清华大学刘知远:知识指导的自然语言处理( 三 )
 文章插图
文章插图
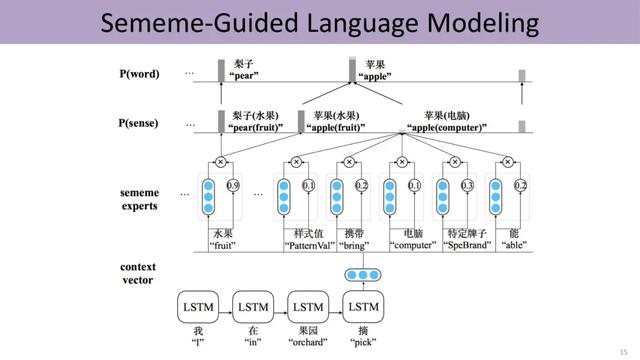
HowNet作为董振东先生一生非常重要的心血 , 已经开源出来供大家免费下载和使用 , 希望更多老师和同学认识到知识库的独特价值 , 并开展相关的工作 。 下面是义原知识相关的阅读列表 。
 文章插图
文章插图
三、世界知识:听懂弦外之音
除了语言上的知识 , 世界知识也是语言所承载的重要信息 。
 文章插图
文章插图
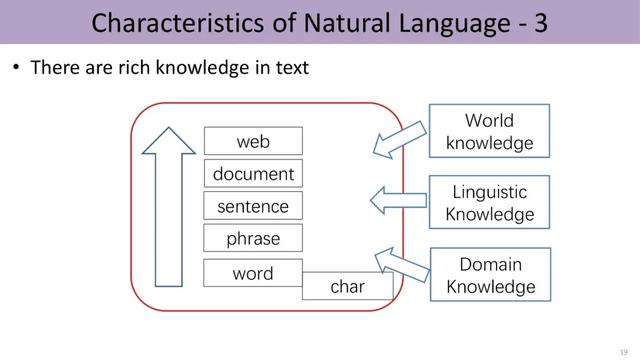
现实世界中有多种多样的实体以及它们之间各种不同的关系 , 比如莎士比亚创作了《罗密欧与朱丽叶》 , 这些世界知识可以构成知识图谱(knowledge graph) 。 在知识图谱中 , 每个节点可以看成一个实体 , 连接它们的边反映了这些实体之间的关系 。 图谱由若干三元组构成 , 每个三元组包括头实体、尾实体以及它们之间的关系 。
 文章插图
文章插图
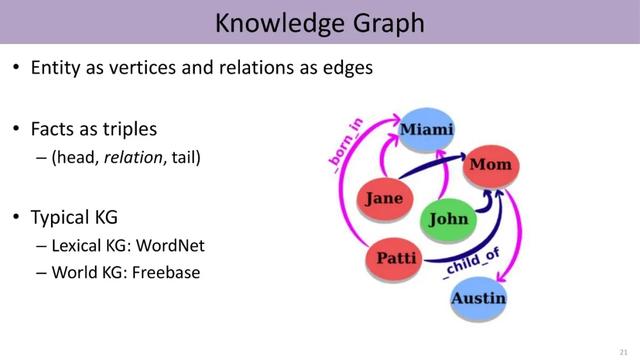
由于知识图谱中的实体隶属不同的类别 , 而且具有不同的连接信息 , 因此我们可以基于knowledge attention这种机制 , 把低维向量的知识表示与文本的上下文表示结合起来 , 进行细粒度实体分类的工作 。
 文章插图
文章插图
另一个方向是两个不同知识图谱的融合问题 , 实为一个典型的entity alignment的问题 , 过去一般要设计一些特别复杂的算法 , 发现两个图谱之间各种各样蛛丝马迹的联系 。 现在实验室提出了一个简单的方法 , 把这两个异质图谱分别进行knowledge embedding , 得到两个不同的空间 , 再利用这两个图谱里面具有一定连接的实体对、也就是构成的种子 , 把这两个图谱的空间结合在一起 。 工作发现 , 该方法能够更好地进行实体的对齐 。
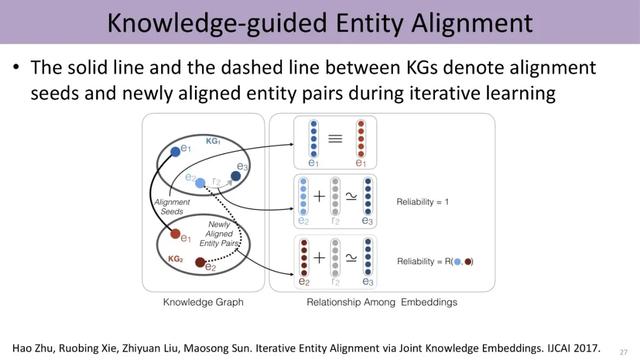 文章插图
文章插图
同时 , 知识也能指导我们进行信息检索 , 计算query和文档之间的相似度 。 除了考虑query和document中词的信息 , 我们可以把实体的信息、以及实体跟词之间的关联形成不同的矩阵 , 从而支持排序模型的训练 。
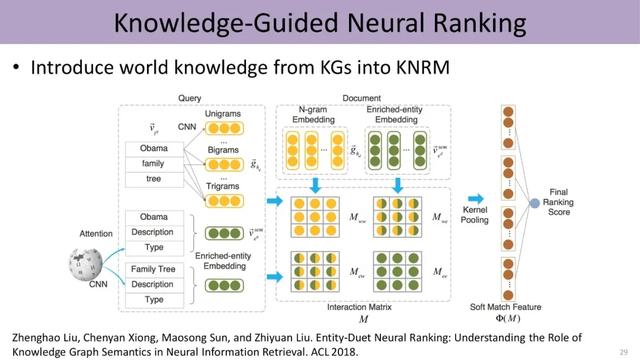 文章插图
文章插图
最后 , 预训练语言模型的诞生 , 把深度学习从原来有监督的数据扩展到了大规模无监督数据 。 事实上 , 这些大规模文本中的每句话 , 都包含大量实体以及它们之间的关系 。 我们理解一句话 , 往往需要外部的世界知识的支持 。
能否把外部知识库加入预训练语言模型呢?2019年 , 刘知远所在的团队提出ERNIE模型 , 使用知识表示算法(transE)将知识图谱中的实体表示为低维的向量 , 并利用一个全新的收集器(aggregator)结构 , 通过前馈网络将词相关的信息与实体相关的信息双向整合到一起 , 完成将结构化知识加入到语言表示模型的目的 。
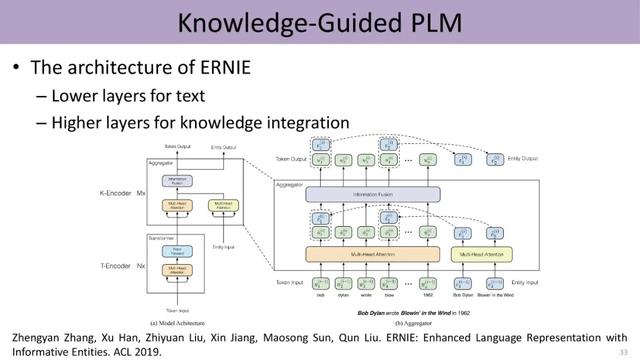 文章插图
文章插图
四、总结
本次报告主要从义原知识和世界知识两个方面 , 阐述了知识指导的自然语言处理相关的工作 。 未来自然语言处理的一个重要方向 , 就是融入人类各种各样的知识 , 从而深入地理解语言 , 读懂言外之意、听出弦外之音 。 针对面向自然语言处理的表示学习 , 刘知远等人也发表了一本专著 , 供大家免费下载研读 。
 文章插图
文章插图
- 华为云知识计算解决方案获首批“知识图谱产品认证证书”
- 企业|技术快速迭代倒逼知识产权“贴身”服务,上海首家AI商标品牌指导站入驻徐汇西岸
- 手机卡顿时,究竟是关机还是重启,这四点差异明显,看完涨知识了
- 原来微信长按2秒这么实用!能开启5个高级功能,涨知识了
- 你不知道的6个微信隐藏功能,个个超实用,学到就是涨知识
- iPhone自带的录音转文字功能,堪称会议记录神器,涨知识了
- 清华大学研究院出手!擦一次,持续24小时防雾,改变眼镜党体验
- 手机定位很简单,打开手机设置,立刻知道对方去过哪里,涨知识了
- 才发现微信隐藏的6个功能,各个都很实用,涨知识了
- 视频|好看视频宣布品牌升级:定位视频知识图谱