快速入门ElasticSearch(上)( 三 )
如果出现下面的错误:
failed to send join request to master [{master}{4f6DA5uJQ8iJokZ3T18gjg}{2dOtfXXbTrynhShWrzt3xQ}{127.0.0.1}{127.0.0.1:9300}{ml.machine_memory=8374956032, ml.max_open_jobs=20, xpack.installed=true, ml.enabled=true}], reason [RemoteTransportException[[master][127.0.0.1:9300]那是因为之前复制ElasticSearch文件时 , 将其data目录下的文件也一同复制了 , 因此需要清空data文件夹 , 然后再进行重试即可 。
ElasticSearch基础概念首先是集群和节点的概念 , 我们知道集群是由一个或多个节点组成的 , 如前面我们搭建的具有三个节点的集群 , 其默认名称为ElasticSearch , 但是前面我们通过cluster.name参数将其修改为envythink 。 请注意对于任意一个节点来说 , 其集群的名字只能有一个 , 实际上所有的节点都是靠这个集群的名称来加入集群的 。 此外每个节点都有自己的名字 , 可以通过node.name来自定义 , 同时节点都是可以存储数据 , 参与集群索引数据 , 以及搜索数据的独立服务 。 其次是索引 , 你可以将其理解为是含有相同属性的文档集合 。 接着是类型 , 一般来说索引可以定义一个或者多个类型 , 但是文档必须是属于一个类型 。 那么问题来了 , 文档又是什么呢?文档就是可以被索引的基本数据单位 , 如用户的个人信息 , 它是ElasticSearch中最基本的存储单位 。 索引在ElasticSearch中是通过名字来识别的 , 且它必须是英文字母小写 , 且不含中划线 , 我们都是通过名字来对文档数据进行增删改查等操作 。
关于索引、类型和文档这三者之间的关系 , 可以借鉴数据库的相关知识 , 将索引类比为数据库;类型类比为数据表;而文档就是一行SQL记录 。 再来举一个较为详细的系统 , 假设我们这里有一个信息查询系统 , 此处使用ElasticSearch来作存储 , 那么里面的数据就可以分为各种各样的索引 , 如图书索引 , 服装索引 , 电器索引等 , 而对于图书索引又可以细分为文学类、工具类、技术类等类型 , 而具体到每一本书籍则就是文档 , 也就是最小的存储单位 。
和索引相关还有两个比较重要的概念就是分片和备份 。 每个索引都有多个分片 , 每个分片就是一个Lucene索引 。 而拷贝一份分片就完成了分片的备份 。 使用分片可以将索引进行拆分 , 可以分担每一个索引上的压力 , 同时分片还允许用户进行水平扩展和拆分 , 以及分布式的操作 , 可以提高搜索以及其他操作的效率 。 使用备份的好处就是当一个主分片出现问题时 , 备份的分片就可以代替工作 , 从而提高了ElasticSearch的可用性 , 同时备份的分片也支持搜索操作 , 可以减轻搜索的压力 。 ElasticSearch默认在创建索引时 , 会创建5个分片 , 一个用于备份 , 当然这个数据也是可以修改的 。 此外分片的数量只能在创建索引的时候指定 , 而不能在后期进行修改 , 但是备份却是可以动态修改的 。
ElasticSearch基本用法由于ElasticSearch使用的是RESTful风格的API , 因此在学习ElasticSearch的基本用法之前 , 需要了解ElasticSearch中API的基本格式:http://
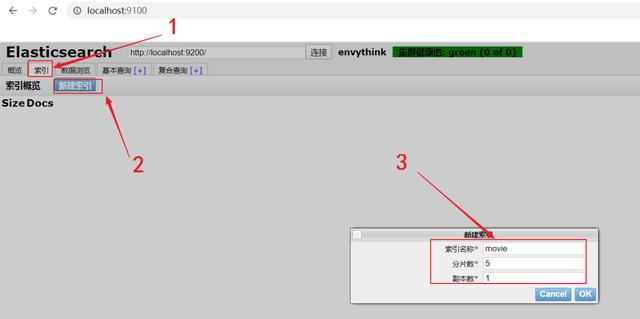
创建索引接下来可以结合之前的Head插件来显式创建索引 , 点击左上角的索引-->创建索引-->填入数据-->点击确定(注意这里的movie是索引名称 , 必须是英文小写 , 且不能使用中划线):
 文章插图
文章插图
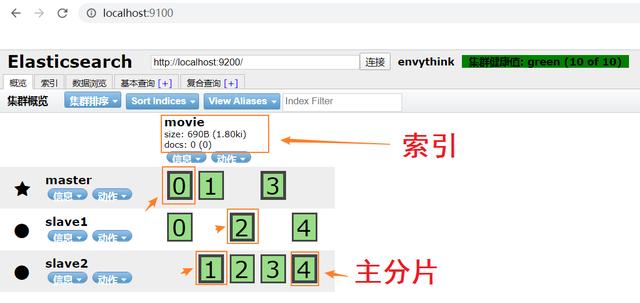
之后回到首页 , 可以看到页面出现了10个绿底黑字的方框 , 这些都是ElasticSearch的分片 , 如下所示:
 文章插图
文章插图
- 苹果两款新iPad齐曝光:性能提高、入门款更轻薄、售价便宜
- “千店同开”引质量担忧,小米回应
- RHEL 9提升了x86_64处理器的入门要求
- 企业|技术快速迭代倒逼知识产权“贴身”服务,上海首家AI商标品牌指导站入驻徐汇西岸
- 三星Galaxy A52 5G通过3C认证 支持最高15W快速充电
- 入门HiFi享好声,这几款耳机绝对值得入手
- 大健康速递丨腾讯上线疫苗接种服务区;华大基因研发出快速鉴定盒
- DIY从入门到放弃:电源挑贵的买就靠谱吗?
- 小米联合京东及爱回收推全新换机服务 帮你快速换新机
- 西安奕斯伟硅产业基地项目建设刷新我国建设大硅片制造项目的最快速度