研究人员吐槽当前的AI训练效率不高 浪费太多精力和能源
本月早些时候 , 谷歌迫使某位研究人员撤回了一篇论文 , 其中提到了谷歌当前在搜索和其它文本分析产品中使用的语言处理人工智能所存在的风险 。 此外据某些估计 , 训练一款 AI 模型所产生的碳排放 , 甚至与建造和驾驶五辆汽车到报废的总量相当 。 究其原因 , 还是当前的 AI 训练效率太过低下 。
 文章插图
文章插图
教机器人走路难 , 教 AI 懂人话更难 。
为了深入了解 AI 训练与传统数据中心计算有何不同 , ArsTechnica特地发表了一篇来自 AI 研究与模型开发专业人员的分析文章 。
据悉 , 传统的数据中心任务 , 主要涉及视频流、电子邮件、以及社交媒体的处理 。 与之相比的是 , AI 训练需要耗费更多的计算量 。
在投入实际应用之前 , AI 模型需要汲取大量的数据、知道其学会如何理解用户的输入 。 遗憾的是 , 与人类的学习方式相比 , 这种训练的效率实在太过低下 。
现代 AI 需要借助人工神经网络来模拟人脑神经元的数学运算 , 神经元之间的连接强度 , 亦是该网络的一个重要参数(权重) 。
为了学习如何理解语言 , 网络需要从随机权重开始并进行调整 , 知道输出让人感到满意的“正确答案” 。
 文章插图
文章插图
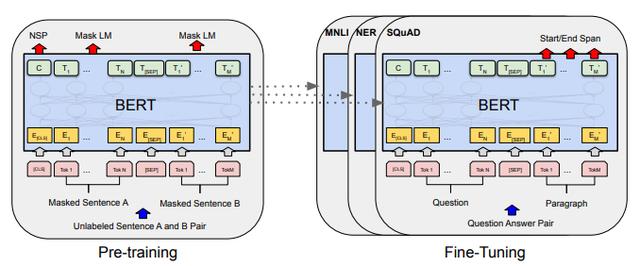
BERT 研究配图(来自:PDF)
训练语言网络的一种常见方法 , 是从维基百科和新闻媒体等网站提取大量文本 , 遮盖其中的部分单次 , 然后让 AI 模型尝试猜出正确的答案 。
虽然一开始很容易乱成一锅粥 , 但随着投喂数据量的不断增加、以及学习的深入 , 神经网络的连接权重和数据提取模式也会不断作出调整 , 最终带来准确率的逐渐提升 。
以最近的某个双向编码器交涉(BERT)模型为例 , 其学习了英语书籍和维基百科的 33 亿字内容 , 然后通过 40 次的反复锤炼 , 才勉强达到了可用的水平 。
作为对比 , 一名才五岁的人类小孩 , 尽管其听取的词量不到 BERT 的 1/3000 , 都不至于像 AI 模型这般需要费心费力地去教 。
 文章插图
文章插图
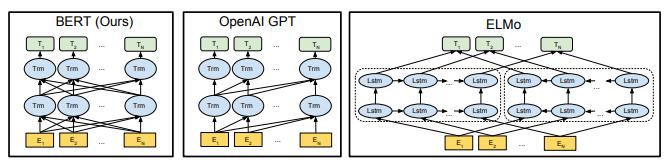
训练前模型结构的差异
显然 , 与其盲目地让机器和 AI 算法通过不断重复学习、来学会如何像人类一样思考 , 不如为语言模型选择一个更合适的训练架构 , 从而大幅削减其构建成本 。
有鉴于此 , 一些研究人员想到了一种更加合适的方案 —— 考虑学习期间需要动用多少个神经元、神经元之间有多少个连接、参数应以多快的速度发生改变等 。
随着尝试的组合越来越多 , 语言网络的精度提升机会也变得越来越大 。 相比之下 , 人脑并不需要费力地去寻得最佳结构 , 因为祖先早在进化过程中就替我们承受了这些苦难 。
近年来 , 企业和学术界在不断搅动 AI 领域的竞争 , 毕竟即使 1% 的准度提升 , 也会带来相当显著的优势 —— 尤其是机器翻译等难度相对较高的任务处理上 。
然而为了抢占宣传上的制高点 , 研究人员可能需要对模型展开数千次的训练、每次动用不同的结构方案 , 才能找到提升哪怕 1% 的最佳实现 , 即便这么做也会造成能源的大量浪费 。
 文章插图
文章插图
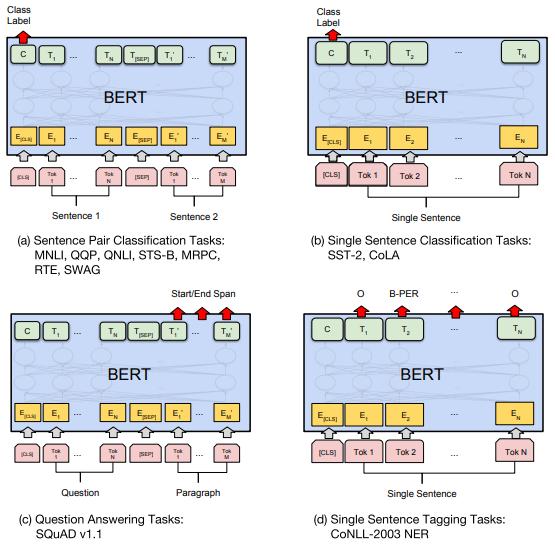
不同任务上的微调
通过测量训练期间使用的通用硬件功耗 , 马萨诸塞州大学阿默斯特分校的研究人员们 , 已经估算出了各种 AI 语言模型的能源开销 。
结果发现 , 训练 BERT 所产生的碳足迹 , 已相当于搭乘飞机往返纽约和旧金山 。 如果动用不同的结构进行检索 , 总成本更是可以高达 315 名乘客 / 甚至一架波音 747 的碳足迹 。
- 研究人员吐槽当前AI训练效率过于低下
- 鸿蒙饱受花粉吐槽,但却是华为的一步好棋?
- 事关“不配送充电头”一事!官媒正式发话!“吐槽”必须有
- 从华为Mate40Pro换到iPhone 12,这几点得吐槽
- 用户吐槽AirPods Max容易捂到冒汗 若受损或需付费维修
- 小米 11 官方保护壳被吐槽 后摄无保护根本不值得推荐
- 华为鸿蒙手机太难了!引发开发者大吐槽:为何没有自己独特风格?
- 苹果AirPods Max被吐槽:耳罩内会形成大量水滴
- 高下立判!马云吐槽马斯克的梦想,任正非却表示要包容
- 芯片巨头吐槽美国,欧洲17国做出决定,余承东这次说对了