训练轮数降至1/10,商汤等提出升级版DETR目标检测器
机器之心专栏
机器之心编辑部
今年 5 月底 , Facebook AI 提出了DETR , 利用 Transformer 去做目标检测 , 该方法去除了许多目标检测中的人工设计组件 , 同时展现了非常好的性能 。 但是 , DETR 存在收敛速度慢和特征分辨率有限等缺陷 。 为了解决这些问题 , 来自商汤研究院等机构的研究者提出了可变形 DETR , 其注意力模块仅关注于参考点附近的一小部分采样点作为注意力模块中的 key 元素 。 可变形 DETR 可以在比 DETR 少 9/10 的训练轮数下 , 达到更好的性能(尤其是在小物体上) 。 在 COCO 基准上的大量实验表明了该方法的有效性 。
 文章插图
文章插图
论文链接:
DETR 收敛慢、计算复杂度高的固有缺陷催生了可变形 DETR
当今的目标检测器大多使用了人工设计的组件 , 如锚框生成、基于规则的训练目标分配、非极大值抑制后处理等 。 所以它们不是完全端到端的 。 Facebook AI 提出的 DETR【1】无需这些手工设计组件 , 构建了第一个完全端到端的目标检测器 , 实现了极具竞争力的性能 。 DETR 采用了一个简单的结构 , 即结合了卷积神经网络和 Transformer 【2】的编码器-解码器结构 。 研究人员利用了 Transformer 既通用又强大的关系建模能力来替代人工设计的规则 , 并且设计了恰当的训练信号 。
虽然DETR的设计非常有趣 , 而且性能也很好 , 但它自身也存在着如下两个问题:
与现有的目标检测器相比 , 它需要更长的训练轮数才能收敛 。 比如 , 在 COCO 基准【3】上 , DETR 需要 500 个 epoch 才能收敛 , 这比 Faster R-CNN【4】慢了 10 到20倍;
DETR 在检测小物体上表现出了较差的性能 。 当今的目标检测器通常利用了多尺度的特征 , 从而小物体可以从高分辨率的特征图中检测 。 但是对于 DETR 来说 , 高分辨率的特征图将带来不可接受的计算复杂度和内存复杂度 。
以上提到的问题可以主要是由于 Transformer 中的组件在处理图像特征图时的天生缺陷 。 在初始化时 , 注意力模块(如公式(1)所示)的注意力权重近似均匀地分布在特征图的所有像素上 , 所以需要非常长的训练轮数来学习将注意力权重集中于稀疏的有意义的位置 。 另一方面 , Transformer 的编码器中注意力权重计算的复杂度与像素个数的平方成正比 。 因而它需要非常高的计算和内存复杂度来处理高分辨率的特征图 。
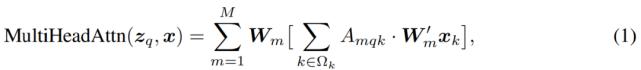 文章插图
文章插图
在图像领域 , 可变形卷积【5】是一个非常强大而且高效的机制 , 它将注意力集中于稀疏的空间位置 。 虽然天生避免了上面提到的这些问题 。 但它缺乏关系建模机制这一元素 , 而这是 DETR 成功的一大关键 。
所以 , 在本文中 , 来自商汤研究院和中科大的研究者提出了可变形 DETR , 解决了 DETR 收敛慢、计算复杂度高这两大问题 。
可变形 DETR 方法和模型解读
具体而言 , 可变形 DETR 结合了可变形卷积中的稀疏空间采样的优势和 Transformer 中的关系建模能力 。 研究者提出了可变形注意力模块(如公式(2)所示) , 它关注于一小部分采样的位置 , 作为从特征图所有像素中预先筛选出显著的 key 元素 。
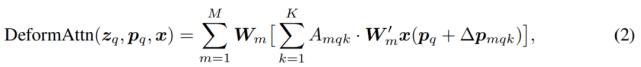 文章插图
文章插图
这一模块天生可以被扩展到聚合多尺度特征上(如公式(3)所示) , 而不需要 FPN【6】的帮助 。
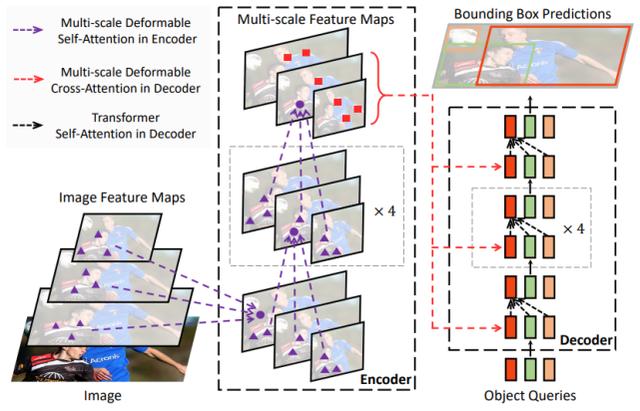
可变形 DETR 目标检测器用(多尺度)可变形注意力模块替换 Transformer 注意力模块来处理特征图 , 如下图 1 所示 。
 文章插图
文章插图
- 研究人员吐槽当前AI训练效率过于低下
- 研究人员吐槽当前的AI训练效率不高 浪费太多精力和能源
- 等不及明年生效:苹果已将部分开发者佣金从30%降至15%
- 小米WiFi6路由降至新低价,将与小米11同步登场
- AMD 准备为 OEM 厂商供货两款 Ryzen 5000 系列桌面 CPU,TDP 降至 65W
- 挺进云端AI训练&推理双赛道!独家对话燧原科技COO张亚林:揭秘超高效率背后的“内功”
- 华为胡厚崑:中国有全球最好5G网,年底5G模组价降至一百美元
- 心率训练法科学指导 华为健跑沙龙北京站热情开跑
- 失业的盲人按摩师,转型做AI训练师,想带动中国1700万盲人
- 健康运动势在必行,华为科学训练营深圳站开跑