PP-YOLO超越YOLOv4-目标检测的进步( 二 )
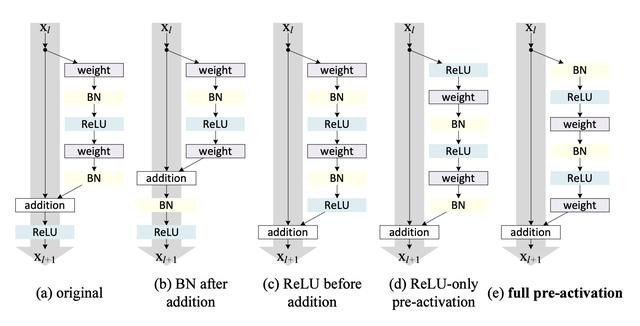
更换骨干网第一种PP YOLO技术是用Resnet50-vd-dcn ConvNet骨干替换YOLOv3 Darknet53骨干 。 Resnet是一个更流行的骨干 , 它的执行优化了更多的框架 , 并且其参数少于Darknet53 。 通过交换此骨干可以看到mAP的改进 , 这对PP YOLO来说是一个巨大的胜利 。
 文章插图
文章插图
模型参数的EMAPP-YOLO跟踪网络参数的指数移动平均 , 以保持模型权重的阴影预测时间 。 这已经被证明可以提高推理的准确性 。
更大的批量PP-YOLO将批量大小从64增加到192 。 当然 , 如果有GPU内存限制 , 这很难实现 。
DropBlock正则化PP-YOLO在FPN颈部实现DropBlock正则化(在过去 , 这通常发生在骨干) 。 在网络的给定步骤中 , DropBlock会随机删除一部分训练特征 , 以指示模型不依赖于关键特征进行检测 。
 文章插图
文章插图
IOU损失YOLO损失函数不能很好地转换为mAP指标 , 该指标在计算中大量使用了Union上的Intersection 。 因此 , 在考虑到最终预测的情况下编辑训练损失函数是很有用的 。 这个编辑也出现在YOLOv4中 。
IoU AwarePP-YOLO网络添加了一个预测分支 , 以预测给定对象的模型估计的IOU 。 在决定是否预测对象时包含此IoU Aware可提高性能 。
电网灵敏度旧的YOLO模型不能很好地在锚框区域的边界附近进行预测 。 为了避免这个问题 , 可以稍微不同地定义框坐标 。 YOLOv4中也有这种技术 。
矩阵非最大抑制非最大抑制是一种删除候选对象的提议以进行分类的技术 。 矩阵非最大抑制是一种并行排序这些候选预测的技术 , 它加快了计算速度 。
CoordConvCoordConv受ConvNets一个问题的激励 , 即ConvNets仅将(x , y)坐标映射到一个热像素空间 。 CoordConv解决方案使卷积网络可以访问其自己的输入坐标 。 CoordConv干预措施上方标有黄色菱形 。 有关更多详细信息 , 请参见CordConv文件 。
更好的预训练骨干PP YOLO的作者提炼出更大的ResNet模型作为骨干 。 更好的预训练模型显示也可以改善下游转移学习 。
PP-YOLO是最先进的吗?PP-YOLO胜过2020年4月23日发布的YOLOv4结果 。
- YOLOv4:
本文的重点是如何堆叠一些几乎不影响效率的有效技巧以获得更好的性能……本文无意介绍一种新颖的目标检测器 。 它更像一个食谱 , 它告诉你如何逐步构建更好的检测器 。 我们发现了一些对YOLOv3检测器有效的技巧 , 可以节省开发人员的反复试验时间 。 最终的PP-YOLO模型以比YOLOv4更快的速度将COCO的mAP从43.5%提高到45.2%
上面的PP-YOLO贡献参考将YOLOv3模型在COCO对象检测任务上从38.9 mAP提升到44.6 mAP , 并将推理FPS从58增加到73 。 论文中显示了这些指标 , 胜过了YOLOv4和EfficientDet的当前发布结果 。
在以YOLOv5为基准对PP-YOLO进行基准测试时 , YOLOv5似乎仍在V100上具有最快的推理精度(AP与FPS) 。 但是 , YOLOv5论文仍然有待发布 。 此外 , 研究表明 , 在YOLOv5 Ultralytics存储库上训练YOLOv4体系结构的性能要优于YOLOv5 , 并且 , 以可移植的方式 , 使用YOLOv5贡献进行训练的YOLOv4的性能将胜过此处发布的PP-YOLO结果 。 这些结果仍有待正式发布 , 但可以追溯到GitHub上的讨论 。
- “国产机王”的陨落,曾超越华为成国内第一,今却靠卖老人机求生
- 美国媒体:潘多拉魔盒被中国打开,韩国这项科技超越中国问鼎全球
- AMD台式机CPU市场份额15年来首次超越英特尔
- 崛起的中国芯片巨头,靠山寨起家,如今市场份额超越高通成第一
- 低调超越小米和三星,中国电视界的“统治者”,连续16年排第一
- 阿里达摩院发布2021十大科技趋势,人类有望借脑机接口超越生物学极限
- 超越高通!全球最大芯片组供应商诞生!市占率31%却很低调
- 芯片市场迎来“洗牌”,中国企业正式超越高通,比尔盖茨预言成真
- 中国IT巨头超越华为,仅次惠普全球第三,卖服务器赚1123亿
- 鸿蒙系统志在5G时代超越安卓,IoT生态发展缓慢问题亟待解决