燧原科技张亚林:解构数据中心AI系统“全垒打”和“全维度”|GTIC2020( 二 )
在计算卡部分 , NVIDIA Tesla系列一直是NVIDIA计算卡的主打 , 其中包括了有名的Tesla V100、A100和Tesla T4 。 同时AMD积极布局其Instinct MI系列 , 并在不久前推出了MI100 。 计算卡的部分衍生出来就是数据中心的业务 。
在图形卡部分 , NVIDIA有其NVIDIA RTX系列 , AMD拥有其AMD RX系列 , 这些部分衍生出来就是游戏业务 。
因此NVIDIA和AMD两大巨头通过对计算卡和图形卡的分离 , 已经形成了完全不同的产品线和架构 。
二、数据中心AI系统“全垒打”和“全维度”数据中心AI系统“全垒打”是什么样的?
张亚林说 , AI大系统要落地数据中心 , 必须具备四个要素 , 分别为系统、板卡、高性能高算力的芯片 , 以及全栈的软件系统 。 这四大要素构成了整个AI系统的“全垒打” 。
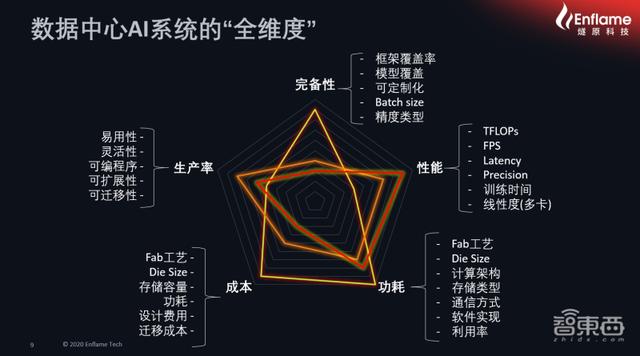
而对于衡量一个数据中心AI系统真正能被市场化、产业化、规模化的标准 , 张亚林分了五个维度来解读 , 这五个维度分别为AI系统的完备性、生产率、成本、功耗和性能 。
 文章插图
文章插图
数据中心AI系统的“全维度”
从完备性角度来讲 , 厂商必须具备很好的软件框架覆盖率、模型的覆盖率 , 还能满足用户的可定制化要求 。
在生产率角度 , 厂商必须能从用户的角度出发 , 适应用户的开发效率、易用性、灵活性、可编程性和可迁移性 。
在成本方面 , 有整个芯片的成本、板卡的成本、服务器的成本 , 还有迁移成本 。
在功耗方面 , 整个芯片架构、存储类型、通信方式、软件实现以及利用率还有工艺都左右了功耗大小 , 也直接影响了后续的运维成本 。
在性能方面 , 算力、延迟、精度、训练时间、推理时间、线性度(多卡)都对性能维度有影响 。
因此 , 通常一个AI系统的“全维度”设计必须在五个维度之间平衡 , 再去迭代 , 保证能够找到这五个纬度在用户侧最好的差异化以及最优解 , 才能让整个产品更有亮点 。
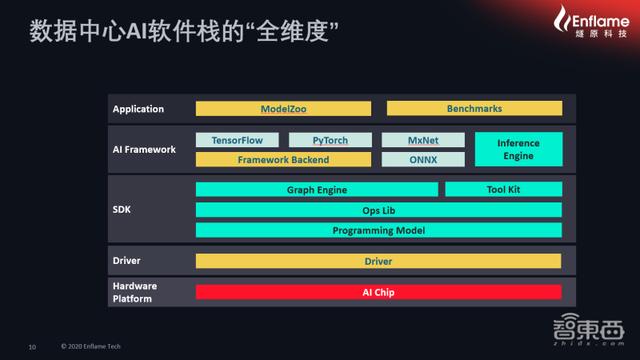
接着 , 张亚林特别就数据中心AI软件栈的“全维度”做了解构 , 他说 , 一个合格的、能商业化的、能让用户开发 , 且具有很强迁移度的软件栈 , 应该在应用层、框架层、SDK层和驱动层这四个层面进行布局 。
 文章插图
文章插图
数据中心AI软件栈的“全维度”
自顶向下来看 , 从应用层的角度来讲 , 它必须具备很强的模型库 , 在模型库的丰富程度方面 , 燧原科技已经拥有了100多个模型 。 此外 , 在Benchmark方面必须有很强的基准测试能力 , 提供很强的基准测试标准 , 才能让用户在基准模式上的适用度更强 。
接下来是框架层 , 目前业内通用的是TensorFlow、PyTorch两个主流框架 , 以及通过ONNX往下接入的部分 , 还有在非框架部分的推断引擎、推理引擎都是非常重要的框架性元素 。
在框架层之下是整个全栈的SDK , 也就是用户开发包 , 包括整个图形分解的引擎、图优化的引擎以及整个算子库 , 还有能使整个算子开发的编程模型和工具链 。
在SDK下面是驱动层 , 驱动层和整个硬件下的AI芯片进行衔接 。
而要想合理设计一个数据中心的AI芯片 , 必须从计算、数据、存储、互联四个角度看问题 。
从芯片计算的本身出发 , 算力大小及有效算力是燧原科技一直在追寻的终极目标 。 如何通过数据的传输、存储和吞吐量 , 为计算引擎合理地输入和输出 , 保证它的有效算力 , 也是燧原科技考虑的因素 。
在存储方面 , 分布式的存储大小在平衡片内存储、片外存储 , 以及实现存储的高效移动都是非常重要的命题 。
在互联方面 , 整个数据中心朝着集群化、系统化的方向发展 , 整个软件栈也在朝着分布式的方向发展 , 如何提升互联的效率、线性度和速度 , 以使整个大系统、大集群像一个虚拟化的计算池一样执行 , 也是一个很重要的命题 。
- 国家超算郑州中心首批重大科技专项启动
- 青岛海科展:五年磨一剑,科技力量助力海洋强国
- 莆田:科技与创意引领制鞋新模式
- 德国专家:中国这项顶尖科技尚未突破,还请你们不要盲目自嗨
- 上海第26届医院后勤院长学术沙龙举行,科技让医院后勤更具温度
- “科技+文化创意”加速文旅融合,腾讯文旅助力河南打造行业新名片
- 未来科技:苹果AR眼镜苹果 Siri可控制眼镜
- 国家点名!互联网大厂们,请当个人
- 健康|华米科技发布国人健康报告 00后睡眠时间最短90后爱晚睡
- 员工|美国科技大公司中罕见成立工会,谷歌:会直接和员工谈