扩展图神经网络:暴力堆叠模型深度并不可取( 四 )
SIGN 主要的优点在于其可扩展性与效率 , 我们可以使用标准的 mini-batch 梯度下降方法训练它 。
我们发现 , 在保持与目前最先进的 GraphSAINT 模型准确率非常接近的条件下 , 在推理阶段 , SIGN 的运算速度比 ClusterGCN 和 GraphSAINT 要快两个数量级;而在训练阶段 , SIGN 也要比它们快得多 。
 文章插图
文章插图
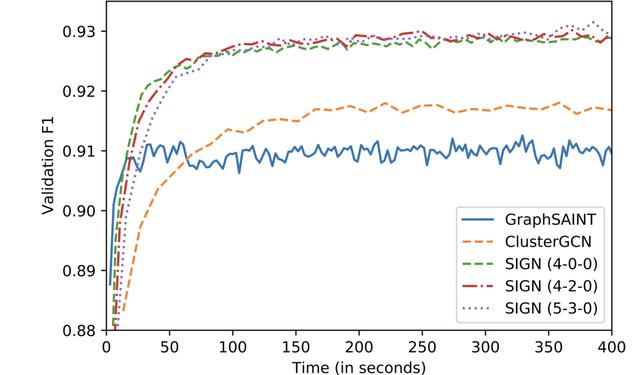
图 3:在 OGBN-Product 数据集上 , 不同方法的收敛情况 。 SIGN 的各种变体都要比GraphSAINT 和 ClusterGCN 收敛地更快 , 并且能够在验证中得到更高的 F1 分数 。
 文章插图
文章插图
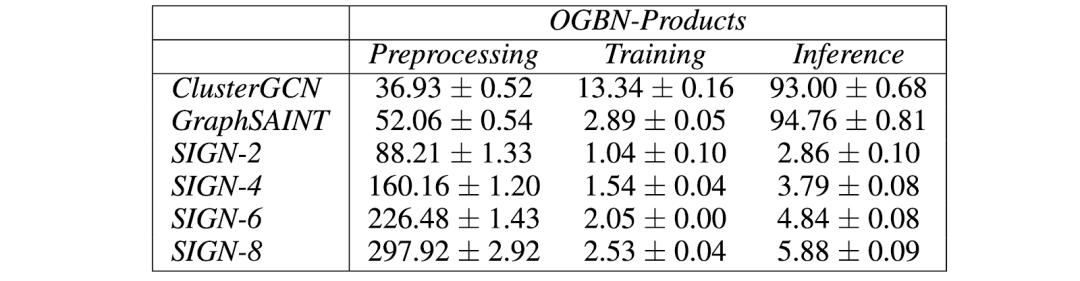
图 4:在 OGBN-Product 数据集上 , 不同方法的预处理、训练、推理时间(单位:秒) 。 尽管 SIGN 的预处理过程较为缓慢 , 但是 SIGN 在训练阶段要比对比基线快得多 , 并且在推理阶段要比其它方法快上近两个数量级 。
此外 , 我们的模型也支持任意的传播算子 。 对于不同类型的图而言 , 也许我们必须处理不同的传播算子 。
我们发现 , 有一些任务可以获益于基于模体的算子(如三角形计数) 。
 文章插图
文章插图
图 5:在一些流行的数据集上 , SIGN 模型以及其它可扩展方法在节点分类任务中的性能 。 基于三角模体的传播算子在 Flickr 数据集上取得了较大的性能提升 , 在 PPI 和 Yelp 数据集上也有一定的性能提升 。
尽管受限于只拥有单个图卷积层 , 以及只使用了线性传播算子 , SIGN 实际上可以良好运行 , 取得了与更加复杂的模型相当、甚至更好的性能 。 由于 SIGN 具有很快的运算速度并且易于实现 , 我们期待 SIGN 成为一种大规模应用的图学习方法的简单对比基线 。
也许 , 更重要的是 , 由于这种简单的模型取得了成功 , 我们不禁要提出一个更本质的问题:「我们真的需要深度的图神经网络吗」?
我们推测 , 在许多面向社交网络以及「小世界」图的学习问题中 , 我们需要使用更为丰富的局部结构信息 , 而不是使用暴力的深度架构 。
有趣的是 , 由于算力的进步以及将较为简单的特征组合为复杂特征的能力 , 传统的卷积神经网络架构朝着相反的方向发展(使用更小卷积核的更深的网络) 。
我们尚不明确同样的方法是否适用于图学习问题 , 因为图的组合性要复杂得多(例如 , 无论网络有多深 , 某些结构都不能通过消息传递来计算) 。
当然 , 我们还需要通过更多详细的实验来验证这一猜想 。
参考引用:
[1] The recently introduced Open Graph Benchmark now offers large-scale graphs with millions of nodes. It will probably take some time for the community to switch to it.
[2] T. Kipf and M. Welling, Semi-supervised classification with graph convolutional networks (2017). Proc. ICLR introduced the popular GCN architecture, which was derived as a simplification of the ChebNet model proposed by M. Defferrard et al. Convolutional neural networks on graphs with fast localized spectral filtering (2016). Proc. NIPS.
[3] As the diffusion operator, Kipf and Welling used the graph adjacency matrix with self-loops (i.e., the node itself contributes to its feature update), but other choices are possible as well. The diffusion operation can be made feature-dependent of the form A(X)X(i.e., it is still a linear combination of the node features, but the weights depend on the features themselves) like in MoNet [4] or GAT [5] models, or completely nonlinear, (X), like in message-passing neural networks (MPNN) [6]. For simplicity, we focus the discussion on the GCN model applied to node-wise classification.
- 腾讯与长三角G60科创走廊“牵手”:扩展科创“朋友圈”推进城市数字化转型
- 影驰发布经典版RTX 3090/3080:暴力涡轮风扇成了新潮
- 欧版Galaxy S21系列将不支持 MicroSD 卡扩展
- AMD专利泄密:RDNA3显卡暴力堆核
- 戴尔WD19TB扩展坞 轻薄办公好帮手
- 外接内置一样快!希捷Xbox Series X存储扩展卡评测
- OPPO正在研发一款屏幕可垂直扩展的智能手机
- 海外运营商暴力屏蔽小米双卡功能,遭到用户起诉
- WD西数推出雷电3 SSD扩展坞,2TB固态87W PD快充
- Sonnet发布eGPU外接扩展盒750和750ex