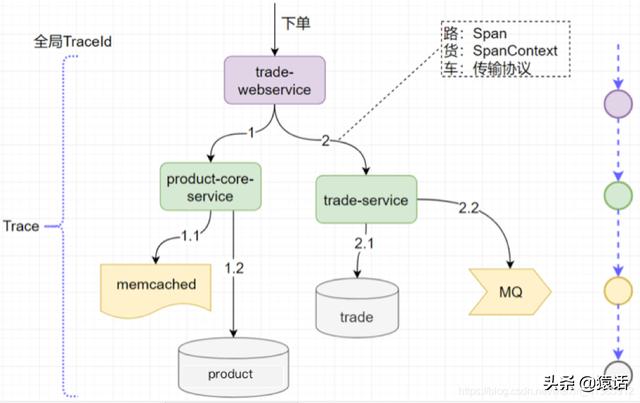 文章插图
文章插图如图所示 , 一次下单的完整请求就是一个 Trace 。 TraceId是这个请求的全局标识 。 内部的每一次调用就称为一个 Span , 每个 Span 都要带上全局的 TraceId , 这样才可把全局 TraceId 与每个调用关联起来 。 这个 TraceId 是通过 SpanContext 传输的 , 既然要传输 , 显然都要遵循协议来调用 。 如图所示 , 如果我们把传输协议比作车 , 把 SpanContext 比作货 , 把 Span 比作路应该会更好理解一些 。
理解了这三个概念 , 接下来我们就看看分布式追踪系统是如何采集图中的微服务调用链 。
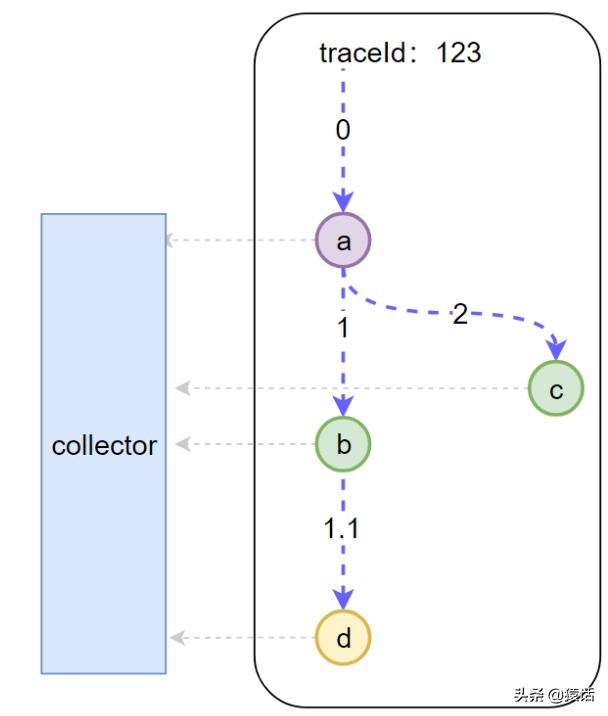 文章插图
文章插图我们可以看到底层有一个 Collector 一直在默默无闻地收集数据 , 那么每一次调用 Collector 会收集哪些信息呢 。
- 全局 trace_id:这是显然的 , 这样才能把每一个子调用与最初的请求关联起来
- span_id: 图中的 0 , 1 , 1.1 , 2 , 这样就能标识是哪一个调用
- parent_span_id:比如 b 调用 d 的 span_id 是 1.1 , 那么它的 parent_span_id 即为 a 调用 b 的 span_id 即 1 , 这样才能把两个紧邻的调用关联起来 。
 文章插图
文章插图根据这些图表信息显然可以据此来画出调用链的可视化视图如下:
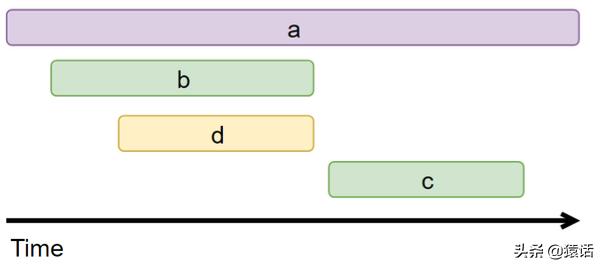 文章插图
文章插图于是一个完整的分布式追踪系统就实现了 。
以上实现看起来确实简单 , 但有以下几个问题需要我们仔细思考一下:
- 怎么自动采集 span 数据:自动采集 , 对业务代码无侵入
- 如何跨进程传递 context
- traceId 如何保证全局唯一
- 请求量这么多采集会不会影响性能
链路追踪系统SkyWalking的原理1、怎么自动采集 span 数据
【「系统架构」什么是链路追踪?分布式系统如何实现链路追踪?】SkyWalking 采用了插件化 + javaagent 的形式来实现了 span 数据的自动采集 , 这样可以做到对代码的无侵入性 。 插件化意味着可插拔 , 扩展性好 。 如下图所示:
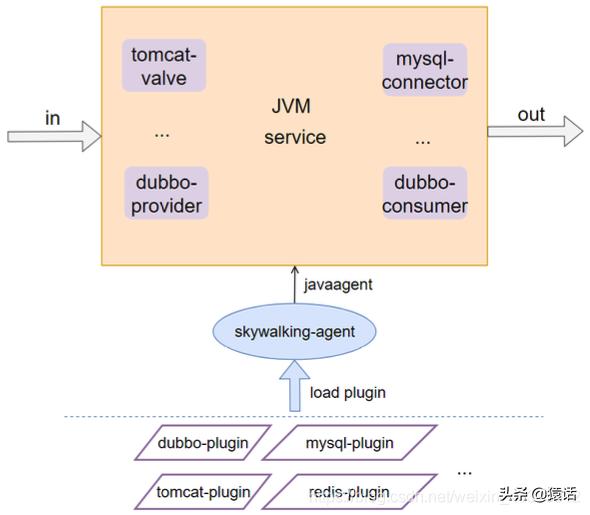 文章插图
文章插图2、如何跨进程传递 context
我们知道数据一般分为 header 和 body , 就像 http 有 header 和 body , RocketMQ 也有 MessageHeader , Message Body 。 body 一般放着业务数据 , 所以不宜在 body 中传递 context , 应该在 header 中传递 context , 如图所示:
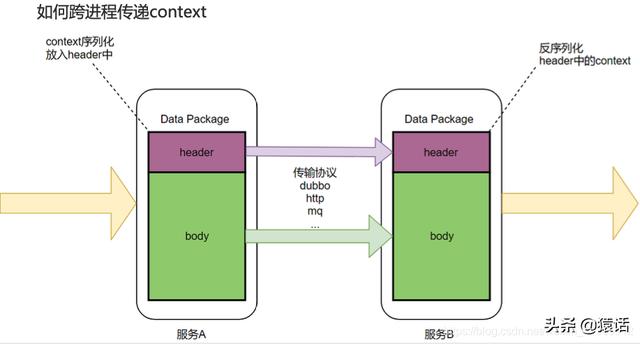 文章插图
文章插图dubbo 中的 attachment 就相当于 header , 所以我们把 context 放在 attachment 中 , 这样就解决了 context 的传递问题 。
 文章插图
文章插图
- vivo一款新机现身跑分网!运存和系统信息通通曝光
- vivo追求的本原设计是什么?X60 Pro给出了答案
- iQOO 7邀请函曝光“马”“鸭”“羊”代表什么
- 近期浙江引来这么多重磅级“帮手”传递什么信号?
- 都是为自己手机代言,为什么董明珠不行,雷军太行了?
- 有没有必要给老年人买台智能手机?
- 玩转光追大作最低需要什么配置?快来看小狮子的推荐
- 人瑞人才(06919):未来3年系统平台将发力智能化,打造职业生态链平台
- 消费者报告 | 美团充电宝电量不足也扣费,是质量问题还是系统缺陷?
- 谷歌修复Pixel 5系统音量问题 快门音效不再吵