扩展图神经网络:暴力堆叠模型深度并不可取( 二 )
该论文的核心思想是 , 为了用一个 L 层的 GCN 计算某个节点上的训练损失 , 只需要聚合该节点 L 跳之内邻居节点的信息 , 而在计算中不考虑图中更远一些的节点 。
但问题在于 , 对于这种符合「小世界」模型的图(例如社交网络) , 由某些节点 2 跳内的邻居组成的子图可能就已经包含数百万的节点了 , 这使得我们很难将其存储在内存中 。
GraphSAGE 通过至多对 L 跳的邻居进行采样来解决该问题:从正在训练的节点开始 , 该算法多次有放回地均匀采样 k 个 1 跳邻居;接着 , 对于每一个该节点的邻居节点 , 算法以相同的方式再采样 k 个邻居节点 , 以此迭代式地采样 L 次 。 通过这种方式 , 我们保证对于每个节点而言 , 可以聚合有界的 L 跳规模为 O(k?) 的采样邻居节点 。
如果我们使用 b 个训练节点构建一个 batch , 且每个节点的 L 跳邻居节点相互独立 , 那么我们就会得到与图的规模 n 无关的空间复杂度 O(bk?) 。 使用 GraphSAGE 算法时 , 一个 batch 的计算复杂度为 O(bLd2k?) 。
 文章插图
文章插图
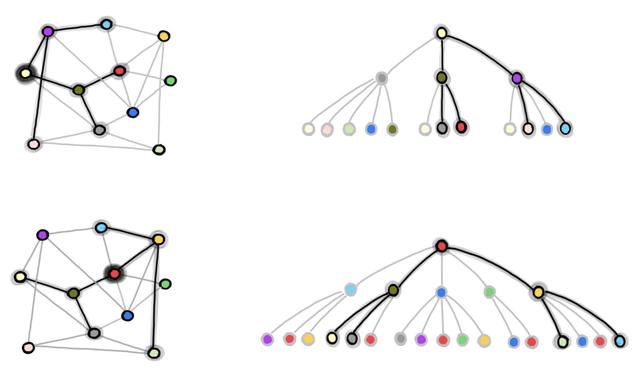
图 1:GraphSAGE 的邻居节点采样过程 。 我们从完整的图中下采样得到包含 b 个节点的 batch (在本例中 , b=2 , 我们将红色和淡黄色的节点用于训练) 。 在右侧的图中 , 我们采样得到 2 跳邻居节点图 , 将其用于独立地计算红色和淡黄色节点的图嵌入和损失 。
GraphSAGE 有一个显著的缺点 , 即采样得到的节点可能会出现很多次(由于有放回的抽样) , 因此可能会引入大量冗余的计算 。 例如 , 在上图中 , 深绿色的节点在两个训练节点的 L 跳邻居中都出现了 。 因此 , 在一个 batch 中 , 该深绿色节点的嵌入会被计算两次 。
随着 batch 大小 b 和采样节点个数 k 的增长 , 冗余计算的规模也会增大 。 此外 , 对于每个 batch 而言 , 尽管拥有 O(bk?) 的空间复杂度 , 但只会利用 b 个节点计算损失函数 。 因此 , 从某种程度上说 , 对于其它节点的计算也是一种浪费 。
在 GraphSAGE 之后 , 许多后续的工作重点关注改进 mini-batch 的采样过程 , 从而减少 GraphSAGE 中的冗余计算 , 并使得每个 batch 更加高效 。
ClusterGCN 和 GraphSAINT 是该研究方向最新的工作 , 它们采用了「图采样」(与 GraphSAGE 的邻居节点采样相对应)技术 。
 文章插图
文章插图
在图采样方法中 , 我们在每一个 batch 中采样得到原始图的一个子图 , 然后在整个子图上运行类似于 GCN 的模型 。 在这里 , 我们面临的挑战是 , 需要保证这些子图保留了大多数原始的边 , 并且能展现出有意义的拓扑结构 。
为了实现上述目标 , ClusterGCN 首先对图进行了聚类;然后 , 在每一个 batch 中 , 该模型会在一个聚类上进行训练 。 这使得每个 batch 中的节点会联系得尽可能的紧密 。
GraphSAINT 则提出了一种通用的概率化的图采样器 , 它通过在原始的图中采样子图来构建用于训练的 batch 。
我们可以根据不同的方案设计图采样器:例如 , 该采样器可以执行均匀节点采样、均匀边采样 , 或者通过使用随机游走计算节点的重要性、将其用于采样的概率分布从而进行「重要性采样」 。
请注意 , 进行采样的好处之一是:在训练时 , 采样可以作为一种边级别上的「dropout」技术 , 它可以对模型进行正则化 , 从而提升模型的性能 。 然而 , 在推理时 , 边 dropout 仍然需要看到所有的边 , 而在上述方法中 , 我们这些无法获得这些边的信息 。
图采样技术的另一个影响是 , 它可以减少在邻居节点指数级增长的情况下 , 存在的「信息瓶颈」及其造成的「过度挤压」现象 。
- 腾讯与长三角G60科创走廊“牵手”:扩展科创“朋友圈”推进城市数字化转型
- 影驰发布经典版RTX 3090/3080:暴力涡轮风扇成了新潮
- 欧版Galaxy S21系列将不支持 MicroSD 卡扩展
- AMD专利泄密:RDNA3显卡暴力堆核
- 戴尔WD19TB扩展坞 轻薄办公好帮手
- 外接内置一样快!希捷Xbox Series X存储扩展卡评测
- OPPO正在研发一款屏幕可垂直扩展的智能手机
- 海外运营商暴力屏蔽小米双卡功能,遭到用户起诉
- WD西数推出雷电3 SSD扩展坞,2TB固态87W PD快充
- Sonnet发布eGPU外接扩展盒750和750ex