PP-YOLO超越YOLOv4-目标检测的进步
 文章插图
文章插图
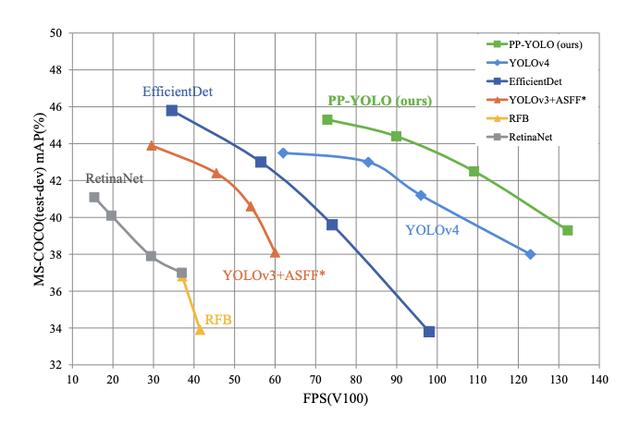
PP-YOLO评估指标比现有最先进的对象检测模型YOLOv4表现出更好的性能 。 然而 , 百度的作者写道:
本文不打算介绍一种新型的目标检测器 。 它更像是一个食谱 , 告诉你如何逐步建立一个更好的探测器 。
让我们一起看看 。
YOLO发展史YOLO最初是由Joseph Redmon编写的 , 用于检测目标 。 目标检测是一种计算机视觉技术 , 它通过在目标周围画一个边界框来定位和标记对象 , 并确定一个给定的框所属的类标签 。 和大型NLP transformers不同 , YOLO设计得很小 , 可为设备上的部署提供实时推理速度 。
YOLO-9000是Joseph Redmon出版的第二个“YOLOv2”目标探测器 , 它改进了探测器 , 并强调了该检测器能够推广到世界上任何物体的能力 。
 文章插图
文章插图
YOLOv3对检测网络做了进一步的改进 , 并开始将目标检测过程纳入主流 。 我们开始发布关于如何在PyTorch中训练YOLOv3、如何在Keras中训练YOLOv3的教程 , 并将YOLOv3的性能与EfficientDet(另一种最先进的检测器)进行比较 。
然后约瑟夫·雷德曼出于伦理考虑退出了目标探测游戏 。
当然 , 开源社区接过了指挥棒 , 继续推动YOLO技术的发展 。
YOLOv4最近由Alexey AB在他的YOLO Darknet存储库中发表 。 YOLOv4主要是其他已知的计算机视觉技术的集合 , 通过研究过程进行了组合和验证 。 请看这里深入了解YOLOv4 。
输入PP-YOLO 。
PP代表什么?PP是百度编写的深度学习框架PaddlePaddle的缩写 。
 文章插图
文章插图如果你不熟悉Paddle , 那我们就在同一条船上了 。 paddle最初是用Python编写的 , 它看起来类似于PyTorch和TensorFlow 。 深入研究paddle框架很有趣 , 但超出了本文的范围 。
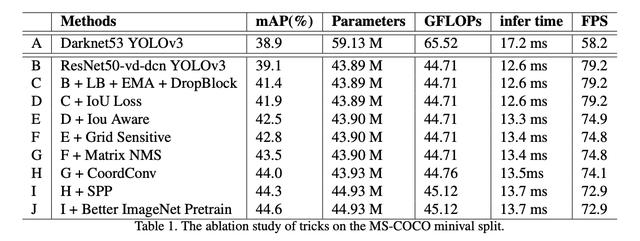
PP-YOLO贡献PP-YOLO的论文读起来很像YOLOv4论文 , 因为它是计算机视觉中已知的技术的汇总 。 新颖的贡献是证明这些技术的集成可提高性能 , 并提供消融研究 , 以研究每一步对模型的帮助程度 。
在我们深入研究PP-YOLO的贡献之前 , 先回顾一下YOLO检测器的体系结构 。
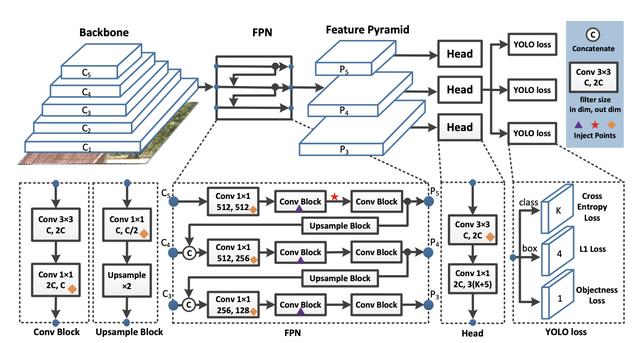
解剖YOLO检测器
 文章插图
文章插图YOLO检测器分为三个主要部分 。
YOLO Backbone:YOLO Backbone(骨干)是一个卷积神经网络 , 它将图像像素合并在一起以形成不同粒度的特征 。 骨干通常在分类数据集(通常为ImageNet)上进行预训练 。
YOLO Neck:YOLO Neck(上面选择了FPN)在传递到预测头之前对ConvNet图层表示进行组合和混合 。
YOLO Head:这是网络中进行边界框和类预测的部分 。 它由关于类 , 框和对象的三个YOLO损失函数指导 。
现在 , 让我们深入了解PP YOLO做出的贡献 。
 文章插图
文章插图
- “国产机王”的陨落,曾超越华为成国内第一,今却靠卖老人机求生
- 美国媒体:潘多拉魔盒被中国打开,韩国这项科技超越中国问鼎全球
- AMD台式机CPU市场份额15年来首次超越英特尔
- 崛起的中国芯片巨头,靠山寨起家,如今市场份额超越高通成第一
- 低调超越小米和三星,中国电视界的“统治者”,连续16年排第一
- 阿里达摩院发布2021十大科技趋势,人类有望借脑机接口超越生物学极限
- 超越高通!全球最大芯片组供应商诞生!市占率31%却很低调
- 芯片市场迎来“洗牌”,中国企业正式超越高通,比尔盖茨预言成真
- 中国IT巨头超越华为,仅次惠普全球第三,卖服务器赚1123亿
- 鸿蒙系统志在5G时代超越安卓,IoT生态发展缓慢问题亟待解决